스터디 내용
1.2.1 프로세스와 스레드 (중요도 3)
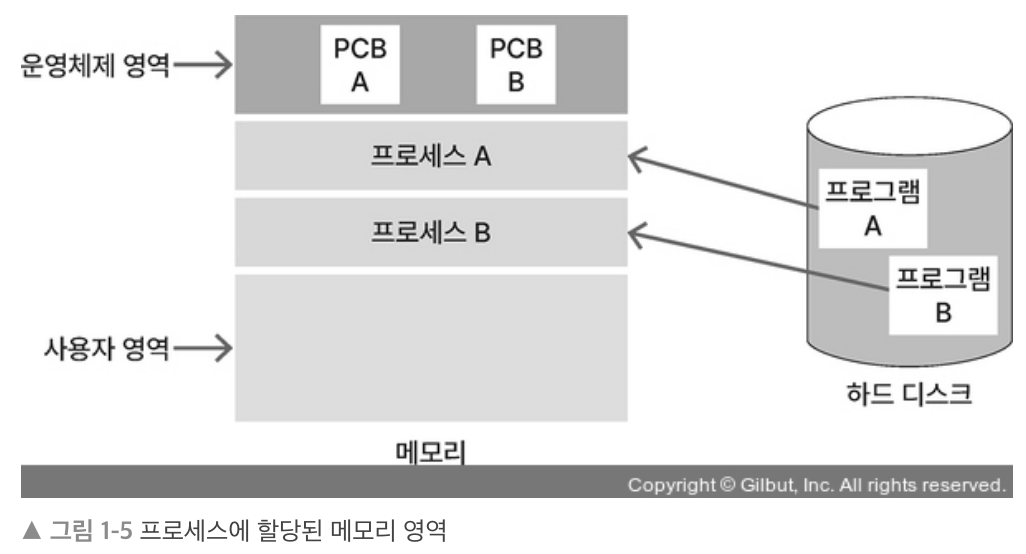
프로세스
- 프로세스: 실행 중인 하나의 프로그램 → 메모리에 올라옴
- 프로그램: 작업 수행하기 위한 명령어의 집합 → 디스크에 저장됨
다음은 프로세스의 메모리 영역 구조이다.
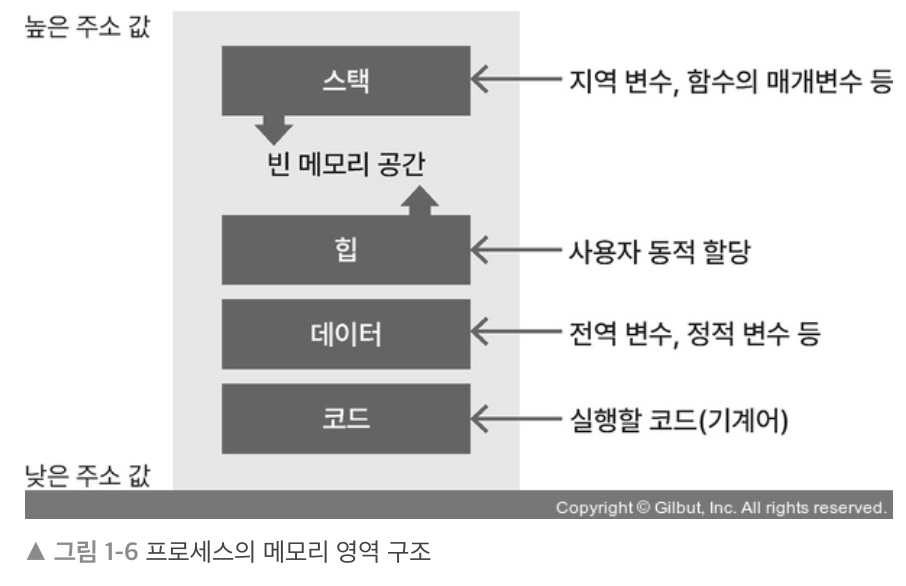
- 스택: 지역 변수, 매개변수, 반환 값 저장, 높은 주소 → 낮은 주소, 컴파일때 영역 크기 결정, LIFO(후입선출)
- 힙: 동적 할당, 낮은 주소 → 높은 주소, 런타임 때 결정, FIFO(선입선출)
- 데이터: 전역 변수, 정적 변수, 배열, 구조체 등이 저장, BSS(초기화 X 변수 저장)와 데이터(초기화 O 변수 저장) 영역으로 다시 나뉠 수 있음
- 코드: 기계어로 컴파일 된 코드가 저장됨
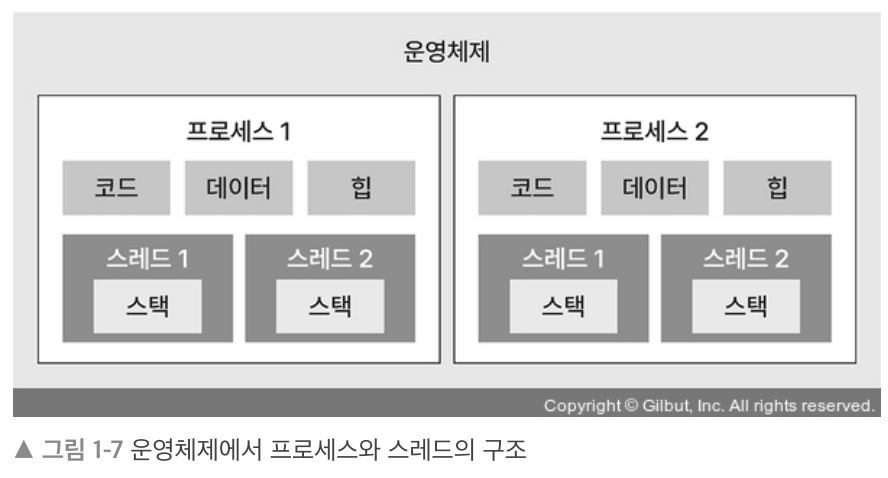
스레드
