
개요
최근에 레이싱 데이터를 실시간으로 수집하여 모니터링으로 표현하는 영상을 봤습니다.
카프카를 활용한 레이싱카 센서 실시간 수집 데이터 파이프라인 구축
재밌어 보였습니다. 위 주제에서 주로 사용되는 kafka 에 대해서 컨셉, 구조, 간단한 코드들과 함께 설명해보려고 합니다.
kafka란 ?
kafka가 무엇인지 Aphache, GPT, Bard 에게 물어봤다.
Aphache
ㅎㅎㅎㅎㅎ … 링크 제공할테니 봐주세요.
GPT
💡 카프카(Kafka)는 대용량 실시간 데이터 스트리밍 플랫폼입니다. 아파치 소프트웨어 재단(Apache Software Foundation)에서 개발되었으며, 분산형 아키텍처를 기반으로 한다는 특징을 가지고 있습니다.카프카는 여러 시스템 및 응용 프로그램 간에 대용량 데이터를 안정적으로, 신속하게, 확장 가능하게 전송하는 역할을 수행합니다. 주로 실시간 데이터 피드(데이터 스트림)를 처리하고 저장하기 위해 사용됩니다.
카프카는 토픽(Topic)이라는 개념을 사용하여 데이터를 구조화하고, 각 토픽은 하나 이상의 파티션(Partition)으로 분할됩니다. 파티션은 데이터를 병렬로 처리하고 여러 컨슈머(Consumer)가 동시에 데이터를 읽을 수 있도록 합니다. 카프카의 데이터 저장은 지속적으로 이루어지며, 따라서 컨슈머가 오프라인 상태였던 동안에도 데이터 손실 없이 데이터를 검색할 수 있습니다.
카프카는 대규모 데이터 파이프라인, 실시간 스트리밍 애플리케이션, 이벤트 소싱(Event Sourcing) 등 다양한 분야에서 사용됩니다. 주요 사용 사례로는 로그 수집, 모니터링, 메시징 시스템, 웹 사이트 트래픽 처리, 분산 커밋 로그, 사물 인터넷(IoT) 데이터 스트리밍 등이 있습니다.
카프카는 확장성과 내결함성을 갖추고 있어 대량의 데이터를 처리하고, 여러 컨슈머가 동시에 데이터를 읽을 수 있으며, 일부 구성 요소의 장애에도 데이터 손실 없이 안정적으로 작동할 수 있습니다. 이러한 특징들 때문에 카프카는 현대적인 데이터 아키텍처에서 매우 중요한 역할을 수행하고 있습니다.
Bard
💡 Apache Kafka는 실시간으로 기록 스트림을 게시, 구독, 저장 및 처리할 수 있는 분산형 데이터 스트리밍 플랫폼입니다. 여러 소스에서 데이터 스트림을 처리하고 여러 사용자에게 전달하도록 설계되었습니다. 간단히 말해서 A지점에서 B지점까지 이동하는 것뿐만 아니라 A지점에서 Z지점을 비롯해 필요한 모든 곳에서 대규모 데이터를 동시에 이동할 수 있습니다. Apache Kafka는 전통적인 엔터프라이즈 메시징 시스템의 대안입니다. 하루에 1조 4천억 건의 메시지를 처리하기 위해 LinkedIn이 개발한 내부 시스템으로 시작했으나, 현재 이는 다양한 기업의 요구 사항을 지원하는 애플리케이션을 갖춘 오픈소스 데이터 스트리밍 솔루션이 되었습니다.Kafka는 주로 스트리밍 애플리케이션을 위한 분산 메시징 시스템으로 사용됩니다. 또한 데이터 파이프라인, 데이터 웨어하우징 및 분석을 위한 데이터 저장소로 사용할 수도 있습니다.
Kafka는 분산 시스템으로, 데이터를 처리하기 위해 여러 서버에 배포됩니다. 이렇게 하면 고가용성 및 확장성이 향상됩니다. Kafka는 또한 매우 내구성이 뛰어나, 서버가 실패하더라도 데이터가 손실되지 않습니다.
Kafka는 매우 사용하기 쉬운 시스템으로, 다양한 프로그래밍 언어에서 사용할 수 있습니다. 또한 관리가 매우 쉽고, 클러스터 크기에 관계없이 쉽게 확장할 수 있습니다.
Kafka는 많은 기업에서 사용되는 인기 있는 데이터 스트리밍 시스템입니다. 고성능, 내구성 및 확장성을 제공하는 시스템을 찾는 기업에 적합합니다.
