이전 포스팅에 이어서 다음 내용이다.
접근 불가 객체를 이동하는 것이 효율적인가?(Why moving unreachable objects is better?)
Python Developer’s Guide 블로그 글 번역
대부분의 경우, 객체는 접근 가능한 상태로 남아있다. 그러므로 처음에는 도달 불가능한 객체를 옮기는 것이 합리적으로 보일 수 있다. 하지만 실제 동작에서 이렇게 할 필요는 없다.
예를 들어, 객체 A, B, C를 순서대로 생성했다고 가정해 보자. 이들은 '젊은 세대(young generation)'에서도 같은 순서로 배치된다. 참조 순서는 A ← B ← C ← 외부이다. 여기서 C는 외부에서 참조되며 접근 가능한 상태이므로, 참조 횟수가 1이다. 반면, A와 B의 참조 횟수는 각각 0이다.
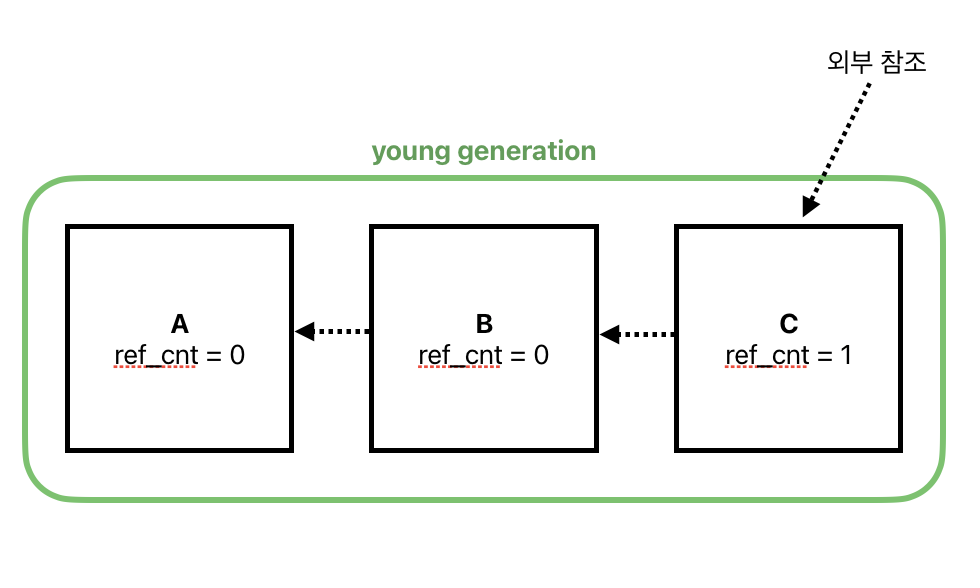
가비지 컬렉션의 첫 단계에서 A는 접근 불가 리스트(unreachable list)에 추가된다. B에 대해서도 마찬가지이다. 하지만 C가 처리될 때, B는 다시 접근 가능 리스트(reachable list)로 옮겨진다. 이후 A도 동일한 과정을 거친다. 이러한 방식으로 A와 B는 두 번 이동하게 되는데, 왜 이런 방식으로 동작하는 걸까?

이는 접근 가능 객체를 이동하는 알고리즘이 객체들을 C, B, A 순서로 옮기기 때문이다. 객체들의 생성 순서와 반대로 작동하는 이 알고리즘은 효율적이지 않아 보일 수 있다. 그러나 대부분의 객체들은 순환 구조에 있지 않기 때문에, 이 방식을 통해 객체 간 탐색과 이동 시간을 절약할 수 있다.
결론적으로, Python 가비지 컬렉터는 메모리 관리의 효율성을 위해 때때로 도달 불가능한 객체를 옮긴다. 이는 객체 간의 관계와 메모리 사용 패턴을 고려한 결과로, Python 프로그램의 전반적인 성능에 중요한 역할을 한다.
추가 설명
접근 가능 객체를 이동하는 알고리즘은 C → B → A 순서로 동작한다. 하지만 같은 세대에서 객체의 메모리 상 순서는 A → B → C 이므로 비효율적이다. 하지만 순환 구조가 아니기 때문에 탐색 한 번으로 접근 불가 객체를 식별할 수 있다.
Python GC 개요
지난 포스팅에서도 언급했었지만, 다시 한번 간단하게 Python GC 동작 메커니즘을 설명하자면 다음과 같다.
