내일배움캠프 3주차 회고
3주차 시간표
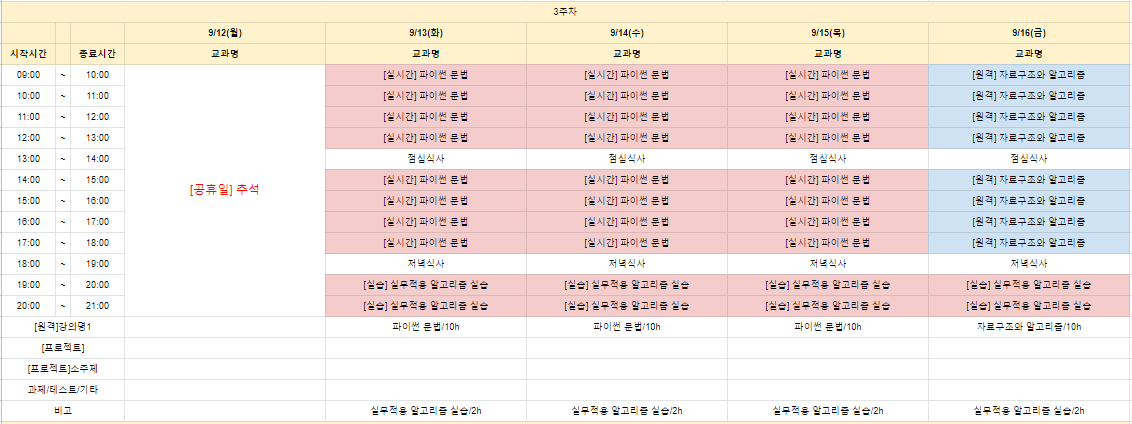
이번 주차는 추석연휴를 끝내고 월요일이 아닌 화요일부터 시작되었다. 이번 주에는 파이썬 문법 실시간 강의 진행 및 과제가 주 학습내용이 되었고 금요일부터는 새로운 원격강의인 자료구조와 알고리즘 원격강의, 그리고 파이썬 거북이반 개설 등이 있었다.
파이썬 문법 실시간강의
-이창호 튜터님
저번 주 부터 진행된 실시간 파이썬 강의가 이번 주로 끝이 났다. 튜터님이 워낙 설명을 잘 해주신 덕분에 개념이 정립은 되었지만 그 개념을 활용하는데 있어서는 아직 미숙한 점이 많은 것 같아서 실제로 코드를 작성하며 파이썬 문법에 익숙해지는 시간이 필요할 것 같다.
class에 대한 이해
class란?
- 클래스를 선언하는것은 과자 틀을 만드는 것이고, 선언된 과자틀(class)로
과자(instance)를 만든다고 생각하면 된다. - 선언 후 바로 사용되는 함수와 다르게 클래스는 인스턴스를 생성하여 사용하게 된다.
- class 내부에 선언되는 메소드는 기본적으로 self라는 인자를 가지고 있다.
- self는 클래스 내에서 전역 변수와 같이 사용된다.
용어 정리
- 인스턴스(instance) : class를 사용해 생성된 객체
- 메소드(method) : 메소드란 클래스 내에 선언된 함수이며, 클래스 함수라고도 한다.
- self : 메소드를 선언할 때에는 항상 첫번째 인자로 self를 넣어줘야 한다.
클래스 안에 있는 변수나 함수 정보를 담고 있다.- class의 기본 구조
class CookieFrame(): # CookieFrame이라는 이름의 class 선언 def set_cookie_name(self, name): self.name = name cookie1 = CookieFrame() cookie2 = CookieFrame() cookie1.set_cookie_name("cookie1") # 메소드의 첫 번째 인자 self는 무시된다. cookie2.set_cookie_name("cookie2") print(cookie1.name) # cookie1 print(cookie2.name) # cookie2 __init__함수# class에 __init__메소드를 사용할 경우 인스턴스 생성 시 해당 메소드가 실행된다. class CookieFrame(): def __init__(self, name): print(f"생성 된 과자의 이름은 {name} 입니다!") self.name = name cookie1 = CookieFrame("cookie1") # 생성 된 과자의 이름은 cookie1 입니다! cookie2 = CookieFrame("cookie2") # 생성 된 과자의 이름은 cookie2 입니다!
mutable 자료형과 immutable 자료형
- mutable과 immutable이란?
muteble은 값이 변한다는 의미이며, immutable은 값이 변하지 않는다는 의미이다. int, str, list 등 자료형은 각각 muteble 혹은 immuteble한 속성을 가지고 있다. a = 10 b = a b += 5 와 같은 코드가 있을 때 a에 담긴 자료형이 muteble 속성인지 immuteble 속성인지에 따라 출력했을 때 결과가 달라지게 된다. - immutable 속성을 가진 자료형
- int, float, str, tuple
- mutable 속성을 가진 자료형
- list, dict
- 코드에서 mutable과 immutable의 차이 비교해보기
immutable = "String is immutable!!" mutable = ["list is mutable!!"] string = immutable list_ = mutable string += " immutable string!!" list_.append("mutable list!!") print(immutable) print(mutable) print(string) print(list_) # result print """ String is immutable!! ['list is mutable!!', 'mutable list!!'] String is immutable!! immutable string!! ['list is mutable!!', 'mutable list!!'] """
4. Python 심화
try / exception을 활용한 에러 처리
- python에서는 try / except 문법을 사용해 에러가 발생했을 때 처리를 해줄수 있습니다.
number = "num" try: # try 구문 안에서 에러가 발생할 경우 except로 넘어감 number = int(number) # "num"을 숫자로 바꾸는 과정에서 에러 발생 except: # 에러가 발생했을 때 처리 print(f"{number}은(는) 숫자가 아닙니다.") - 에러 종류에 따라 다른 로직 처리
number = input() try: int(number) 10 / number except ValueError: # int로 변환하는 과정에서 에러가 발생했을 떄 print(f"{number}은(는) 숫자가 아닙니다.") except ZeroDivisionError: # 0으로 나누면서 에러가 발생했을 때 print("0으로는 나눌수 없습니다.") except Exception as e: # 위에서 정의하지 않은 에러가 발생했을 때(권장하지 않음) print(f"예상하지 못한 에러가 발생했습니다. error : {e}") # except 문법 또한 if / elif와 같이 연달아서 작성할 수 있습니다.
stacktrace의 이해
- stacktrace란?
stacktrace는 python 뿐만이 아닌 대부분의 개발 언어에서 사용되는 개념이다.
