1.3.1 스케줄링의 목적 (중요도 1)
- 공평성: 모든 프로세스가 공평하게
- 효율성: 자원이 사용되지 않는 시간이 없도록
- 안정성: 높은 우선순위 프로세스를 먼저
- 반응 시간 보장: 프로세스가 일정 시간 내에 응답할 수 있도록
- 무한 연기 방지: 프로세스 처리가 무한히 연기되지 않도록
1.3.2 스케줄링의 단계 (중요도 3)
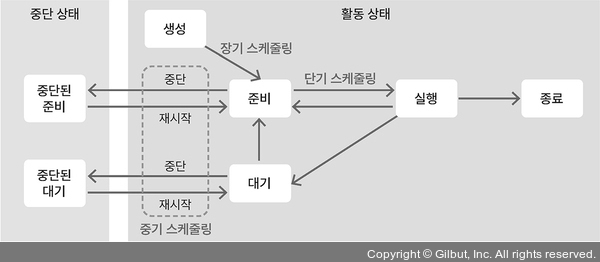
- 장기 스케줄링(잡 스케줄링, 승인 스케줄링): 준비 큐에 어떤 프로세스를 넣을지 결정하여 메모리에 올라가는 프로세스 수 조절. 현대 운영체제에서 시분할 시스템을 사용하여 대부분 사용 X
- 중기 스케줄링: 메모리에 로드된 프로세스 수를 동적으로 조절. 프로세스가 많이 로드 될 시, 스왑 아웃으로 일부 프로세스를 통째로 저장
- 단기 스케줄링(CPU 스케줄링): 준비 큐에 있는 프로세스 중, 알고리즘을 통해 어떤 프로세스를 먼저 실행(디스패치) 할지 결정
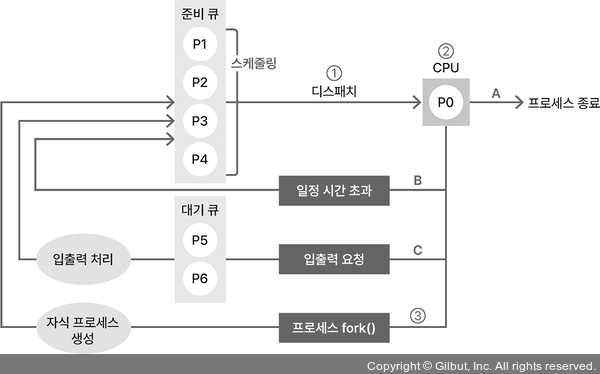
- 스와핑: 프로세슬르 통째로 메모리 영역/저장 공간으로 옮기는 것
- 스왑 아웃: 메모리 공간보다 많은 프로세스가 로드 → 중기 스케줄러가 준비/대기 중인 프로세스를 저장 공간으로 옮겨 저장
- 스왑 인: 스왑 아웃한 프로세스에거 요청이 오면 다시 메모리에 로드
import multiprocessing
import time
import psutil
def process_task():
print(f"Process {multiprocessing.current_process().pid} started")
time.sleep(10)
print(f"Process {multiprocessing.current_process().pid} finished")
def monitor_processes(processes):
try:
while processes:
for process in list(processes):
proc = psutil.Process(process.pid)
print(f"PID: {process.pid}, Name: {proc.name()}, State: {proc.status()}")
if not process.is_alive():
processes.remove(process)
except KeyboardInterrupt:
print("Monitoring stopped")
if __name__ == "__main__":
processes = []
for _ in range(5):
p = multiprocessing.Process(target=process_task)
p.start()
processes.append(p)
for p in processes:
p.join()Process 1627 started
Process 1625 started
Process 1630 started
Process 1628 started
Process 1631 started
Process 1627 finished
Process 1625 finished
Process 1630 finished
Process 1628 finished
Process 1631 finished1.3.3 스케줄링 알고리즘 (중요도 3)
평가 기준
- CPU 사용률
- 처리량
- 응답 시간
- 반환 시간
- 대기 시간
비선점형 스케줄링
- 실행 중인 프로세스가 종료될 때가지 다른 프로세스를 실행할 수 없음을 의미
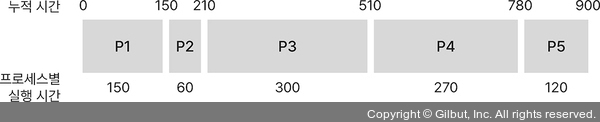
- FCFS 스케줄링: 준비 큐에 먼저 들어온 프로세스를 먼저 처리
- SJF 스케줄링: 실행 시간이 짧은 프로세스를 먼저 처리 → 실행 시간이 긴 프로세스는 기아 상태가 될 수 있음
선점형 스케줄링
- 스케줄러가 실행 중인 프로세르를 중단시키고 다른 프로세스를 실행할 수 있음
- RR(Round Robin) 스케줄링: 모든 프로세스를 일정 시간 동안 실행, 초과 시 다른 프로세스 실행.