Python의 가비지 컬렉션: 기본 원리
Python은 주로 참조 횟수 기반의 가비지 컬렉션을 사용한다. 이는 객체에 대한 참조가 더 이상 존재하지 않을 때, 즉 참조 횟수가 0이 될 때, 해당 객체를 메모리에서 해제하는 방식이다. 하지만, 이 방식만으로는 순환 참조가 있는 객체들, 예를 들어 Circular linked list와 같은 구조에서는 메모리 누수가 발생할 수 있다.
순환 참조와 Cyclic Garbage Collection
Python은 순환 참조 문제를 해결하기 위해 순환 가비지 컬렉션 메커니즘을 도입했다. 이는 객체 간의 참조 사이클을 탐지하고, 필요하지 않게 된 객체들을 안전하게 제거한다.
Java와 Python의 GC 방식 비교
JVM 기반 언어들, 예를 들어 Java와 Kotlin은 'tracing' 기반의 GC를 사용한다. 이는 'mark and sweep' 알고리즘을 기반으로 하며, GC 수행 시 다른 모든 작업을 중지하는 'stop-the-world' 이벤트를 포함한다. 'stop-the-world' 시간을 줄이는 것이 GC 최적화를 하는 주요 목표이다.
Python: 세대 기법
Python은 상대적으로 느린 GC 속도에 대응하기 위해 세대(Generation) 기법을 사용한다. 이 방식은 객체들을 여러 세대로 분류하고, 각 세대별로 GC를 수행한다.
Weak Generational Hypothesis
Java의 가비지 컬렉션은 'weak generational hypothesis'에 기반한다. 이 가설은 다음과 같은 두 가지 주요 전제 조건을 포함한다.
- 대부분의 객체는 생성 후 짧은 시간 내에 접근 불가능한 상태가 됩니다.
- 오래된 객체에서 젊은 객체로의 참조는 드뭅니다.
아래 내용은 HotSpot VM(JVM의 한 버젼)의 generational hypothesis 참고했다.
네이버 D2 기술 블로그 - Java Garbage Collection
Young Generation과 Old Generation
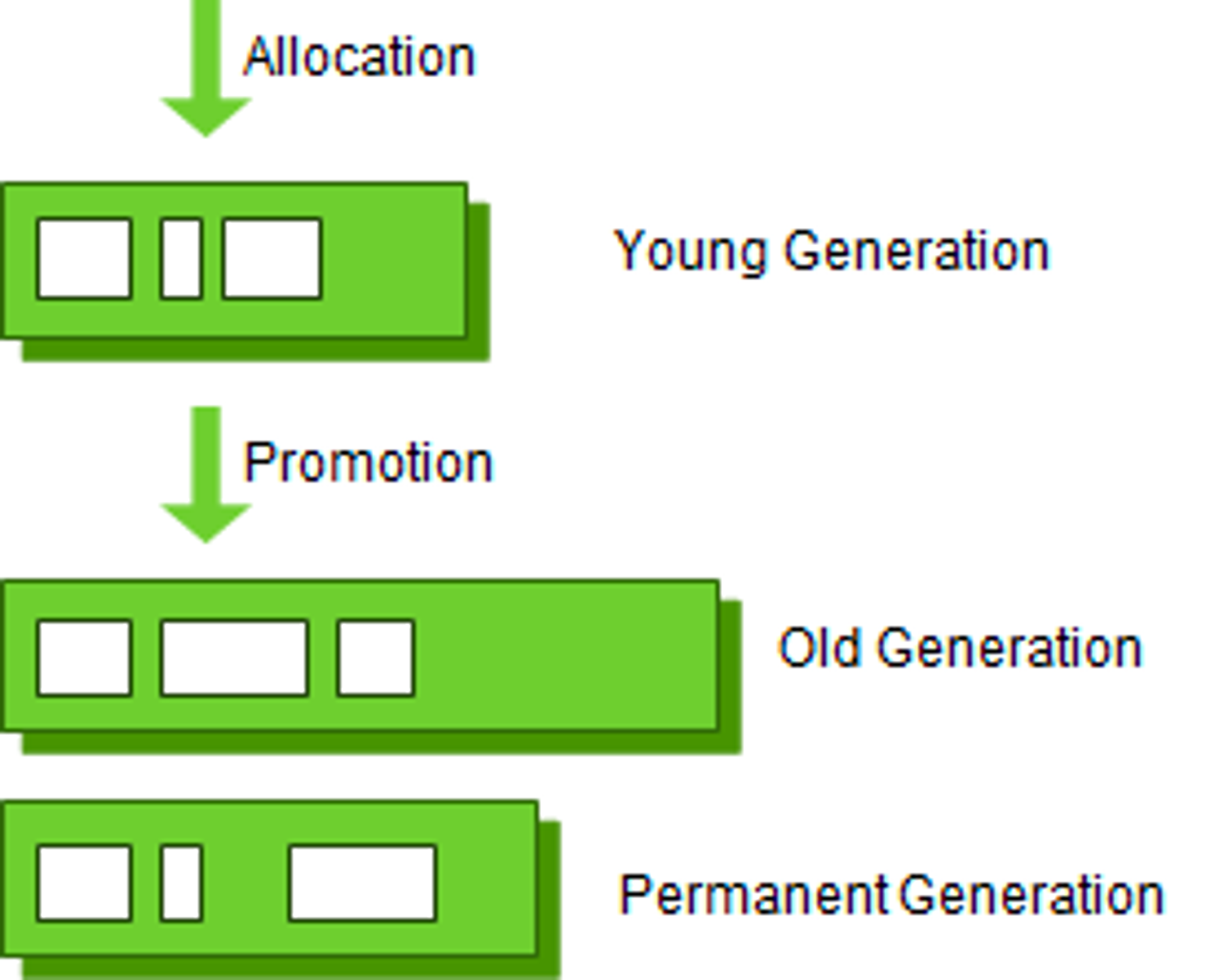