에러가 발생했을 때 에러가 발생 한 위치를 찾아내기 위해 호출 된 함수의 목록을 보여주고 개발자는 stacktrace를 따라가며 에러가 발생한 위치를 추적할 수 있다.
- 예제 코드 보기
def 집까지_걸어가기(): print(error) # 선언되지 않은 변수를 호출했기 때문에 에러 발생 def 버스_탑승(): 집까지_걸어가기() def 환승(): 버스_탑승() def 지하철_탑승(): 환승() def 퇴근하기(): 지하철_탑승() 퇴근하기() """ Traceback (most recent call last): File "sample.py", line 17, in <module> 퇴근하기() File "sample.py", line 15, in 퇴근하기 지하철_탑승() File "sample.py", line 12, in 지하철_탑승 환승() File "sample.py", line 9, in 환승 버스_탑승() File "sample.py", line 5, in 버스_탑승 집까지_걸어가기() File "sample.py", line 2, in 집까지_걸어가기 print(error) NameError: name 'error' is not defined. Did you mean: 'OSError'? """
축약식(Comprehension)
- 축약식이란?
축약식은 긴 코드를 간략하게 줄일수 있다는 장점이 있지만, 남용할 경우 가독성이 떨어지고 추후 코드 관리가 힘들수 있기 때문에 필요할 때만 사용하는 것을 권장합니다. list, set, tuple, dict 자료형이 축약식을 지원합니다. 기본적인 구조는 똑같으며, 어떤 괄호 기호를 사용하는지 / 어떤 형태로 사용하는지에 따라 저장되는 자료형이 달라집니다. 축약식은 모두 동일한 구조를 가지고 있기 때문에 한 가지 자료형에 익숙해지면 다른 자료형에도 적용해서 사용할 수 있습니다. - list / tuple / set 축약식 활용법
# 기본적인 활용 방법 # [list에 담길 값 for 요소 in 리스트] numbers = [x for x in range(5)] # [0, 1, 2, 3, 4] # 조건문은 축약식 뒷부분에 작성하며, 축약식이 True인 경우 list에 값이 담긴다. even_numbers = [x for x in range(10) if x % 2 == 0] # [0, 2, 4, 6, 8] # 아래와 같이 활용할 수도 있다. people = [ ("lee", 32), ("kim", 23), ("park", 27), ("hong", 29), ("kang", 26) ] average_age = sum([x[1] for x in people]) / len(people) print(average_age) # 27.4 #list 축약식의 []를 ()혹은 {}로 바꿔주면 tuple, set 축약식을 사용하실수 있습니다. - dictionary 축약식 활용법
# dictionary 축약식의 구조는 list와 동일하지만, key / value 형태로 지정해야 합니다. people = [ ("lee", 32, "man"), ("kim", 23, "man"), ("park", 27, "woman"), ("hong", 29, "man"), ("kang", 26, "woman") ] people = {name: {"age": age, "gender": gender} for name, age, gender in people} print(people) # result print """ { 'lee': {'age': 32, 'gender': 'man'}, 'kim': {'age': 23, 'gender': 'man'}, 'park': {'age': 27, 'gender': 'woman'}, 'hong': {'age': 29, 'gender': 'man'}, 'kang': {'age': 26, 'gender': 'woman'} } """
lambda / map / filter / sort 활용하기
- lambda 함수란?
python에서 lambda 함수는 다른 말로 익명 함수(anonymous function)라고도 불립니다. lambda 함수는 주로 map / filter / sort 함수와 함께 사용됩니다. - map 함수 활용해보기
# map은 함수와 리스트를 인자로 받아 리스트의 요소들로 함수를 호출해줍니다. string_numbers = ["1", "2", "3"] integer_numbers = list(map(int, string_numbers)) print(integer_numbers) # [1, 2, 3] # map 함수를 사용하지 않는 경우 아래와 같이 구현할 수 있습니다. string_numbers = ["1", "2", "3"] integer_numbers = [] for i in string_numbers: integer_numbers.append(int(i)) print(integer_numbers) # [1, 2, 3] # list 축약식으로도 동일한 기능을 구현할 수 있습니다. # map과 list 축약식 중 어떤걸 써야 할지 고민된다면 [이 글](https://stackoverflow.com/questions/1247486/list-comprehension-vs-map?answertab=scoredesc#tab-top)을 읽어보시는것을 추천합니다. string_numbers = ["1", "2", "3"] integer_numbers = [int(x) for x in string_numbers] print(integer_numbers) # [1, 2, 3] # map 함수와 lambda 함수를 함께 사용하면 더 다채로운 기능을 구현할 수 있습니다. numbers = [1, 2, 3, 4] double_numbers = list(map(lambda x: x*2, numbers)) print(double_numbers) # [2, 4, 6, 8] - filter 함수 활용해보기
# filter 함수는 map과 유사한 구조를 가지고 있으며, 조건이 참인 경우 저장합니다. numbers = [1, 2, 3, 4, 5, 6, 7, 8] even_numbers = list(filter(lambda x: x%2 == 0, numbers)) print(even_numbers) # [2, 4, 6, 8] # filter 함수 또한 list 축약식으로 동일한 기능을 구현할 수 있습니다. numbers = [1, 2, 3, 4, 5, 6, 7, 8] even_numbers = [x for x in numbers if x%2 == 0] print(even_numbers) # [2, 4, 6, 8] - sort 함수 활용해보기
# sort 함수를 사용하면 list를 순서대로 정렬할 수 있습니다. numbers = [5, 3, 2, 4, 6, 1] numbers.sort() print(numbers) # [1, 2, 3, 4, 5, 6] # sort와 lambda 함수를 같이 사용하면 복잡한 구조의 list도 정렬할 수 있습니다. people = [ ("lee", 32), ("kim", 23), ("park", 27), ("hong", 29), ("kang", 26) ] # 나이 순으로 정렬하기 people.sort(key=lambda x: x[1]) print(people) # result print """ [ ("kim", 23), ("kang", 26), ("park", 27), ("hong", 29), ("lee", 32) ]
함수 심화