장점: 응답 속도가 빠름
단점: 콘텍스트 스위칭이 빈번하게 일어나 오버헤드가 큼 - SRTF 스케줄링: 준비 큐에 대기 시간이 가장 짧게 남은 프로세스를 우선 실행
장점: 평균 대기 시간이 짧음
단점: 수행 시간이 긴 프로세스는 기아 상태 - 멀티 레벨 스케줄링: 준비 큐를 여러 개로 분리 → 각 우선순위, 각자 다른 스케줄링 알고리즘 → 각 큐는 다시 foreground 큐와 background 큐로 나뉨.
foreground 큐: 응답 속도가 중요한 프로세스
background 큐: 응답 속도보다 성능을 중요시하는 프로세스
예제
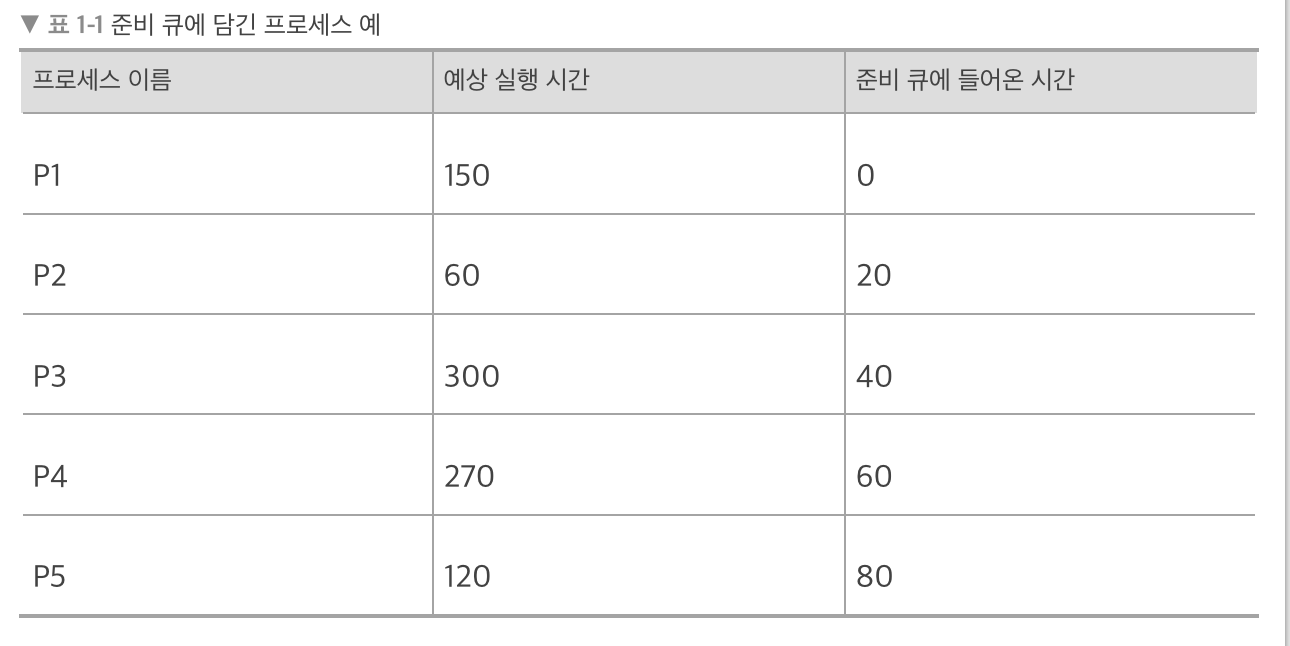
- FCFS
- SJF
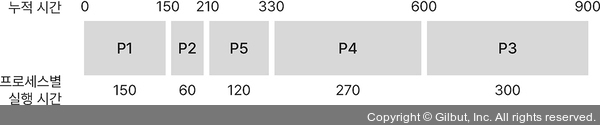
- RR

- SRTF

- 멀티 레벨 스케줄링

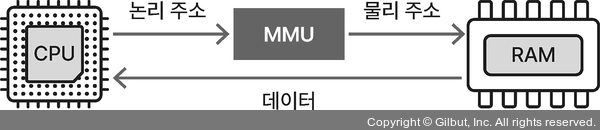
1.4.1 논리 메모리와 물리 메모리 (중요도 1)
- 프로세스가 보는 메모리 영역: 논리/가상 메모리 영역 → 논리/가상 주소
- 실제 메모리 영역: 물리 메모리 영역 → 물리 주소
- 메모리 관리 장치로 변환
1.4.2 연속 메모리 할당 (중요도 1)