Java의 힙 메모리는 크게 Young Generation과 Old Generation으로 나뉜다. Young Generation 영역에서는 주로 새로 생성된 객체들이 위치하며, 이 영역에서의 GC를 'Minor GC'라고 한다. 반면, Old Generation 영역은 시간이 지난 객체들을 저장하고, 이 영역의 GC는 'Major GC' 또는 'Full GC'라고 한다. 아래 그림에서 Permanent Generation은 Method Area라고도 불린다. 객체, 억류된 문자열 정보를 저장한다. 이 영역의 GC도 Major GC에 포함된다.
억류된 문자열: Java에서의 문자열 인터닝
Java에서 문자열 리터럴은 'Interned Pool'에 저장된다. 이는 문자열 리터럴의 중복을 방지하고, 동일성 검사를 빠르게 수행한다.
String s1 = "hello";
String s2 = "hello";
boolean same = (s1 == s2); // true위 코드에서, s1과 s2는 동일한 문자열 리터럴을 참조하기 때문에, 두 변수는 메모리상 동일한 주소를 가리킨다.
억류된 문자열: Python에서의 자동 및 명시적 인터닝
Python은 짧은 문자열 리터럴에 대해 자동으로 인터닝된다. 또한, sys.intern() 메소드를 사용하여 명시적으로 인터닝할 수 있다.
a = "hello" # 리터럴로 생성된 문자열
b = "hello"
print(a is b) # True
c = "".join(["h", "e", "l", "l", "o"]) # 동적으로 생성된 문자열
print(a is c) # False위 예시에서 a와 b는 자동으로 인터닝되어 동일한 객체를 참조하지만, c는 동적으로 생성되어 별도의 객체로 취급된다.
문자열의 불변성과 멀티 스레드 안전성
문자열의 불변성은 데이터의 무결성을 보장하고, 멀티 스레드 환경에서의 안전한 공유가 가능하다.
a = "hello"
b = a
a += " world" # a가 새로운 메모리 주소를 가리킴
print(b) # "hello" - b는 변하지 않음이 예시에서 a의 변경이 b에 영향을 주지 않는 것을 볼 수 있다. 이는 문자열이 불변 객체임을 나타낸다.