- 인자에 기본값 지정해주기
# 함수를 선언할 때 인자에 기본값을 지정해줄 수 있다. EXPRESSION = { 0: lambda x, y: x + y , 1: lambda x, y: x - y , 2: lambda x, y: x * y , 3: lambda x, y: x / y } def calc(num1, num2, option=None): # 인자로 option이 들어오지 않는 경우 기본값 할당 """ option - 0: 더하기 - 1: 빼기 - 2: 곱하기 - 3: 나누기 """ return EXPRESSION[option](num1, num2) if option in EXPRESSION.keys() else False print(calc(10, 20)) # False print(calc(10, 20, 0)) # 30 print(calc(10, 20, 1)) # -10 print(calc(10, 20, 2)) # 200 print(calc(10, 20, 3)) # 0.5 - args / kwargs에 대한 이해
args(arguments)와 keyword arguments(kwargs)는 함수에서 인자로 받을 값들의 갯수가 불규칙하거나 많을 때 주로 사용된다. 인자로 받을 값이 정해져있지 않기 때문에 함수를 더 동적으로 사용할 수 있다. 함수를 선언할 때 args는 앞에 *를 붙여 명시하고, kwargs는 앞에 **를 붙여 명시한다.- args 활용하기
def add(*args): # args = (1, 2, 3, 4) result = 0 for i in args: result += i return result print(add()) # 0 print(add(1, 2, 3)) # 6 print(add(1, 2, 3, 4)) # 10 - kwargs 활용하기
def set_profile(**kwargs): """ kwargs = { name: "lee", gender: "man", age: 32, birthday: "01/01", email: "python@sparta.com" } """ profile = {} profile["name"] = kwargs.get("name", "-") profile["gender"] = kwargs.get("gender", "-") profile["birthday"] = kwargs.get("birthday", "-") profile["age"] = kwargs.get("age", "-") profile["phone"] = kwargs.get("phone", "-") profile["email"] = kwargs.get("email", "-") return profile profile = set_profile( name="lee", gender="man", age=32, birthday="01/01", email="python@sparta.com", ) print(profile) # result print """ { 'name': 'lee', 'gender': 'man', 'birthday': '01/01', 'age': 32, 'phone': '-', 'email': 'python@sparta.com' } """ - args / kwargs 같이 사용해보기
def print_arguments(a, b, *args, **kwargs): print(a) print(b) print(args) print(kwargs) print_arguments( 1, # a 2, # b 3, 4, 5, 6, # args hello="world", keyword="argument" # kwargs ) # result print """ 1 2 (3, 4, 5, 6) {'hello': 'hello', 'world': 'world'} """
- args 활용하기
패킹과 언패킹
- 패킹과 언패킹이란?
패킹(packing)과 언패킹(unpacking)은 단어의 뜻 그대로 요소들을 묶어주거나 풀어주는 것을 의미한다. list 혹은 dictionary의 값을 함수에 입력할 때 주로 사용된다. - list에서의 활용
def add(*args): result = 0 for i in args: result += i return result numbers = [1, 2, 3, 4] print(add(*numbers)) # 10 """아래 코드와 동일 print(add(1, 2, 3, 4)) """ - dictionary에서의 활용
def set_profile(**kwargs): profile = {} profile["name"] = kwargs.get("name", "-") profile["gender"] = kwargs.get("gender", "-") profile["birthday"] = kwargs.get("birthday", "-") profile["age"] = kwargs.get("age", "-") profile["phone"] = kwargs.get("phone", "-") profile["email"] = kwargs.get("email", "-") return profile user_profile = { "name": "lee", "gender": "man", "age": 32, "birthday": "01/01", "email": "python@sparta.com", } print(set_profile(**user_profile)) """ 아래 코드와 동일 profile = set_profile( name="lee", gender="man", age=32, birthday="01/01", email="python@sparta.com", ) """ # result print """ { 'name': 'lee', 'gender': 'man', 'birthday': '01/01', 'age': 32, 'phone': '-', 'email': 'python@sparta.com' } """
객체지향
- 객체지향(Object-Oriented Programming)이란??
객체지향이란 객체를 모델링하는 방향으로 코드를 작성하는 것을 의미한다. 영어로는 Object-Oriented Programming이라고 하며 앞자를 따 OOP라고 불린다. 파이썬 뿐만이 아닌, 다양한 언어들에서 프로젝트를 개발하며 사용되는 개발 방식 중 하나다. - 객체지향의 특성
- 캡슐화
- 특정 데이터의 액세스를 제한해 데이터가 직접적으로 수정되는 것을 방지하며, 검증 된 데이터만을 사용할 수 있다.
- 추상화
- 사용되는 객체의 특성 중, 필요한 부분만 사용하고 필요하지 않은 부분은 제거하는 것을 의미한다.
- 상속
- 상속은 기존에 작성 된 클래스의 내용을 수정하지 않고 그대로 사용하기 위해 사용되는 방식이다.
- 클래스를 선언할 때 상속받을 클래스를 지정할 수 있다.
- 다형성
- 하나의 객체가 다른 여러 객체로 재구성되는 것을 의미한다.
- 오버라이드, 오버로드가 다향성을 나타내는 대표적인 예시이다.
- 캡슐화
- 객체지향의 장/단점
- 장점
- 클래스의 상속을 활용하기 때문에 코드의 재사용성이 높아진다.
- 데이터를 검증하는 과정이 있기 때문에 신뢰도가 높다.
- 모델링을 하기 수월하다.
- 보안성이 높다.
- 단점
- 난이도가 높다.
- 코드의 실행 속도가 비교적 느린 편이다.
- 객체의 역활과 기능을 정의하고 이해해야 하기 때문에 개발 속도가 느려진다.