프로세스에서 실제로 실행되는 흐름의 단위. 스택을 할당 받는다.
사용자 레벨 스레드/커널 레벨 스레드
- 사용자 레벨 스레드: 사용자가 라이브러리를 이용해 생성/관리함
- 커널 레벨 스레드: 커널이 직접 생성/관리함
다대일 모델
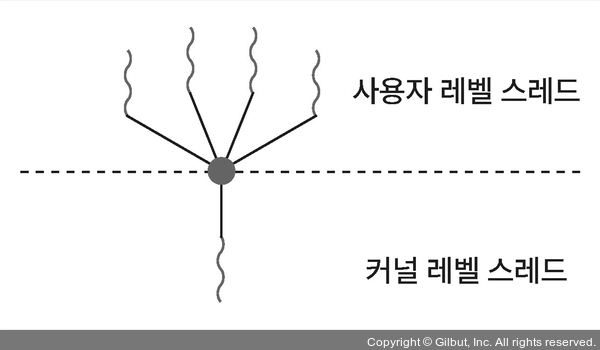
하나의 사용자 레벨 스레드가 시스템 콜을 호출하면 나머지 사용자 레벨 스레드는 커널 레벨 스레드에 접근할 수 없음 → 멀티 코어 병렬성 활용 X
일대일 모델
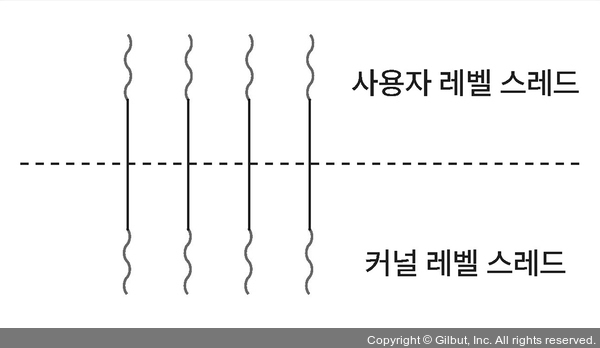
불필요한 커널 레벨 스레드가 생성되므로 성능이 저하됨
다대다 모델
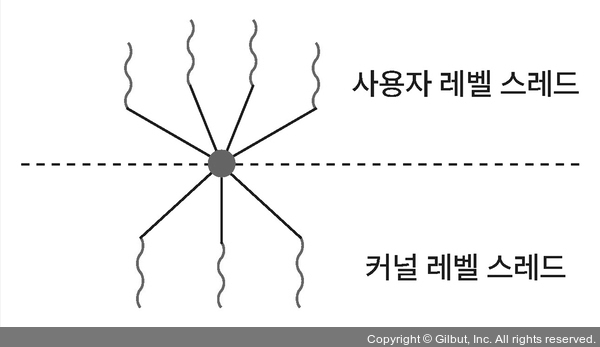
구현이 힘듦
1.2.2 PCB (중요도 2)

1.2.3 프로세스의 생성 (중요도 3)
프로세스 복사 시
- 부모 프로세스: 기존 프로세스
- 자식 프로세스: 복사본 프로세스
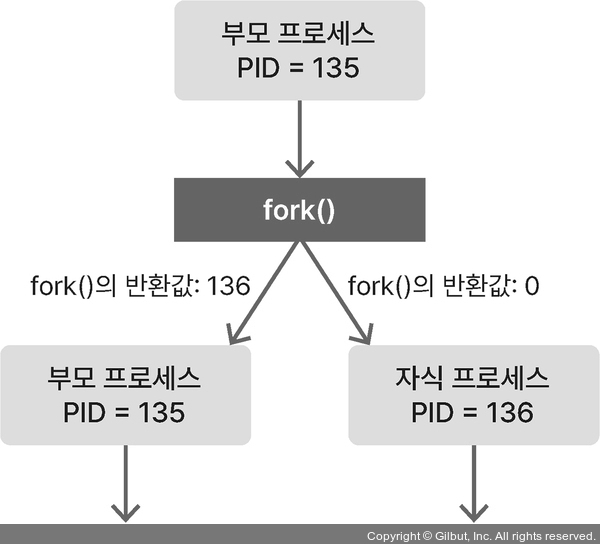
fork() 호출 시 부모 프로세스는 자식 프로세스 PID 값을, 자식 프로세스는 0을 반환한다.
#include <stdio.h>
#include <unistd.h>
int main() {
printf("start!\n");
int forkRet = fork();
if (forkRet == 0) {
printf("child process %d\n", getpid());
} else {
printf("forkRet:%d parent process:%d\n", forkRet, getpid());
}
return 0;
}start!
forkRet:38668 parent process:38667
child process 38668프로세스 종료
- 정상 종료
- 실행/이벤트 대기 시간 초과
- 파일 검색/입출력 실패
- 오류 발생, 메모리 부족
- 자식 프로세스가 자원 초과하면 자식 프로세스 종료시킬 수 있다.
- 자식 프로세스에 할당된 작업이 없을 때 종료시킬 수 있다.
