prometheus 란 ?
결론 적으로 말하면 모니터링을 데이터를 수집하는 역할을 합니다. architecture를 보면 큰 그림으로 이해가 됩니다.
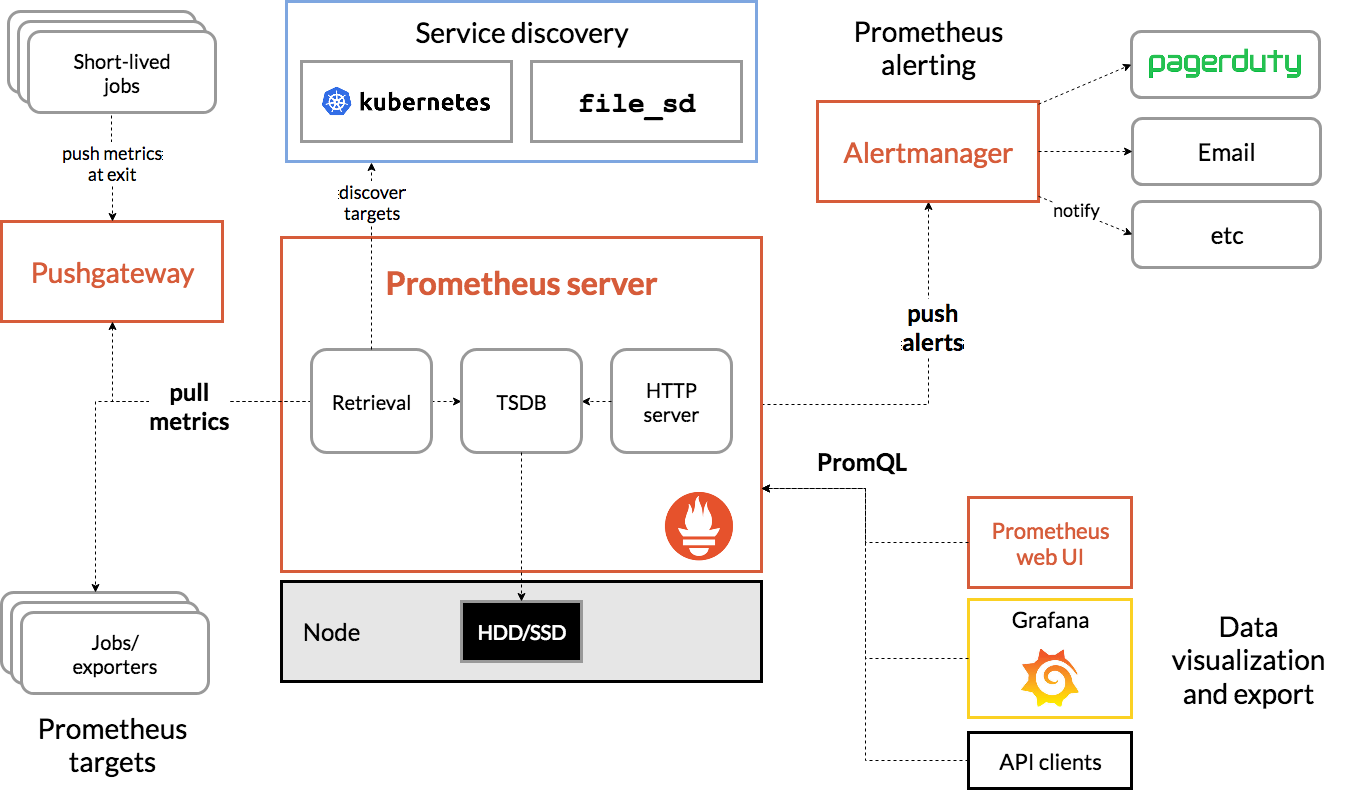
출처 : https://prometheus.io/docs/introduction/overview/
아는 것만 적어보도록 하겠습니다. 60% 만 신뢰해주세요.
jobs/exporters: 각각의 노드에서 베트릭정보를 가져옵니다. 노드별로 메트릭 정보를 수집해야하니까 각각의 노드마다 exporter가 구성되어 있어야 합니다.
ex.
노드가 4개라고 가정하면 node 마다 exporter가 배포되어 있어야 합니다.
alertmanager
metric 정보를 기준으로 해서 알림을 보낼 수 있습니다. slack , server , email … bra bra 있습니다.
promQL
prometheus query 로 질의를 통해서 대시보드를 구현할 수 있고 클러스터의 현황을 시각적으로 파악할 수 있습니다.
Retrieval
다양한 서비스 타겟팅해서 모니터링 할 수 있습니다.
제가 아는 내용 전부입니다. 자세히는 저도 아직 잘 모르니 궁금한 점은 각자 찾아봅시다 :)
꼭 드리고 싶은 말
처음에 클러스터에 구성을 하면서 많은 시간을 버렸던 것은 time series에 대한 이해도가 없이 쿼리를 공부해서 오히려 혼돈이 생겼습니다.
그래서 prometheus 를 처음 접해본다면 ,
단순히 대시보드만을 이용해서 관리를 했던 분들이라면 먼저 “시계열 데이터”라는 컨셉을 먼저 이해하고 시작 했으면 좋겠습니다.
위 2개의 글은 꼭 읽고 작업을 시작했으면 좋겠습니다.

경선 :)