- 장점
- 객체지향 예제 코드
import re # 숫자, 알파벳으로 시작하고 중간에 - 혹은 _가 포함될 수 있으며 숫자, 알파벳으로 끝나야 한다. # @ # 알파벳, 숫자로 시작해야 하며 . 뒤에 2자의 알파벳이 와야 한다. email_regex = re.compile(r'([A-Za-z0-9]+[.-_])*[A-Za-z0-9]+@[A-Za-z0-9-]+(\.[A-Z|a-z]{2,})+') class Attendance: count = 0 def attendance(self): self.count += 1 @property def attendance_count(self): return self.count class Profile(Attendance): def __init__(self, name, age, email): self.__name = name # __를 붙여주면 class 내부에서만 사용하겠다는 뜻 self.__age = age self.__email = email @property # 읽기 전용 속성 def name(self): return self.__name @name.setter # 쓰기 전용 속성 def name(self, name): if isinstance(name, str) and len(name) >= 2: print("이름은 2자 이상 문자만 입력 가능합니다.") else: self.__name = name @property def age(self): return self.__age @age.setter def age(self, age): if isinstance(age, int): self.__age = age else: print("나이에는 숫자만 입력 가능합니다.") @property def email(self): return self.__email @email.setter def email(self, email): if re.fullmatch(email_regex, email): self.__email = email else: print("유효하지 않은 이메일입니다.") def attendance(self): # override super().attendance() # 부모 메소드 사용하기 self.count += 1 def __str__(self): return f"{self.__name} / {self.__age}" def __repr__(self): return f"{self.__name}"
위와 같은 내용들로 파이썬 실시간 강의는 끝이 났다. 앞에도 말했지만 실전에서의 활용이 문제가 되지 개념 이해자체는 객체지향을 제외하면 어느정도 끝이 난 상태이고 객체지향은 지금 당장 완벽하게 이해를 하고 지나가기엔 시간이 너무 많이 들 것 같아 어쩔 수 없이 지금은 이해하는 것을 포기하고 다음에 기회가 된다면 확실하게 짚고 넘어갈 수 있다면 좋을 것 같다는 생각이 든다.
파이썬 이번 주의 과제
클래스 활용해보기, 파이썬 심화문법 사용해보기, 조건문과 반복문
1. 도형 넓이 계산기
요구조건
- 인스턴스를 선언할 때 가로, 세로 길이를 받을 수 있는 클래스를 선언해 주세요
- 인스턴스에서 사각형, 삼각형, 원의 넓이를 구하는 메소드를 생성해주세요
- 원의 넓이를 계산할 때는 세로 길이는 무시하고, 가로 길이를 원의 지름이라 가정하고 계산해 주세요
- 입출력 예제
area = Area(10, 20) print(area.square()) # 사각형의 넓이 print(area.triangle()) # 삼각형의 넓이 print(area.circle()) # 원의 넓이
코드작성시작!
class Area():
def __init__(self, width, height):
self.width = width
self.height = height
def square(self, width, height):
return width * height
def triangle(self, width, height):
return width * height /2
def circle(width, height):
return (width / 2) ** 2 * 3.14
area = Area(10, 20)
print(area.square())
print(area.triangle())
print(area.circle())클래스를 활용하는 과제니까 먼저 클래스 선언부터 해 주었다. 입력값이 Area(10, 20)이기 때문에 클래스 이름도 Area()로 하고 __init__ 함수를 이용해 받아온 값을 각각 width와 height라고 선언해 두었다. 그리고 도형 계산식을 만들었는데 초등학생때의 기억을 되새겨 사각형, 삼각형, 원의 계산식을 따와서 메소드 생성을 하고 area에 Area(10, 20)의 값을 준 뒤 각 도형 계산식에 대입하면 끝! 인줄 알았는데 예상치 못한 오류가 발생하였다. Line13에서 오류가 발생하였는데 그말은 즉 area.square()함수가 가로와 세로의 값을 받아오지 못한다는 말이었다. 그래서 함수의 계산식도 바꿔보고 __init__함수도 재설정 해보고 내가 아는 선에서는 모든 해결법을 총 동원해보고 혹시 몰라 구글링까지 해봤지만 구글에도 평범한 도형계산식만 있지 class를 활용한 케이스는 없는 것 같아 결국 튜터님을 찾아가 질문해보았고 늘 그렇듯 해답은 간단한 것이었다.
class Area():
def __init__(self, width, height):
self.width = width
self.height = height
def square(self):
return self.width * self.height
def triangle(self):
return self.width * self.height /2
def circle(self):
return (self.width / 2) ** 2 * 3.14
area = Area(10, 20)
print(area.square())
print(area.triangle())
print(area.circle())이미 __init__함수를 통해 width와 height값을 받아왔는데 도형계산식에서 또다시 width와 height값을 받아오려고 했기 때문에 해당 값을 받아올 곳이 없었던 것이었다. 결국 도형 계산식에 요구되는 width와 height를 모두 없애고 대신 self.width와 self.height를 받아와 계산하도록 하니까 답은 쉽게 나왔다.
풀고보니 굉장히 쉽고 황당한 실수지만 막상 막히는 상황이 오니 해결책을 찾는데 눈앞이 깜깜한것을 직접 느꼈다. 하지만 초보이기 때문에 충분히 할 수 있는 실수이고 오히려 실수를 한 번 했으니 앞으로 이런 일이 발생하게 되면 당황하지 않고 해결할 수 있을테니 오히려 좋다고 생각하겠다.
2. 계산기 만들어보기(with class)
요구조건
- 설정한 숫자를 계산해줄 클래스를 선언해주세요
- 메소드를 호출해서 num1, num2를 설정할 수 있도록 해주세요
- 입력된 숫자의 더하기, 빼기, 곱하기, 나누기 연산 결과를 구하는 메소드를 생성해주세요
- 입출력 예제
calc = Calc() clac.set_number(20, 10) print(calc.plus()) # 더한 값 print(calc.minus()) # 뺀 값 print(calc.multiple()) # 곱한 값 print(calc.divide()) # 나눈 값
코드작성시작!
class Calc():
def set_number(self, num1, num2):
self.num1 = num1
self.num2 = num2
def plus(self):
return self.num1 + self.num2
def minus(self):
return self.num1 - self.num2
def multiple(self):
return self.num1 * self.num2
def divide(self):
if self.num2 == 0:
print("0으로는 나눌 수 없습니다!")
else:
return self.num1 / self.num2
calc = Calc()
calc.set_number(20,10)
print(calc.plus())
print(calc.minus())
print(calc.multiple())
print(calc.divide())계산기 만들기는 이미 한번 해봤기 때문에 오히려 1번보다 하기 쉬웠다. 1번에서 실수도 한번 저질렀으니 같은 실수를 반복하지만 않으면 너무 수월하게 해결되는 과제였다.