1.2.4 프로세스 상태도 (중요도 3)
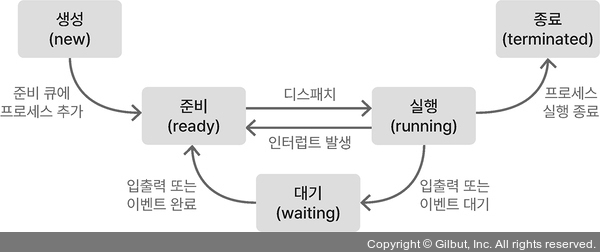
- 생성: 프로세스가 PCB를 가지고 있지만, OS로부터 승인을 받기 전
*승인: CPU 제외한 다른 자원이 준비되어 OS가 해당 프로세스가 준비 상태가 되도록 허락하는 것 - 준비: 준비 큐에서 CPU 할당을 기다림
- 실행: CPU 할당 받아 프로세스 실행
- 대기: 입출력/이벤트 발생 기다림. CPU 사용 멈춤
- 종료: 프로세스 실행 종료
- 생성 → 준비: 프로세스가 OS 승인을 받아 준비 상태 프로세스가 모여있는 준비 큐에 추가됨
- 준비 → 실행: 우선 순위 높은 프로세스가 CPU 자원을 할당받아(디스패치) 실행됨
- 실행 → 준비: CPU 독점 방지하기 위해 timeout
- 실행 → 대기: 입출력/이벤트 대기
- 대기 → 준비: 대기가 완료되어 준비 상태로 변함
- 실행 → 종료: 프로세스 정상 종료
1.2.5 멀티 프로세스와 멀티 스레드 (중요도 3)
- 동시성: 싱글 코어에서 여러 작업을 번갈아 처리
*콘텍스트 스위칭: 처리 중인 작업을 교체하는 것 - 병렬성: 여러 코어에서 각 작업을 동시에 처리
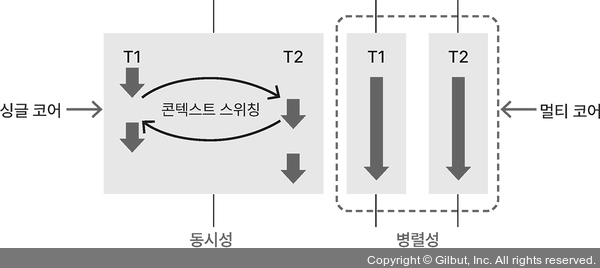
멀티 프로세스
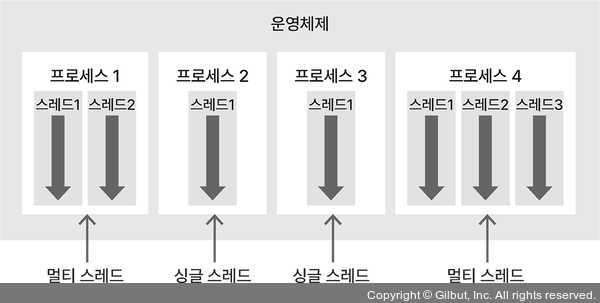
- 응용 프로그램 하나를 여러 프로세스로 구성
- 프로세스끼리는 서로 영향 X → 안정적
- 시간, 메모리 공간 많이 사용: 콘텍스트 스위칭 과정에서 추가 시간, 메모리 필요
- 자원 공유 시 IPC(Inter Process Communication) 필요
import time
from multiprocessing import Process, cpu_count
# 팩토리얼 계산 함수
def factorial(n):
result = 1
for i in range(1, n + 1):
result *= i
return result
# 멀티 프로세스에서 실행할 타겟 함수
def compute_factorials():
factorial(100000)
def single_process():
# 단일 프로세스 실행 시간 측정
start_time = time.time()
results = [factorial(100000) for _ in range(2)] # 팩토리얼 두 번 계산
end_time = time.time()
print(f"Single Process Time: {end_time - start_time} seconds")
def multi_process():
# 멀티 프로세스 실행 시간 측정
start_time = time.time()
processes = []
num_processes = 2 # 동시에 실행할 프로세스의 수
for _ in range(num_processes):
p = Process(target=compute_factorials)
processes.append(p)
p.start()
for p in processes:
p.join() # 모든 프로세스의 종료를 기다림
end_time = time.time()
print(f"Multi Process Time: {end_time - start_time} seconds")
if __name__ == '__main__':
single_process() # 단일 프로세스로 실행
multi_process() # 멀티 프로세스로 실행Single Process Time: 7.751401901245117 seconds
Multi Process Time: 3.926076889038086 seconds멀티 스레드
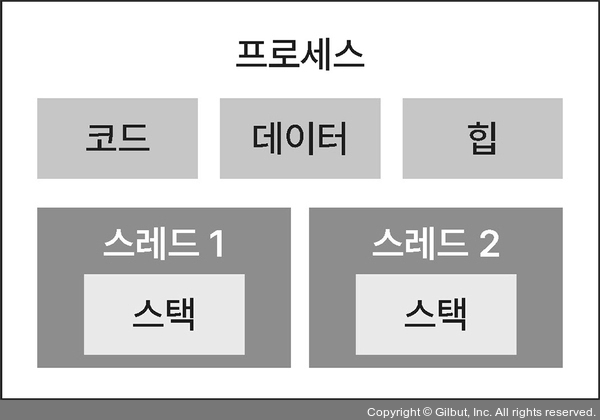
- 스레드를 여러개 생성해 각자 다른 작업 처리
- 멀티 프로세스의 단점을 해결할 수 있음
- 자원 동기화 필요, 스레드 문제 발생 시 다른 스레드에 영향을 미칠 수 있다.
