Group by
데이터를 그룹으로 묶는 역할 (데이터 그룹화)
문법 : select 필드이름 from 테이블이름
group by 필드이름
데이터를 그룹으로 묶는 이유는? 간편하고 효율적으로 데이터를 검색하기 위해서
예를 들어 현재 user 테이블에서 성씨별로 몇 명의 회원이 있는지 구한다고 가정하자.
select count(distinct(name)) from users;
중복되는 성씨들을 제거하고, 개수를 구한다.

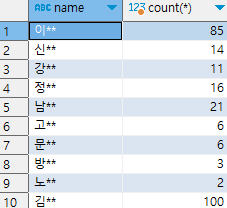
보다시피 현재 성씨의 개수는 54개이다. 즉, 성씨별로 54개의 select문을 사용하여 성씨별로 몇 명의 회원이 있는 지 구해야한다는 것이다.
select * from users
where name = "김**";
select * from users
where name = "이**";
select * from users
where name = "박**";
select * from users
where name = "양**";
.... 등등
이것은 너무 비효율적이다. 이럴 때 쓰는 것이 Group by인 것이다.
select name, count(*) from users
group by name;
코드 설명
- 먼저 내가 사용할 필드인 name을 group by를 사용하여 (중복이 되는)데이터들을 그룹화를 해준다. => group by name
name 필드를 그룹화 해줌으로써 데이터의 중복을 제거 할 수 있다.
- count 사용하여 성씨의 개수를 구해준다. 이때 count는 그룹화가 된 name 필드의 데이터의 개수를 세주는 것이다.
=> select count(*)
- select name, count(*)에서 name을 다시 써주는 이유는 name 필드에 어떤 데이터에 수를 센 것인지 알려주기 위해서이다.
select name, count(*) from users
group by name;
위 코드가 실행되는 순서
from → group by → select
- from users
users 테이블 데이터 전체를 가져온다. - group by name
users 테이블에서 name 필드에 있는 데이터들을 그룹화 해준다. - select name, count(*)
각각의 name 필드에 따라 그룹화가 된 데이터가 각각 몇 개가 센다.
집계함수
여러 개의 데이터들로부터 하나의 값을 리턴 받는 것들을 말한다.
1. count
- 개수를 구할 때 사용
- 문법 : select count(필드이름) from 테이블이름
group by 필드이름
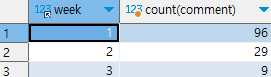
ex) 주차별 "오늘의 다짐"의 개수 구하기
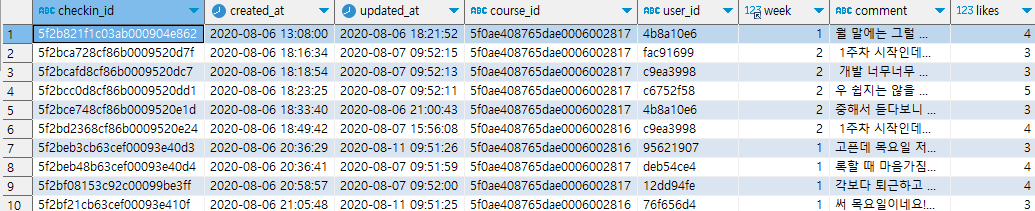
select week, count(comment) from checkins
group by week;
주차별이므로 주차에 해당하는 필드인 week 필드에 group by를 사용하여 그룹화를 해준다.
그 후 "오늘의 다짐"과 관련된 comment 필드에 count를 사용하여 개수를 세준다.
2. min
- 최솟값을 구할 때 사용
- 문법 : select min(필드이름) from 테이블이름
group by 필드이름
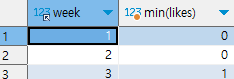
ex) 주차별 '오늘의 다짐'의 좋아요 최솟값 구하기
select week, min(likes) from checkins
group by week
주차별이므로 주차에 해당하는 필드인 week 필드에 group by를 사용하여 그룹화를 해준다.
그 후 좋아요와 관련된 likes 필드에 min을 사용하여 최솟값을 구해준다.
3. max
- 최댓값을 구할 때 사용
- 문법 : select max(필드이름) from 테이블이름
group by 필드이름
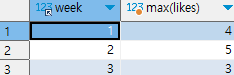
ex) 주차별 '오늘의 다짐'의 좋아요 최댓값 구하기
select week, max(likes) from checkins
group by week
주차별이므로 주차에 해당하는 필드인 week 필드에 group by를 사용하여 그룹화를 해준다.
그 후 좋아요와 관련된 likes 필드에 max를 사용하여 최댓값을 구해준다.
4. avg
- 평균을 구할 때 사용
- 문법 : select avg(필드이름) from 테이블이름
group by 필드이름
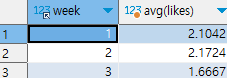
ex) 주차별 '오늘의 다짐'의 좋아요 평균값 구하기
select week, avg(likes) from checkins
group by week
주차별이므로 주차에 해당하는 필드인 week 필드에 group by를 사용하여 그룹화를 해준다.
그 후 좋아요와 관련된 likes 필드에 avg를 사용하여 최댓값을 구해준다.
4-1. round
- 반올림 구할 때 사용
- 문법 : round(값, 반올림 할 자리값)
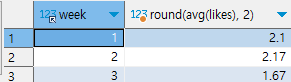
select week, round(avg(likes), 2) from checkins
group by week
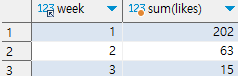
5. sum
- 합계를 구할 때 사용
- 문법 : select sum(필드이름) from 테이블이름
group by 필드이름
ex) 주차별 '오늘의 다짐'의 좋아요 합계 구하기
select week, sum(likes) from checkins
group by week
주차별이므로 주차에 해당하는 필드인 week 필드에 group by를 사용하여 그룹화를 해준다.
그 후 좋아요와 관련된 likes 필드에 sum을 사용하여 합계를 구해준다.