3. 프로필 관리 기능 만들어보기
요구조건
- 사용자들의 프로필을 관리할 수 있는 클래스를 선언해주세요
- 메소드를 호출해서 사용자의 프로필을 설정할 수 있도록 해주세요
- 사용자의 정보를 각각 출력할 수 있는 메소드를 만들어주세요
- 입출력 예제
profile = Profile() profile.set_profile({ "name": "lee", "gender": "man", "birthday": "01/01", "age": 32, "phone": "01012341234", "email": "python@sparta.com", }) print(profile.get_name()) # 이름 출력 print(profile.get_gender()) # 성별 출력 print(profile.get_birthday()) # 생일 출력 print(profile.get_age()) # 나이 출력 print(profile.get_phone()) # 핸드폰번호 출력 print(profile.email()) # 이메일 출력
코드작성시작!
class Profile():
def __init__(self):
self.profile = {
"name": "-",
"gender": "-",
"birthday": "-",
"age": "-",
"phone": "-",
"email": "-"
}
def set_profile(self, profile):
self.profile = profile
def get_name(self):
return self.profile["name"]
def get_gender(self):
return self.profile["gender"]
def get_birthday(self):
return self.profile["birthday"]
def get_age(self):
return self.profile["age"]
def get_phone(self):
return self.profile["phone"]
def get_email(self):
return self.profile["email"]
profile = Profile()
profile.set_profile({
"name": "lee",
"gender": "man",
"birthday": "01/01",
"age": 32,
"phone": "01012341234",
"email": "python@sparta.com",
})
print(profile.get_name()) # 이름 출력
print(profile.get_gender()) # 성별 출력
print(profile.get_birthday()) # 생일 출력
print(profile.get_age()) # 나이 출력
print(profile.get_phone()) # 핸드폰번호 출력
print(profile.get_email()) # 이메일 출력어디서 많이 본 듯 한 내용이었는데 역시 오늘 강의 class 활용해보기의 내용과 거의 같은 문제였다. 다른점이 있다면 getprofile을 통해 프로필을 통째로 불러오는 것이 아니라 프로필 dictionary 안에 있는 각 key값들을 하나 하나 꺼내오게 한다는 점이 다른 점이었다. class 활용해보기에서 사용된 코드를 그대로 가져와 붙여넣고 조금만 수정하면 매우 쉬운 과제이지만 그렇게 하면 과제를 하는 의미가 없으니 처음부터 직접 코드를 다시 다 만들었다. 대신 get_profile로 한번에 정보를 가져오는 것이 아니라 'get가져올key값' 으로 하나씩만 가져왔는데 이 때 return값을 새로 받아올 때 전에 배웠던 ["key"]를 통해 dictionary에서 key에 해당하는 value 값만 가져오도록 설정해주었다.
1. 계산기 심화
요구조건
- 클래스를 활용해 작성했던 계산기 코드를 활용해주세요
- 기존처럼 사용자의 입력을 받고 출력하되, try / except를 활용해 사용자의 입력을 검증하는 코드를 추가해주세요
- 두 번쨰 숫자에 0을 입력하고 나누기를 시도할 경우 “0으로 나눌 수 없습니다” 문구를 출력해주세요
- 숫자가 아닌 다른 값을 입력했을 경우 “숫자만 입력 가능합니다” 라는 문구를 출력해 주세요
- 입출력 예제
calc = Calc() clac.set_number(20, 10) print(calc.plus()) # 더한 값 print(calc.minus()) # 뺀 값 print(calc.multiple()) # 곱한 값 print(calc.divide()) # 나눈 값
바로 어제 만든 계산기에서 try / except를 사용하는 코드 몇 가지만 추가하면 되는 간단한 과제였다. 원래 만든 계산기에서도 if문을 이용하여 0으로 나누면 오류알림이 뜨도록 설정해 두었기 때문에 금방 고칠 수 있었다.
class Calc():
def set_number(self, num1, num2):
self.num1 = num1
self.num2 = num2
def plus(self):
return self.num1 + self.num2
def minus(self):
return self.num1 - self.num2
def multiple(self):
return self.num1 * self.num2
def divide(self):
if self.num2 == 0:
print("0으로는 나눌 수 없습니다!")
else:
return self.num1 / self.num2
calc = Calc()
calc.set_number(20,10)
print(calc.plus())
print(calc.minus())
print(calc.multiple())
print(calc.divide())원래 만들었던 계산기의 코드이고 계산 함수 부분을 try, except 구문을 이용하도록 수정하였다.
class Calc():
def set_number(self, num1, num2):
self.num1 = num1
self.num2 = num2
def plus(self):
try:
return self.num1 + self.num2
except ValueError:
print("숫자만 입력 가능합니다.")
def minus(self):
try:
return self.num1 - self.num2
except ValueError:
print("숫자만 입력 가능합니다.")
def multiple(self):
try:
return self.num1 * self.num2
except ValueError:
print("숫자만 입력 가능합니다.")
def divide(self):
try:
return int(self.num1) / int(self.num2)
except ValueError:
print("숫자만 입력 가능합니다.")
except ZeroDivisionError:
print("0으로는 나눌 수 없습니다.")
calc = Calc()
calc.set_number(20, 0)
print(calc.plus()) # 더한 값
print(calc.minus()) # 뺀 값
print(calc.multiple()) # 곱한 값
print(calc.divide()) # 나눈 값이렇게 수정했더니 0으로 나누었을때 print가 두번 적용되는 문제점이 발생했다.