import threading
import time
# CPU 바운드 작업을 수행하는 함수
def cpu_bound_task(n):
return sum(i*i for i in range(n))
def single_threaded(n):
start_time = time.time()
results = []
for _ in range(n):
result = cpu_bound_task(10**7)
results.append(result)
end_time = time.time()
print(f"싱글 스레딩 결과: {sum(results)}, 시간: {end_time - start_time}초")
def multi_threaded(n):
threads = []
results = [0] * n
start_time = time.time()
for i in range(n):
# 각 스레드에 작업 분배
thread = threading.Thread(target=lambda q, idx: q.__setitem__(idx, cpu_bound_task(10**7)), args=(results, i))
threads.append(thread)
thread.start()
for thread in threads:
thread.join() # 모든 스레드의 작업이 끝날 때까지 기다림
end_time = time.time()
print(f"멀티 스레딩 결과: {sum(results)}, 시간: {end_time - start_time}초")
if __name__ == "__main__":
print("싱글 스레딩 실행 중...")
single_threaded(4) # 4번 반복 실행
print("\n멀티 스레딩 실행 중...")
multi_threaded(4) # 4개의 스레드 생성싱글 스레딩 실행 중...
싱글 스레딩 결과: 1333333133333340000000, 시간: 1.877094030380249초
멀티 스레딩 실행 중...
멀티 스레딩 결과: 1333333133333340000000, 시간: 1.8406879901885986초4개 스레드에 작업을 분배해도 시간 차이가 거의 나지 않는다. 그 이유는 이제 설명할 GIL 때문이다.
추가 내용
GIL(Global Interpreter Lock)
파이썬은 컴파일 언어다?
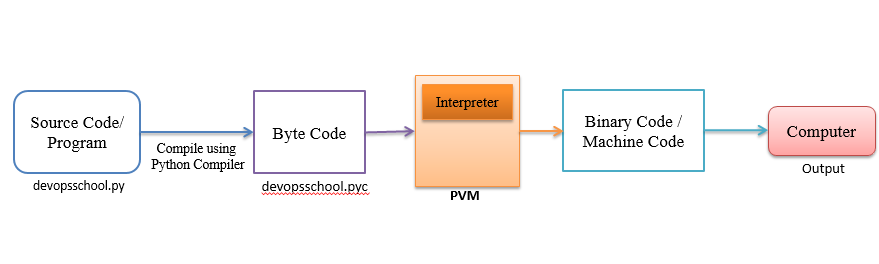
흔히 파이썬을 처음 배울 때 인터프리터 언어라고 배울 것이다. 그리고 인터프리터 언어와 비교하는 개념으로 C와 같은 컴파일 언어가 나온다. 그럼 파이썬은 컴파일 언어일까?
우리가 흔히 사용하는 파이썬은 주로 CPython이다. 그리고 이 CPython은 인터프리터로 파이썬 코드를 그대로 실행하지 않는다. 파이썬 코드가 바이트코드로 바뀌는 컴파일 과정이 이루어진다.
GIL은 한 시점에 단 하나의 스레드만 파이썬 바이트코드를 실행할 수 있도록 하는 락(lock)이다. CPython 인터프리터 내의 코드 실행이 동시에 발생하지 않도록 보장하는 역할을 한다.
Java와 비슷한 파이썬
이전 포스팅에서 JVM 계열 언어와 파이썬의 GC 동작 방식이 유사하다고 했다. 특히 young/old 세대 방식 GC로 살아남은 객체만 살려 놓는 방식은 파이썬에서도 유효하게 동작한다.