Old 영역에서 Young 영역 참조
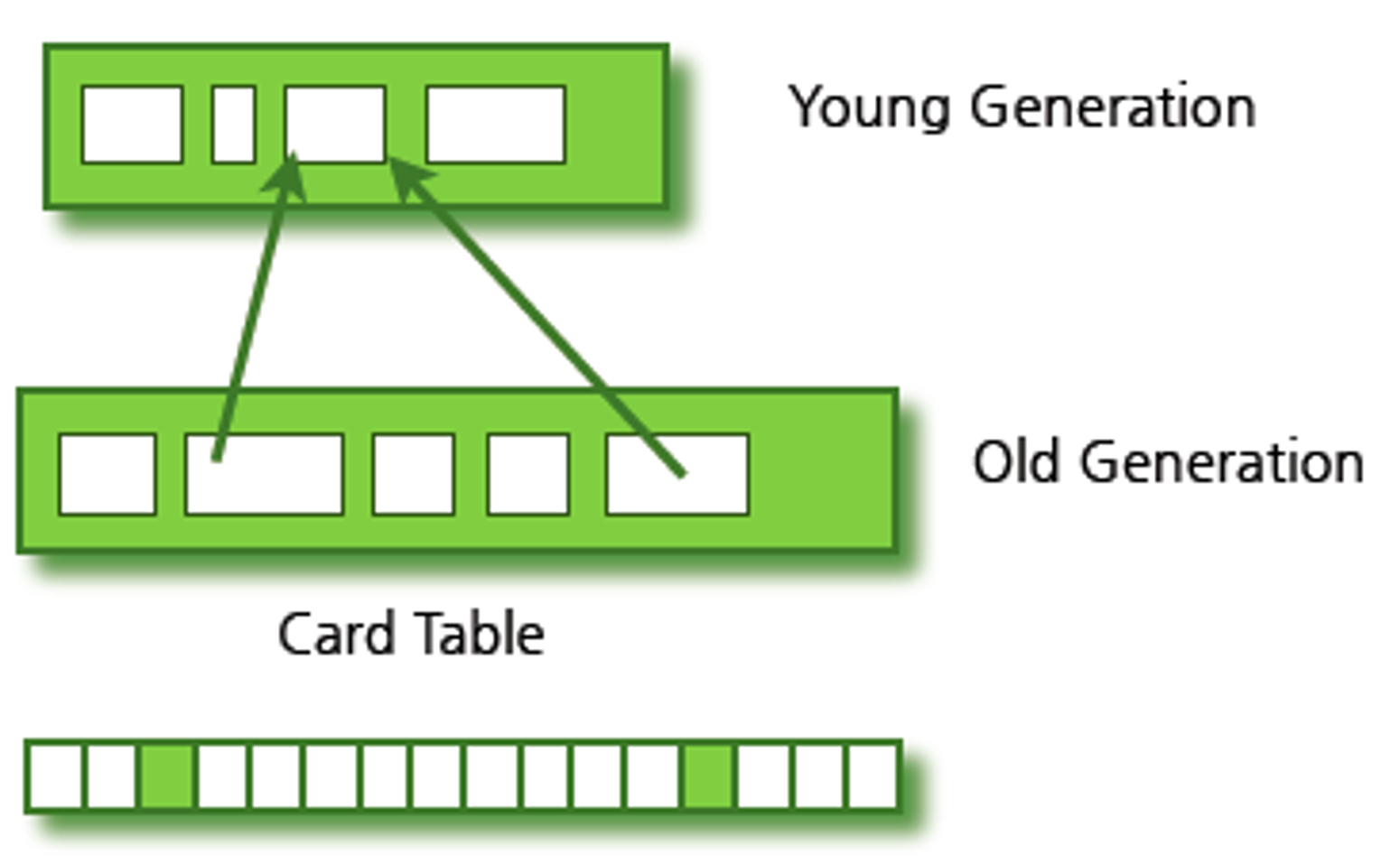
old 객체가 young 객체를 참조할 때마다 카드 테이블에 정보 표시한다. Minor GC시 Old 영역에서 참조되는 Young 객체는 카드 테이블만 검사 후 GC 대상인지 식별된다. 이런 카드 테이블은 Write Barrier라는 객체로 관리된다. 그 특성은 다음과 같다.
- Old 객체가 Young 객체를 참조할 때마다
Young 영역 구조
- Eden
- Survivor 2개: 둘 중 하나는 반드시 비어있어야 한다. 둘 다 데이터가 있거나 둘 다 비어있는 경우는 시스템이 정상이 아닌 상황이다.
Young 영역의 GC 과정
Young 영역의 GC 과정은 다음과 같다.
- Eden 영역에 새로 생성된 객체
- Eden 영역에서 GC가 발생한 후 살아남은 객체들은 Survivor 영역 중 하나로 이동
- 이 과정은 반복되며, 살아남은 객체들은 같은 Survivor 영역으로 계속 쌓입니다.
하나의 Survivor 영역이 가득 차면, 객체들은 다른 Survivor 영역으로 이동합니다.
결국, 오래 지속되고 살아남은 객체들은 Old 영역으로 이동합니다.