class Calc():
def set_number(self, num1, num2):
self.num1 = num1
self.num2 = num2
def plus(self):
try:
return self.num1 + self.num2
except ValueError:
return "숫자만 입력 가능합니다."
def minus(self):
try:
return self.num1 - self.num2
except ValueError:
return "숫자만 입력 가능합니다."
def multiple(self):
try:
return self.num1 * self.num2
except ValueError:
return "숫자만 입력 가능합니다."
def divide(self):
try:
return int(self.num1) / int(self.num2)
except ValueError:
return "숫자만 입력 가능합니다."
except ZeroDivisionError:
return "0으로는 나눌 수 없습니다."
calc = Calc()
calc.set_number(20, 0)
print(calc.plus()) # 더한 값
print(calc.minus()) # 뺀 값
print(calc.multiple()) # 곱한 값
print(calc.divide()) # 나눈 값위와 같이 print()대신 return을 사용하여 중복현상을 방지해서 최종수정이 완료되었다.
2. 리스트 필터 및 정렬
요구조건
- filter 혹은 리스트 축약식을 사용해 코드를 작성해주세요
- 제공 된 사용자들 중 나이가 20살 미만인 사람들은 제외해주세요
- 사용자들을 나이 순으로 정렬해주세요
- 입출력 예제
people = [ ("Blake Howell", "Jamaica", 18, "aw@jul.bw"), ("Peter Bowen", "Burundi", 30, "vinaf@rilkov.il"), ("Winnie Hall", "Palestinian Territories", 22, "moci@pacivhe.net"), ("Alfred Schwartz", "Syria", 29, "ic@tolseuc.pr"), ("Carrie Palmer", "Mauritius", 28, "fenlofi@tor.aq"), ("Rose Tyler", "Martinique", 17, "as@forebjab.et"), ("Katharine Little", "Anguilla", 29, "am@kifez.et"), ("Brent Peterson", "Svalbard & Jan Mayen", 22, "le@wekciga.lr"), ("Lydia Thornton", "Puerto Rico", 19, "lefvoru@itbewuk.at"), ("Richard Newton", "Pitcairn Islands", 17, "da@lasowiwa.su"), ("Eric Townsend", "Svalbard & Jan Mayen", 22, "jijer@cipzo.gp"), ("Trevor Hines", "Dominican Republic", 15, "ev@hivew.tm"), ("Inez Little", "Namibia", 26, "meewi@mirha.ye"), ("Lloyd Aguilar", "Swaziland", 16, "oza@emneme.bb"), ("Erik Lane", "Turkey", 30, "efumazza@va.hn"), ] # some code print(people) """ [('Winnie Hall', 'Palestinian Territories', 22, 'moci@pacivhe.net'), ('Brent Peterson', 'Svalbard & Jan Mayen', 22, 'le@wekciga.lr'), ('Eric Townsend', 'Svalbard & Jan Mayen', 22, 'jijer@cipzo.gp'), ('Inez Little', 'Namibia', 26, 'meewi@mirha.ye'), ('Carrie Palmer', 'Mauritius', 28, 'fenlofi@tor.aq'), ('Alfred Schwartz', 'Syria', 29, 'ic@tolseuc.pr'), ('Katharine Little', 'Anguilla', 29, 'am@kifez.et'), ('Peter Bowen', 'Burundi', 30, 'vinaf@rilkov.il'), ('Erik Lane', 'Turkey', 30, 'efumazza@va.hn')] """
답안코드
people = [
("Blake Howell", "Jamaica", 18, "aw@jul.bw"),
("Peter Bowen", "Burundi", 30, "vinaf@rilkov.il"),
("Winnie Hall", "Palestinian Territories", 22, "moci@pacivhe.net"),
("Alfred Schwartz", "Syria", 29, "ic@tolseuc.pr"),
("Carrie Palmer", "Mauritius", 28, "fenlofi@tor.aq"),
("Rose Tyler", "Martinique", 17, "as@forebjab.et"),
("Katharine Little", "Anguilla", 29, "am@kifez.et"),
("Brent Peterson", "Svalbard & Jan Mayen", 22, "le@wekciga.lr"),
("Lydia Thornton", "Puerto Rico", 19, "lefvoru@itbewuk.at"),
("Richard Newton", "Pitcairn Islands", 17, "da@lasowiwa.su"),
("Eric Townsend", "Svalbard & Jan Mayen", 22, "jijer@cipzo.gp"),
("Trevor Hines", "Dominican Republic", 15, "ev@hivew.tm"),
("Inez Little", "Namibia", 26, "meewi@mirha.ye"),
("Lloyd Aguilar", "Swaziland", 16, "oza@emneme.bb"),
("Erik Lane", "Turkey", 30, "efumazza@va.hn"),
]
people = [x for x in people if x[2] >= 20]
people.sort(key=lambda x : x[2])
print(people)people 안에서 나이는 2번 인덱스값이므로 x[2]가 사용자의 나이가 된다. 우선 리스트 축약식을 활용하여 나이가 20세 미만인 사람들을 값에서 제외하고 그 다음줄에서 .sort를 사용하여 나이순으로 people내의 사용자들을 정렬하였다. 굉장히 쉬운 코드이지만 리스트 축약식과 .sort를 둘 다 적용시키는 방법을 몰라서 코드를 굉장히 많이 수정했고 수많은 시행착오 끝에 두 번에 걸쳐 코드를 따로 적용시키는 것이 답이라는걸 알게 되었다. 아니면 단순히 실력이 부족해 이 두 가지를 한줄로 정리하는 방법이 있는데 내가 알지 못할 뿐일 수도 있겠다. 하지만 그래도 시간은 좀 오래걸려도 혼자서 과제를 해결한 것이 기쁘므로 지금은 그냥 넘어가겠다.