파이썬 GC
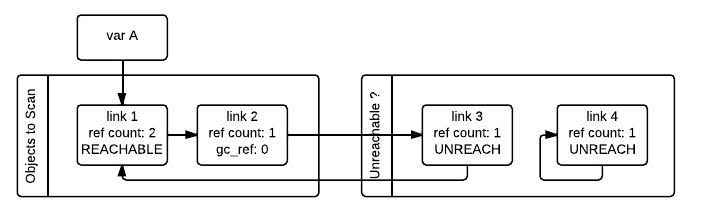
이전 포스팅에서 reference counting 계산 방식 GC를 더 자세하게 설명했다. 다시 요약하자면 파이썬 GC는 자신을 참조하는 객체가 아무도 없어지면(reference count가 0이 되면) GC 대상이 되는데, GIL은 이 과정에서 reference counting이 겹쳐서 일어나지 않도록 조절한다.
GIL 동작 방식
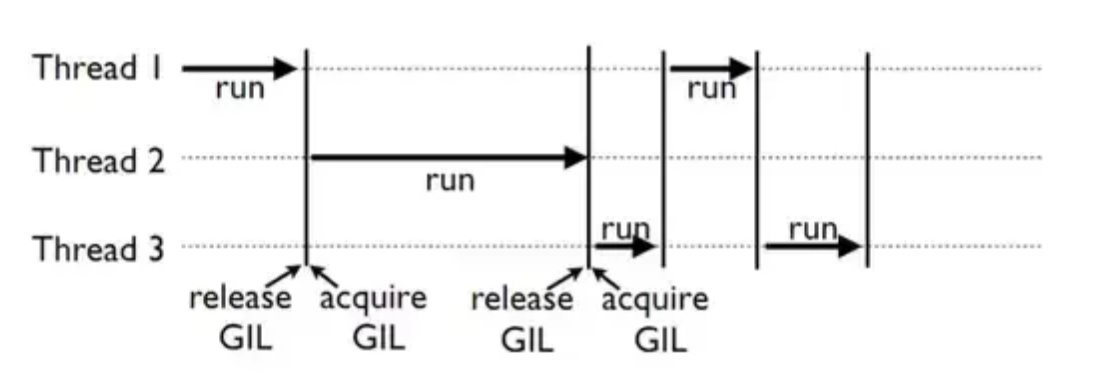
GIL은 단일 락으로 동작한다. 이 락은 스레드가 파이썬 바이트코드를 실행하기 전 획득해야 한다. 만약 스레드가 GIL를 획득한 경우, 다른 스레드는 GIL을 획득할 때까지 실행할 수 없다. 따라서 모든 CPython 바이트코드 실행은 직렬화된다. 일반적으로 스레드가 할당된 시간을 사용하면 GIL를 해제하고 다른 스레드가 실행되도록 한다.
I/O 바운드와 CPU 바운드
I/O 바운드 작업은 입출력에 의해 성능이 결정되는 작업을 의미한다. I/O 작업에 많은 시간을 소모하는 작업이 I/O 바운드 작업이다. I/O 바운드 작업에서는 대부분의 시간이 I/O 작업을 기다리는 데 소비된다. I/O 작업이 진행되는 동안 GIL을 해제하고 다른 스레드가 실행될 수 있으므로 I/O 바운드 상황에서는 GIL의 영향이 상대적으로 덜 민감하다. 이후에 언급할 코루틴이 I/O 바운드 작업을 최적화하기 때문에 독립적으로 작용한다.
CPU 바운드 작업은 CPU 연산에 의해 성능이 결정되는 작업을 의미한다. GIL은 한 시점에 하나의 스레드만이 CPU에서 실행될 수 있도록 한다. 이는 멀티 코어 환경에서도 마찬가지인다. 멀티 코어라고 해도 오직 하나의 스레드만이 실행될 수 있으므로 성능 개선이 이루어지지 않는다.
