질문, 피드백 등 모든 댓글 환영합니다.
쿼리 개선
지금까진 기능 구현에 초점을 맞추느라 무분별하게 쿼리를 발생시켜왔는데 이를 개선해보겠습니다.
회원 가입 시 중복 ID 조회
기존에는 회원 가입 시 중복인 LoginId가 있는지 조회하기 위해 findByLoginId()로 조회를 했었습니다.
조회된 Member를 사용하지 않고 단순히 값이 있는지 없는지만 확인하면 되기 때문에 existsBy()를 사용하여 값 여부를 조회하겠습니다.
위 방식으로 select exists 쿼리를 생성할 수 있습니다.
MemberRepository
boolean existsByLoginId(String loginId);위의 메서드를 새로 만들어줍니다.
MemberSecurityService
@Override
@Transactional
public Long save(Member member) {
member.setEncodingPassword(bCryptPasswordEncoder.encode(member.getPassword()));
// loginId 중복 체크
return repository.existsByLoginId(member.getLoginId()) ? null : repository.save(member).getId();
}기존의 findByLoginId()를 사용하던 save()를 수정해줍니다.
ToDo 삭제 로직 수정
기존 ToDo 로직은 아래처럼 MemberRepository.delete() 를 사용했었습니다.
ToDoController
@DeleteMapping("/todos/{id}")
public String delete(@PathVariable Long id) {
if (id != null) toDoService.findById(id).ifPresent(toDo -> toDoService.delete(toDo));
return "redirect:/todo";
}member를 먼저 조회하고 삭제하는 방식을 사용했는데 그럴 필요 없이 MemberRepository.deleteById() 를 사용하면 불필요한 select 쿼리를 없앨 수 있습니다. (IntelliJ 자동완성 기능에 너무 심취한 나머지 자동완성된 delete()를 그대로 사용하고 말았네요...)
ToDoController 의 @ModelAttribute
@ModelAttribute를 메서드 단위에 적용하면 해당 컨트롤러에서 요청이 발생하면 메서드가 반환한 값을 Model에 저장해주는 기능을 합니다.
이 예제에선 @ModelAttribute를 이용하여 사용자의 ToDo를 List로 조회하였습니다.
처음 개발할 당시는 @ModelAttribute를 사용하는 방식이 편해서 사용했지만 "/todo" 이하의 경로에서 발생하는 모든 요청에서 불필요한 select 쿼리가 생성되는 문제가 있었습니다. 특히 heroku 무료 버전으로 배포하며 느린 환경에서 성능 이슈를 체감할 수 있었습니다.
때문에 ToDo가 필요한 "/todo" 경로에만 해당 쿼리가 발생하도록 @ModelAttribute를 사용하지 않고 @GetMapping("/todo")에서 처리하도록 수정해보겠습니다. (@ModelAttribute 를 사용하는 방식으로 계속 사용하고 싶다면 필요한 부분만 따로 컨트롤러를 분리하여 사용하셔도 됩니다.)
ToDoController (기존)
@ModelAttribute("toDoDtos")
public List<ToDoDto> toDoDtos(@AuthenticationPrincipal UserDetailsImpl userDetails) {
return getToDoDtos(userDetails.getMember(), false);
}
@ModelAttribute("completedDtos")
public List<ToDoDto> completedDtos(@AuthenticationPrincipal UserDetailsImpl userDetails) {
return getToDoDtos(userDetails.getMember(), true);
}
private List<ToDoDto> getToDoDtos(Member loginMember, Boolean isCompleted) {
List<ToDo> list = toDoService.findSortByMemberIdAndIsCompleted(loginMember.getId(), isCompleted);
return list.stream().map(toDo ->
new ToDoDto(toDo.getId(), toDo.getTitle(), toDo.getDescription(),
toDo.getIsCompleted(), toDo.getCreatedDateTime(), toDo.getDueDate()))
.collect(Collectors.toList());
}
@GetMapping("/todo")
public String todo(@AuthenticationPrincipal UserDetailsImpl userDetails, Model model) {
model.addAttribute("membername", userDetails.getMember().getName());
return "todo/main";
}ToDoController (수정 후)
private List<ToDoDto> getToDoDtos(Member loginMember, Boolean isCompleted) {
List<ToDo> list = toDoService.findSortByMemberIdAndIsCompleted(loginMember.getId(), isCompleted);
return list.stream().map(toDo ->
new ToDoDto(toDo.getId(), toDo.getTitle(), toDo.getDescription(),
toDo.getIsCompleted(), toDo.getCreatedDateTime(), toDo.getDueDate()))
.collect(Collectors.toList());
}
@GetMapping("/todo")
public String todo(@AuthenticationPrincipal UserDetailsImpl userDetails, Model model) {
model.addAttribute("membername", userDetails.getMember().getName());
model.addAttribute("toDoDtos", getToDoDtos(userDetails.getMember(), false));
model.addAttribute("completedDtos", getToDoDtos(userDetails.getMember(), true));
return "todo/main";
}@GetMapping("/todo") 메서드에서 직접 getToDoDtos()을 호출하여 Model에 포함하도록 수정했습니다.