1. 조건문
요구조건
- 사용자의 시험 점수를 입력받아 등급을 출력하는 코드를 만들어주세요
- 등급표
- 91~100 : A
- 81~90 : B
- 71~80 : C
- ~71 : F
- 등급표
- 입출력 예제
def get_grade(score): # some code score = int(input()) grade = get_grade(score) print(grade) # A ~ F
코드작성시작
def get_grade(score):
if 100>= score > 90:
return "A"
elif 90 >= score > 80:
return "B"
elif 80 >= score > 70:
return "C"
else:
return "F"
score = int(input())
grade = get_grade(score)
print(grade) # A ~ Fif문은 워낙 많이 사용해봤기 때문에 난이도를 높게 설정하지 않은 이상 쉽게 풀 수 있었다.
2. 반복문(while)
요구조건
- 사용자의 입력을 받아 반복하는 프로그램을 만들어주세요
- 사용자가 숫자를 입력했을 경우 입력값에 2배를 곱한 수를 출력해주세요
- 사용자가 문자를 입력했을 경우 “입력한 문자는 {} 입니다.” 라는 문구를 출력해주세요
- {} 자리에는 사용자가 입력한 문자가 들어가야 합니다.
- 사용자가 exit을 입력하거나 숫자가 5회 이상 입력됐을 경우 프로그램을 종료시켜주세요
코드작성시작
count = 0
while True:
a = input()
if a.isdigit() == True:
print(int(a)*2)
count += 1
elif a.isdigit() == False:
print(f"입력한 문자는 {a} 입니다.")
else:
print("값을 다시 입력해 주세요.")
if a == "exit" or count == 5:
print("숫자를 5번 입력하셨습니다. 프로그램을 종료합니다.")
breakwhile문은 if문 만큼 자주 사용해 보지는 못했지만 개념은 이해하고 있기에 어렵지 않게 코드를 작성할 수 있었다. 다만 입력값 a가 정수인지 문자열인지 판단하는 법을 모르겠어서 이 부분은 구글링을 통해 .isdigit()이라는 함수를 검색해 사용하게 되었다.
3. 반복문(for)
요구조건
- 입출력 예제에 있는 사람들 중, 평균 성적이 70점 이상인 사용자의 이름과 나이를 출력해주세요
- 입출력 예제
users = [ {"name": "Ronald", "age": 30, "math_score": 93, "science_score": 65, "english_score": 93, "social_score": 92}, {"name": "Amelia", "age": 24, "math_score": 88, "science_score": 52, "english_score": 78, "social_score": 91}, {"name": "Nathaniel", "age": 28, "math_score": 48, "science_score": 40, "english_score": 49, "social_score": 91}, {"name": "Sally", "age": 29, "math_score": 100, "science_score": 69, "english_score": 67, "social_score": 82}, {"name": "Alexander", "age": 30, "math_score": 69, "science_score": 52, "english_score": 98, "social_score": 44}, {"name": "Madge", "age": 22, "math_score": 52, "science_score": 63, "english_score": 54, "social_score": 47}, {"name": "Trevor", "age": 23, "math_score": 89, "science_score": 88, "english_score": 69, "social_score": 93}, {"name": "Andre", "age": 23, "math_score": 50, "science_score": 56, "english_score": 99, "social_score": 54}, {"name": "Rodney", "age": 16, "math_score": 66, "science_score": 55, "english_score": 58, "social_score": 43}, {"name": "Raymond", "age": 26, "math_score": 49, "science_score": 55, "english_score": 95, "social_score": 82}, {"name": "Scott", "age": 15, "math_score": 85, "science_score": 92, "english_score": 56, "social_score": 85}, {"name": "Jeanette", "age": 28, "math_score": 48, "science_score": 65, "english_score": 77, "social_score": 94}, {"name": "Sallie", "age": 25, "math_score": 42, "science_score": 72, "english_score": 95, "social_score": 44}, {"name": "Richard", "age": 21, "math_score": 71, "science_score": 95, "english_score": 61, "social_score": 59}, {"name": "Callie", "age": 15, "math_score": 98, "science_score": 50, "english_score": 100, "social_score": 74}, ] def get_filter_user(users): # some code return filter_users filter_users = get_filter_user(users) pprint(filter_users) """ [{'age': 30, 'name': 'Ronald'}, {'age': 24, 'name': 'Amelia'}, {'age': 29, 'name': 'Sally'}, {'age': 23, 'name': 'Trevor'}, {'age': 26, 'name': 'Raymond'}, {'age': 15, 'name': 'Scott'}, {'age': 28, 'name': 'Jeanette'}, {'age': 21, 'name': 'Richard'}, {'age': 15, 'name': 'Callie'}] """
for문으로 users내에서 평균 점수가 70이 넘는 사람을 추려내 filter_users로 따로 빼낸 다음 filter_users에서 age와 name 값만 출력하면 되는 간단한 문제라고 생각했는데 하나의 for문 안에서 평균점수가 70점이 넘는 사람을 구하는 것, 그 사람들만 따로 분류해 내는 것, 그 사람들의 age와 name값만 나오게 하는 것. 이 세가지를 한번에 하는 것을 어떻게 하는지 몰라 구글링도 하고 오랜시간 고민을 해 보았지만 답이 나오지않아 결국 이 문제는 해설을 듣거나 따로 튜터님께 질문을 해보는 시간을 가져야 할 것 같다.
알고리즘 실습
이번 주도 저번주와 마찬가지로 알고리즘 실습이 시간표에 편성은 되어있었지만 튜터님과 매니저님 모두 파이썬 문법에 대한 이해를 강조해주셨기 때문에 알고리즘 실습 문제가 어렵고 파이썬 문법에 아직 미숙하다면 알고리즘 실습을 과감하게 포기하고 파이썬 문법 복습과 당일에 튜터님이 내주시는 과제에 집중해도 된다고 하셨기 때문에 이번주는 알고리즘 실습 문제를 많이 풀지는 않았고 당일 과제가 완벽히 해결된 다음 남는 시간에 문제를 풀어봤다.
10809번 알파벳 찾기
문제
알파벳 소문자로만 이루어진 단어 S가 주어진다. 각각의 알파벳에 대해서, 단어에 포함되어 있는 경우에는 처음 등장하는 위치를, 포함되어 있지 않은 경우에는 -1을 출력하는 프로그램을 작성하시오.
입력
첫째 줄에 단어 S가 주어진다. 단어의 길이는 100을 넘지 않으며, 알파벳 소문자로만 이루어져 있다.