어디에 사용될까 ?!
ㅎㅎㅎ… 위 글을 보시면 좋을 것 같습니다.
영어를 잘 하는 분들이고 글 읽는 것을 좋아한다면 위 doc 에서 많은 내용을 읽으면 좋습니다.
감이 오시나요 ?!!
위 내용들을 보면 대충은 이해갑니다.
그런데 모르겠습니다.
kafka를 처음 접하는 분이라면 저와 비슷한 상황일 것 같습니다.
이유는 설명들이 광범위하다고 생각했습니다. (한글도 모르는데 영어 배우는 느낌 ?!! …)
그래서 나름대로 처음에 알면 이해하는데 도움이 될 수 있는 내용을 정리해보려고 합니다.
그 전에 !! 나름대로 제 포스팅보다 Confluent 에서 제공하는 튜토리얼이 더 도움되실 수 있습니다. Confluent는 kafka 공신력이 있는 조직입니다. 역사를 살펴보시면 알 수 있습니다. 하고 싶은 말은 아래에서 다양한 교육영상을 제공합니다.
What is Apache Kafka®? Online Course for Beginners
저는 자세히 설명하지 않습니다.
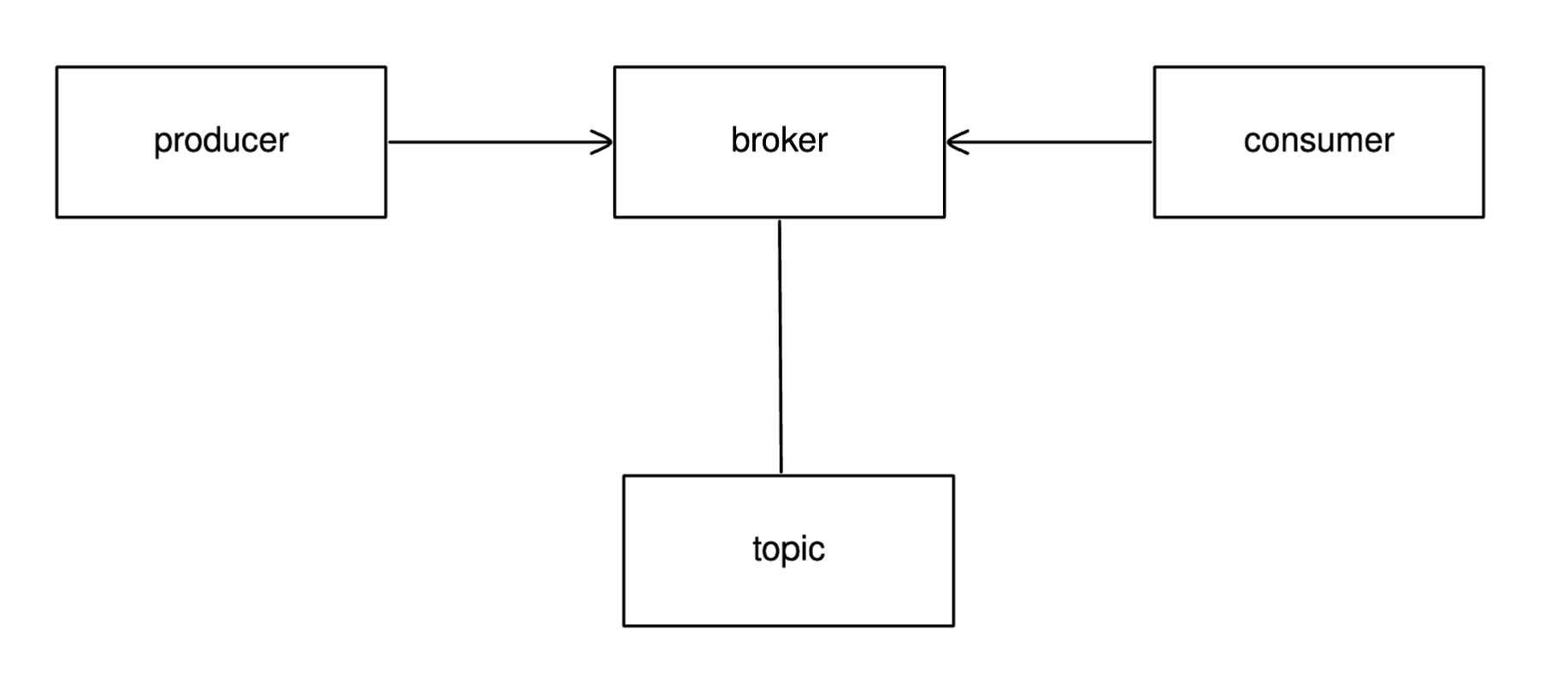
topic
저장소이름입니다. 예를 들면
- A topic
- B topic
- …. 있습니다.