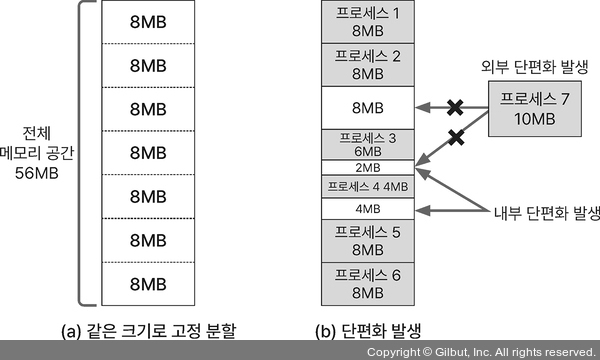
고정 분할 방식
메모리 영역을 분할하고 각 영역에 프로세스 할당 → 단편화 문제
- 외부 단편화: 고정 분할된 영역보다 큰 프로세스
- 내부 단편화: 메모리 공간이 남는 경우
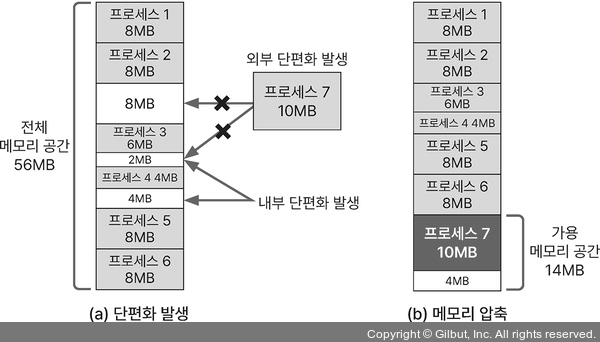
- 메모리 압축: 외부 단편화 문제를 해결하는 방법으로 흩어진 메모리 공간을 하나로 합치는 것
가변 분할 방식
1. 최초 적합
빈 메모리 공간을 차례대로 찾기
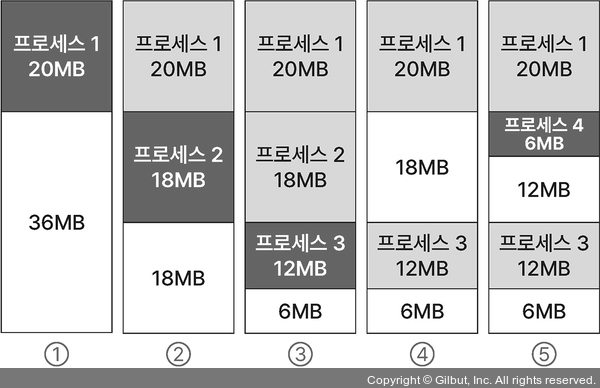
2. 최적 적합
가장 작은 메모리 공간을 찾기
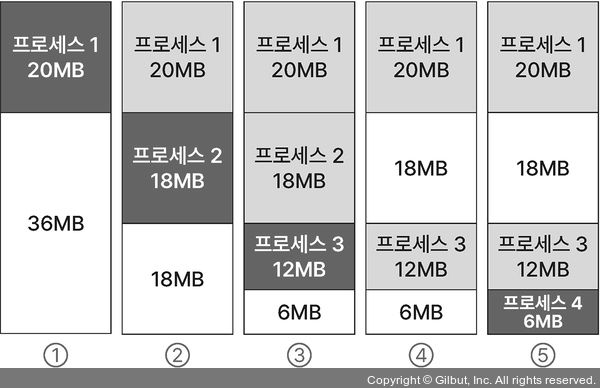
3. 최악 적합
가장 큰 메모리 공간을 찾기
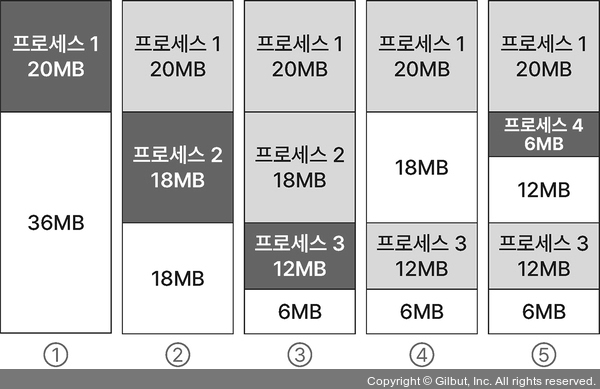
1.4.3 비연속 메모리 할당 (중요도 3)
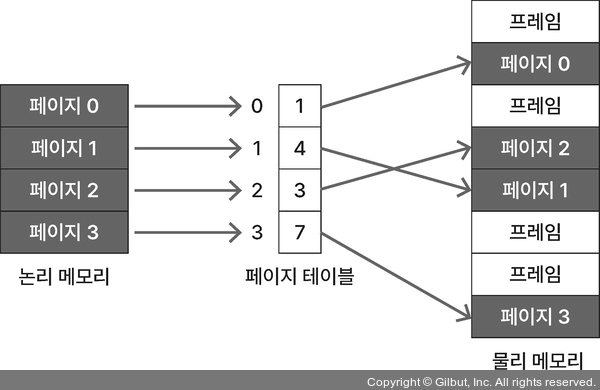
페이징
- 논리 메모리 영역을 페이지, 물리 메모리 영역을 프레임으로 나눔
- 페이지와 프레임의 크기는 동일
- 페이지와 프레임에 번호 할당하여 페이지 테이블로 매핑