출력
각각의 알파벳에 대해서, a가 처음 등장하는 위치, b가 처음 등장하는 위치, ... z가 처음 등장하는 위치를 공백으로 구분해서 출력한다.
만약, 어떤 알파벳이 단어에 포함되어 있지 않다면 -1을 출력한다. 단어의 첫 번째 글자는 0번째 위치이고, 두 번째 글자는 1번째 위치이다.
답
S = input()
alphabet = list(range(97,123))
for x in alphabet :
print(S.find(chr(x)))풀이
첫 줄에서 input값 S를 받는다.
둘째줄에서는 알파벳 리스트를 아스키 코드를 통해 받는데 아스키 코드의 값은 구글링을 통해 찾아보았다. for문을 만들어 변수x를 선언하고 x를 아스키코드에 해당하는 숫자를 문자열로 변환시키는 함수 chr을 사용했다. 그리고 find 함수를 사용해 S의 안에 chr함수로 변환된 함수가 있는지 찾아 맞는 값을 구하도록 코드를 만들었다.
아스키코드와 chr함수에 대한 이해가 필요해서 혼자서 해보려고 하기보다는 빠르게 구글링을 하는 쪽을 택해서 문제를 풀고 대신 이해가 될때까지 확실하게 여러번 문제를 확인해보았다.
2675번 문자열 단계
문제
문자열 S를 입력받은 후에, 각 문자를 R번 반복해 새 문자열 P를 만든 후 출력하는 프로그램을 작성하시오. 즉, 첫 번째 문자를 R번 반복하고, 두 번째 문자를 R번 반복하는 식으로 P를 만들면 된다. S에는 QR Code "alphanumeric" 문자만 들어있다.
QR Code "alphanumeric" 문자는 0123456789ABCDEFGHIJKLMNOPQRSTUVWXYZ$%*+-./: 이다.
입력
첫째 줄에 테스트 케이스의 개수 T(1 ≤ T ≤ 1,000)가 주어진다. 각 테스트 케이스는 반복 횟수 R(1 ≤ R ≤ 8), 문자열 S가 공백으로 구분되어 주어진다. S의 길이는 적어도 1이며, 20글자를 넘지 않는다.
출력
각 테스트 케이스에 대해 P를 출력한다.
답
T = int(input())
for _ in range(T):
R, S = input().split()
for x in S:
print(x*int(R), end='')
print()풀이
첫 줄에서 테스트케이스의 수 T를 input 값으로 받고 두번째 줄부터 테스트케이스를 T회 반복하도록 for문을 작성해준다. 이 테스트케이스는 반복횟수(R)와 반복할 문자열(S)을 공백으로 구분되어 받는다. 그리고 이 R과 S의 값을 input값으로 받아 다시 for문을 만들어 S안의 변수 x를 R회만큼 반복입력하도록 설정한다. 이때 한 줄로 출력이 되도록 end=''를 사용해주었다. 마지막으로 빈칸을 print 해준 것은 출력값이 나온 뒤 다음 입력값을 넣기 위해 줄바꿈을 해주기 위해서이다.
1157번 단어 공부
문제
알파벳 대소문자로 된 단어가 주어지면, 이 단어에서 가장 많이 사용된 알파벳이 무엇인지 알아내는 프로그램을 작성하시오. 단, 대문자와 소문자를 구분하지 않는다.
입력
첫째 줄에 알파벳 대소문자로 이루어진 단어가 주어진다. 주어지는 단어의 길이는 1,000,000을 넘지 않는다.
출력
첫째 줄에 이 단어에서 가장 많이 사용된 알파벳을 대문자로 출력한다. 단, 가장 많이 사용된 알파벳이 여러 개 존재하는 경우에는 ?를 출력한다.
답
S = input().upper()
unique_S = list(set(S))
count_list = []
for x in unique_S:
count = S.count(x)
count_list.append(count)
if count_list.count(max(count_list)) > 1 :
print("?")
else :
max_index = count_list.index(max(count_list))
print(unique_S[max_index])풀이
첫 줄에서 input값을 받는데 대문자와 소문자를 구분하지 않기 때문에 .upper()를 적용해 전부 대문자로 input값을 받아준다. 그리고 이 S에서 중복된 값을 제거해주기 위해 set함수를 적용한 뒤 list로 만들어준다. count_list를 비어있는 list로 만들어주고 for문을 만들어서 S에 같은 알파벳이 몇번 들어가는지 count해서 count_list에 넣어준다. 이 count_list에서 가장 큰 수가 1보다 크면, 즉 가장 많이 사용된 알파벳이 2개 이상이면 ?를 출력하고 아닐경우 가장 많이 사용된 알파벳이 몇번째 index값인지 구해서 그 index값을 Unique_S에서 찾아 출력하도록 코드를 작성했다.
이번주를 마치며
이번 주는 파이썬 문법 강화기간이라고 볼 수 있는 주간이었다. 추석연휴때문에 주 4일만 진행되었기 때문인지 짧기도했고 파이썬 문법 복습이라고해도 이론적인 부분이 부족하기 보다는 실제 사용 경험이 적어서 과제나 활용문제를 풀때 사용법을 모르겠어서 굉장히 어수선한 한 주를 보낸 기분이다. 파이썬 문법에 대한 복습을 하려고 해도 이론적인 측면에서는 머리속에 다 있고 이미 풀어본 과제나 예제를 복습하려고 하면 이미 실수한 부분을 두 번 실수하는 일은 없기 때문에 수월하게 진행되는데 다른 방식으로 접근하기 위해 관련문제를 찾아 풀어보려고하면 코드를 어떻게 짜야하는지 갈피를 못잡아서 많이 헤메었던 것 같다. 그래서 거북이반이 개설되어 튜터님께 추가적으로 강의를 듣고 새로운 과제도 받아 볼 수 있는 기회가 있어서 너무 좋은 프로그램인 것 같다. 덕분에 갈피도 어느정도 잡을 수 있을 것 같으니 거북이반의 이름처럼 느리지만 꾸준히 걸어서 도착점까지 갈 수 있도록 노력하겠다.