DB 가 생각나신다면 테이블 이름이라고 생각하세요, 폴더가 생각난다면 폴더명으로 생각하세요.
broker
다른 애들이 broker한테 A or B 토픽에 있는 메세지(데이터) 요청합니다. 그러면 얘가 줍니다.
broker는 클러스터로 여러개가 존재할 수 있습니다. 여러개가 되면 장점이 많습니다. 상태가 더 안전하기도 하고 빨라지기도 하고 … 뭐 대충 이런 느낌입니다. 자세한건 confluent에서 찾아봅시다.
위에서 broker 한테 메세지 달라고 하는 애가 있다고 했습니다. 그게
consumer
얘 입니다. consumer 특정 topic 에 있는 메세지를 달라고 합니다.
그렇다면 거기에 데이터는 누가 넣을까요 ?
producer
얘 입니다. A ro B 토픽에다가 데이터를 넣어줍니다.
왜 쓸까요 ?!
제가 처음에 kafka 를 공부하면서 뭔가 다 각각 서비스들이 해결할 수 있는 문제라고 생각했습니다. (오해하지 마세요. 저 kafka 잘하는 사람 아닙니다. 1주일 봤습니다)
해결할 수 있는 문제 logging , 분석, 스트리밍 … 뭔가 다 될거 같지 않나요 ?!! 그런데 이 kafka란 친구가 규모가 크고 다양한 서비스가 많이 있을 때 재밌는 놈입니다.
내 전공 전자공학
제가 전자공학 나왔습니다. 전자공학에서 뭔가 설계할 때 소자(원자재)가 굉장히 중요합니다. 이때 과제했을 때 진짜 짜증나는 일이 있었습니다.
- 소자 준비하고 스펙 확인해서 준비를 다 했습니다.
- 연구실 가서 확인합니다. 알아본 소자들이 없습니다.
- 그래서 그냥 대충 있는걸로 커버를 했습니다.
- 그리고 다해서 조교한테 먼저 보여줍니다. 빠꾸 먹습니다. 왜?! 대체 소자들을 사용하면 안된다고 합니다.
이걸 kafka 랑 비교해서 생각할 수 있을 것 같았습니다.
- 서비스1. 설계중인 나
- 서비스2. 원자재관리하는 연구실
- 서비스3. 1차 평가해주는 조교
위 서비스들이 REST로 구현되어 있다고 가정하고 kafka가 없으면 어떤 문제들이 생길 수 있을지 생각해봤다.
- 서비스중에서 서버가 망가지면 다음으로 넘어가지 못한다. → kafka 는 consumer , producer 가 분리되어 있어 안전하다.
- (서비스들의 과정을 결재라고 표현하겠습니다.) 위 결재를 진행하기 위해서 2가지만 확인하면 되지만 저 과정이 50개라면 ?! 서로 소통하게 만드는게 복잡할 것이다. → kafka라면 1개의 topic 기준으로 consumer 을 만들면 된다.
(….. 한 번에 이해할 수 있는 예를 만들어보고 싶었는데 … 잘 안되네요 ㅋㅋㅋ ;;; confluent , aphache kafka 참고합시다.)
소스코드
consumer , producer, consumer group 을 만들었으며 내부가 어떻게 되어있는지 같이 까봅시다.
언어는 golang 씁니다. kafka가 java로 되어 있어서 java 로 할까 했는데 생각해보니 kafka 특성상 대용량으로 사용되고 많은 서비스들과 함께 사용된다면 IO 작업이 많을 것 같아서 golang 써보려고합니다.
라이브러리는 Shopify/sarama 사용합니다. 오픈소스입니다.
confluent-kafka-go 왜 사용안하는지 궁금해하시는 분 있을 수 있을 것 같습니다. ⇒ 일단 위도우를 지원하지 않습니다. 그리고 C 에 의존하는 부분이 많아서 그냥 안씁니다.
segmentio/kafka-go library 도 있습니다. 본인들은 문서 정리도 잘되어 있고 다른 것드에 비해서 자기들이 잘한다고 말하고 있습니다. (확인하진 않았습니다. 뭐 …ㅎㅎㅎ 이거 사용해도 괜찮을거 같아요. 원하는걸로 씁시다.)
sarama 쓰는 제일 큰 이유는 start 가 제일 많습니다.