import time
import threading
import requests
from concurrent.futures import ThreadPoolExecutor
# CPU 바운드 작업
def cpu_bound_task(n):
return sum(i*i for i in range(n))
# I/O 바운드 작업
def io_bound_task(url):
response = requests.get(url)
return response.status_code
# 싱글 스레딩 실행 함수
def run_single_threaded(tasks, task_type):
start_time = time.time()
results = []
for task in tasks:
results.append(task_type(task))
end_time = time.time()
print(f"싱글 스레딩 결과: {len(results)}개, 시간: {end_time - start_time:.2f}초")
# 멀티 스레딩 실행 함수
def run_multi_threaded(tasks, task_type):
start_time = time.time()
with ThreadPoolExecutor(max_workers=4) as executor:
results = list(executor.map(task_type, tasks))
end_time = time.time()
print(f"멀티 스레딩 결과: {len(results)}개, 시간: {end_time - start_time:.2f}초")
if __name__ == "__main__":
n = 10**7
urls = ["https://www.example.com" for _ in range(4)] # 동일한 URL로 4개의 요청
print("CPU 바운드 작업 (싱글 스레딩 vs 멀티 스레딩)")
run_single_threaded([n] * 4, cpu_bound_task)
run_multi_threaded([n] * 4, cpu_bound_task)
print("\nI/O 바운드 작업 (싱글 스레딩 vs 멀티 스레딩)")
run_single_threaded(urls, io_bound_task)
run_multi_threaded(urls, io_bound_task)CPU 바운드 작업 (싱글 스레딩 vs 멀티 스레딩)
싱글 스레딩 결과: 4개, 시간: 1.86초
멀티 스레딩 결과: 4개, 시간: 1.78초
I/O 바운드 작업 (싱글 스레딩 vs 멀티 스레딩)
싱글 스레딩 결과: 4개, 시간: 4.08초
멀티 스레딩 결과: 4개, 시간: 1.15초Jython으로 해결하기
CPython이 아닌 JVM 기반 Jython으로 GIL 문제를 해결할 수 있다. 하지만 이는 서드파티 플러그인 지원이 안되고 최신 파이썬 문법이 적용되지 않을 수 있다.
# -*- coding: utf-8 -*-
from java.util.concurrent import Executors, TimeUnit
from java.net import URL
from java.lang import Runnable
from java.lang import System as JavaSystem
# CPU 바운드 작업
class SumTask(Runnable):
def __init__(self, n):
self.n = n
def run(self):
total = sum(i for i in range(self.n))
print("Sum:", total)
# I/O 바운드 작업
class DownloadTask(Runnable):
def __init__(self, url):
self.url = url
def run(self):
content = URL(self.url).openStream()
content.close()
print("Download completed")
# 작업 실행 함수
def execute_tasks_single_threaded(tasks):
start_time = JavaSystem.currentTimeMillis()
for task in tasks:
task.run()
end_time = JavaSystem.currentTimeMillis()
print("Single Thread:", (end_time - start_time), "ms")
def execute_tasks_multi_threaded(tasks):
executor = Executors.newFixedThreadPool(4)
start_time = JavaSystem.currentTimeMillis()
for task in tasks:
executor.submit(task)
executor.shutdown()
executor.awaitTermination(60, TimeUnit.SECONDS)
end_time = JavaSystem.currentTimeMillis()
print("Multi Thread:", (end_time - start_time), "ms")
if __name__ == '__main__':
# CPU 바운드 작업 비교
print("CPU Bound")
n = 10000000
cpu_tasks = [SumTask(n) for _ in range(4)]
execute_tasks_single_threaded(cpu_tasks)
execute_tasks_multi_threaded(cpu_tasks)
# I/O 바운드 작업 비교
print("\nI/O Bound")
urls = ["http://www.example.com" for _ in range(4)]
io_tasks = [DownloadTask(url) for url in urls]
execute_tasks_single_threaded(io_tasks)
execute_tasks_multi_threaded(io_tasks)메모리 outbound 에러가 발생해 2GB 정도로 할당했다.