불필요한 Outer Join 개선
먼저 애플리케이션을 실행시켜 "/todo"에 접속했을 때 발생하는 쿼리를 살펴보겠습니다.
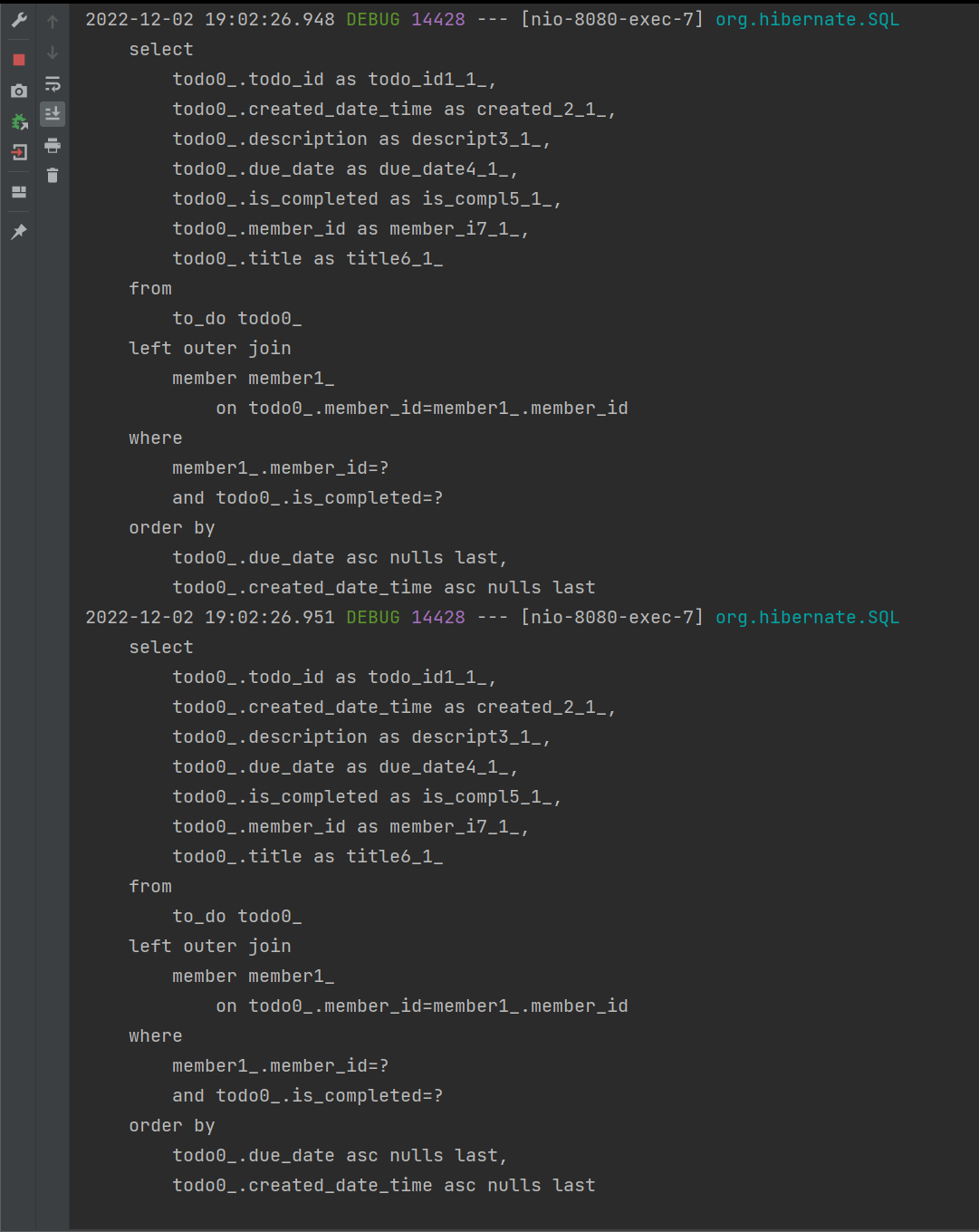
ToDo가 가진 fk인 member_id로 ToDo를 조회하는 과정에서 Member까지 Outer Join이 되는 것을 확인할 수 있습니다.