💡 kafka 다운로드는 각자 하실 수 있습니다. kafak aphache 공홈에서 바이너리로 받아서 윈도우 , 리눅스 , 맥 , k8s(다른 orchestration 잘 모르겠습니다), docker 다 사용가능 합니다. k8s 사용하시는 분들은 helm도 지원하는 것 같으니 확인해보세요.consumer
import (
"errors"
"fmt"
"log"
"os"
"os/signal"
"github.com/Shopify/sarama"
)
func Consumer(topic string) {
conf := sarama.NewConfig() // 가)
conf.Producer.Return.Successes = true
connectionStringArr := []string{"localhost:9092"}
consumer, err := sarama.NewConsumer(connectionStringArr, conf) // 나)
if err != nil {
panic(err)
}
defer func() {
if err := consumer.Close(); err != nil {
log.Fatalln(err)
}
}()
partitionConsumer, err := consumer.ConsumePartition(topic, 0, int64(-2)) // 다)
if err != nil {
panic(err)
}
defer func() {
if err := partitionConsumer.Close(); err != nil {
log.Fatalln(err)
}
}()
signals := make(chan os.Signal, 1)
signal.Notify(signals, os.Interrupt)
consumed := 0
ConsumerLoop:
for {
select {
case msg := <-partitionConsumer.Messages():
log.Printf("Consumed message offset %d\n", msg.Offset)
log.Printf("Consumed message value %s\n", string(msg.Value))
consumed++
case <-signals:
break ConsumerLoop
}
}
log.Printf("Consumed: %d\n", consumed)
}이후에도 위와 비슷한 순서(?!)로 코딩됩니다. producer, kafka client 등등.
비슷한 순서란 가, 나, 다 주석 입니다.
가) sarama에서 config 구조체를 확인해보면 상당히 많은 메타데이터가 들어갑니다. 그리고 config 안에서 admin, consumer , producer 등등 관련 메타데이터가 저장됩니다.
sarama package - github.com/Shopify/sarama - Go Packages - Config
나) config 데이터를 기반으로 해서 consumer 를 만듭니다.
sarama package - github.com/Shopify/sarama - Go Packages - Consumer
consumer가 무슨일 하는지 궁금하다면 인터페이스에서 함수들 설명 보면 좋습니다.
다) 파티션에서 메세지를 가져옵니다. (채널을 통해)
ConsumePartition 이 무슨일을 하는지 알 수 있습니다.
sarama package - github.com/Shopify/sarama - Go Packages - Consumer
위 메서드에서 return 되는 객체입니다.
sarama package - github.com/Shopify/sarama - Go Packages - PartitionConsumer
저는 이 kafka를 처음에 하면서 힘들었던 부분이 sarama library 가이드가 친절하지 않았습니다. 정리가 잘 정리된 라이브러리는 즁요 기능별로 사용방법을 제시해줍니다. example처럼 말이죠. 하지만 양이 너무 많기도 하고 … (넋두리: 제 포스팅 역시 친절하지 않습니다. 때문에 … 질타를 할 자격은 없는 것 같네요.)
그러나 우리에겐 GPT, Bard, 뤼튼, 등 다양한 조언자들이 있습니다. 이 친구들을 적극적으로 활용한다면 예제 코드를 만들어주고 그 코드를 기반으로 라이브러리를 까보고 비교하면 빠르게 적응할 수 있습니다.
→ git 까보면 example이 존재하긴 합니다. 하지만 개인적으로 큰 도움을 받지 못했습니다. 그 이유는 kafka에 대한 컨셉도 잘 모르면서 운영에 먼저 접근했던게 문제지 않았을까 생각합니다.
consumer, consumer group 등등
consumer , consumer group 관련 코드가 있습니다. 이건 위와 같은 방법으로 공부했고 코드가 궁금한 분들은 아래에서 확인하실 수 있습니다. (kafka 만 봐주시면 됩니다. 이쁘게 안되어 있습니다.)
git: https://github.com/ShinGyeongseon367/practicekafka
뉴비한테 추천하고 싶은 글
궁금한 내용, 틀린 부분, 같이 얘기하고 싶은 점이 있다면 언제든지 댓글 달아주세요.