(cs_study) chan@gang-gamchan-ui-MacBookPro CS_study % jython -J-Xmx2048m gamchan/jython_bound.py
CPU Bound
('Sum:', 49999995000000L)
('Sum:', 49999995000000L)
('Sum:', 49999995000000L)
('Sum:', 49999995000000L)
('Single Thread:', 7386L, 'ms')
('Sum:', 49999995000000L)
('Sum:', 49999995000000L)
('Sum:', 49999995000000L)
('Sum:', 49999995000000L)
('Multi Thread:', 2481L, 'ms')
I/O Bound
Download completed
Download completed
Download completed
Download completed
('Single Thread:', 1255L, 'ms')
Download completed
Download completed
Download completedDownload completed
('Multi Thread:', 613L, 'ms')코루틴(Coroutine)
코루틴은 코드다
코루틴은 프로그램의 실행 중에 멈췄다가 필요한 시점에 다시 시작할 수 있는 독립적인 코드 블록이며 함수의 일종이다. 코루틴은 yield 키워드를 사용하는 제네레이터의 확장된 형태로 시작되었다. 가장 흔히 사용하는 제네레이터는 range() 이다. range(4)이면 0, 1, 2, 3이 동시에 튀어나오는 것이 아니라 순차적으로 튀어나온다.
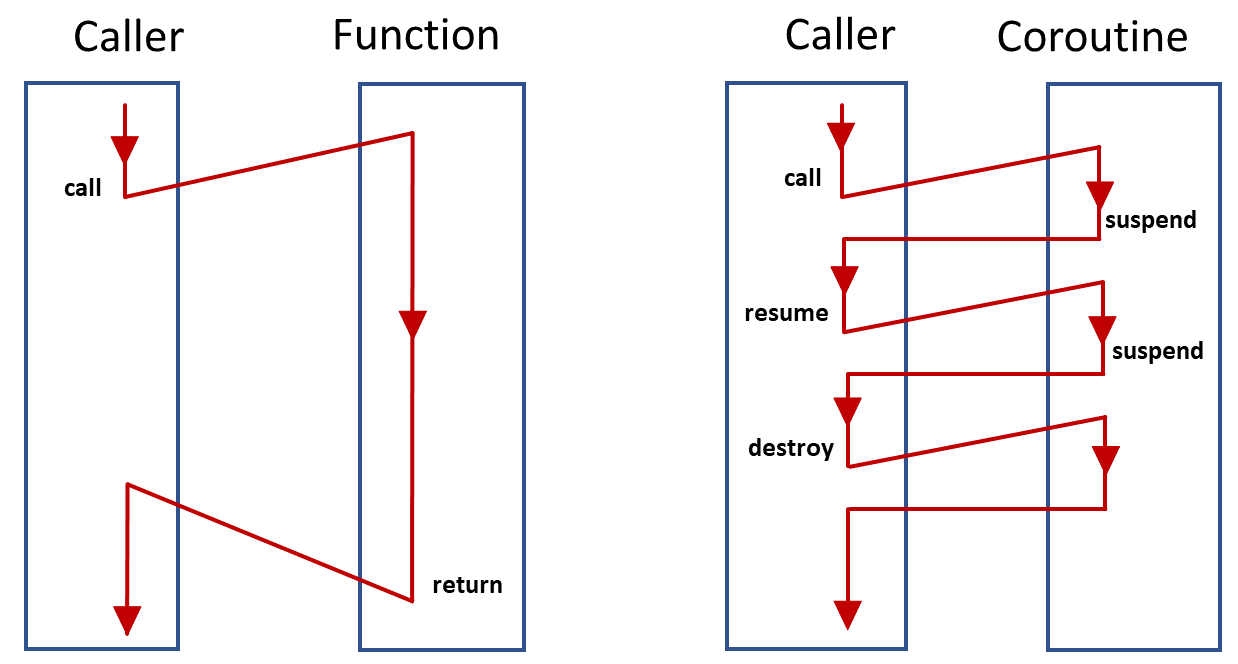
import asyncio
async def async_generator():
for item in range(3):
# 비동기적으로 일정 시간을 기다립니다.
await asyncio.sleep(1)
yield f"Item {item}"
async def main():
# 비동기 제너레이터를 사용합니다.
async for item in async_generator():
print(item)
# 비동기 메인 함수를 실행합니다.
asyncio.run(main())