해당 컨트롤러에서 Member를 사용할 일이 없을 뿐더러 List를 조회하는 과정에서 join을 사용하게 되면 중복 데이터 다발이 조회될 수 있습니다.
자세한 사항은 이전에 작성한 JPA #6 fetch 전략 게시글을 참고해주세요.
하지만 Spring Data JPA가 제공하는 쿼리 메서드(findByMemberId())를 사용하게 될 경우에는 스프링 데이터 JPA의 한계로 강제로 Join이 발생합니다.
때문에 이 케이스의 경우엔 직접 JPQL를 작성해주겠습니다.
스프링 데이터 JPA는 JPQL을 작성하기 쉽도록 @Query 어노테이션을 제공합니다.
ToDoRepository
@Query("select t from ToDo t where t.member.id = :memberId and t.isCompleted = :isCompleted order by t.dueDate nulls last, t.createdDateTime nulls last")
List<ToDo> findJPQLByMemberIdAnAndIsCompleted(@Param("memberId") Long memberId, @Param("isCompleted") Boolean isCompleted);@Query 어노테이션을 사용하여 JQPL을 생성할 수 있습니다.
쿼리 메서드는 파라미터가 많아지면 메서드 이름이 지저분해질 수 있고 특히 컴파일 시점에 sql 문법 오류를 체크할 수 있으므로 @Query는 자주 사용됩니다.
Service와 Controller에도 변경사항을 적용해주겠습니다.
ToDoService (ToDoServiceImpl)
@Override
public List<ToDo> findJPQLByMemberIdAndIsCompleted(Long id, Boolean isCompleted) {
return repository.findJPQLByMemberIdAnAndIsCompleted(id, isCompleted);
}ToDoController
private List<ToDoDto> getToDoDtos(Member loginMember, Boolean isCompleted) {
List<ToDo> list = toDoService.findJPQLByMemberIdAndIsCompleted(loginMember.getId(), isCompleted);
return list.stream().map(toDo ->
new ToDoDto(toDo.getId(), toDo.getTitle(), toDo.getDescription(),
toDo.getIsCompleted(), toDo.getCreatedDateTime(), toDo.getDueDate()))
.collect(Collectors.toList());
}이제 다시 애플리케이션을 실행시켜 어떻게 쿼리가 생성되는지 확인해보겠습니다.

위에서 생성된 쿼리와 달리 Outer Join을 하지 않는 것을 확인할 수 있습니다.
다음으로
헤로쿠 최초 배포 이후 스프링 시큐리티도 적용하고 쿼리 성능도 개선했습니다.
원래는 release branch에 push 만 해주면 배포가 가능하지만
근데 그 사이에... heroku free dyno가 서비스가 종료되었습니다......
다른 둥지를 찾아 나서야 하나 고민이 있었는데 대신 이번에 새로 생긴 eco dyno를 이용하기로 했습니다.
월 5달러로 계정 당 총 1천 시간을 사용할 수 있습니다. (장시간 요청이 없으면 sleep 모드로 바뀌는 건 동일합니다.)
헤로쿠는 github에 등록된 학생 계정이 있으면 무료로 156달러를 지원하니 eco dyno로 다시 배포해보겠습니다.