- 페이지 테이블은 각 프로세스의 PCB에 저장됨
- 계층적 페이징(멀티레벨 페이징): 페이지 테이블 자체를 다시 페이징
- 해시 페이지 테이블: 가상 주소를 해시 테이블의 인덱스로 변환 → 인덱스는 테이블에서 물리 주소 값을 포함한 버킷 혹은 슬롯을 가리킴
- 역 페이지 테이블: 프레임을 이용해 역으로 페이지를 찾는 방식
장점
- 외부 단편화 문제 해결: 물리 메모리에 연속으로 할당할 필요 X
단점
- 프로세스 크가가 페이지 수로 나누어 떨어지는지 보장 X → 내부 단편화 문제 발생 가능
- 페이지 테이블을 저장할 추가 메모리 공간 필요
세그먼테이션
- 프로세스의 메모리 영역을 논리적 단위인 세그먼트로 분할해 메모리 할당
- 세그먼트 테이블: 세그먼트 번호를 인덱스로 사용, 시작 주소인 base와 길이인 limit가 저장됨
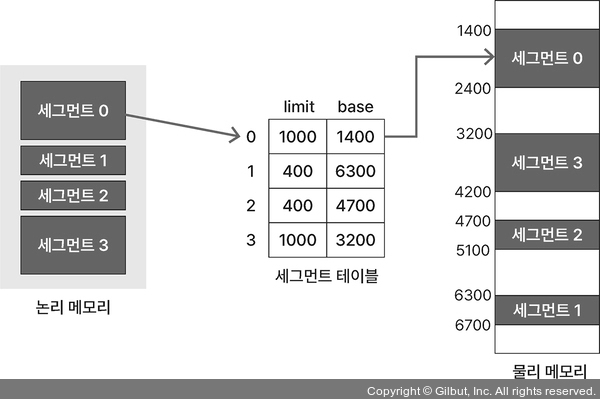
장점
- 단위 별로 데이터를 보호하기 쉬움
단점
- 프로세스 할당/해제를 반복하는 과정에서 외부 단편화 문제 발생
- 스택 세그먼트 영역에서 오버플로 발생 시 다른 프로세스와 메모리 영역이 겹칠 수 있음 → 둘 중 하나의 프로세스를 스왑 아웃해야 함

Someday, the dream will come true