[Segmentation] FCN : Fully Convolutional Networks for Semantic Segmentation
DeepLearning/MachineLearning
FCN : Fully Convolutional Networks)
Fully Convolutional Networks for Semant ic Segmentation(FCN)은 Semantic Segmentation 문제를 위해 제안된 딥러닝 모델이다.
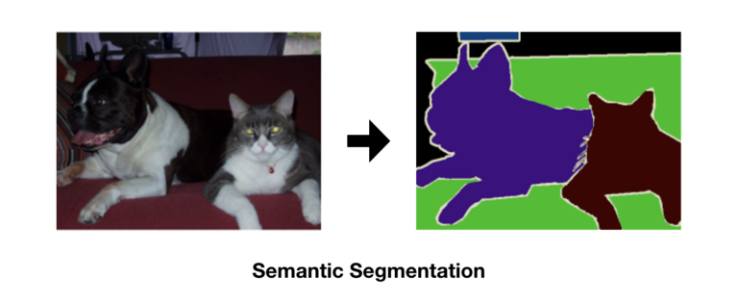
: 입력이미지에 대해 픽셀 단위로 배경 및 각 개체의 클래스를 분할하는 동시에 예측한다.
FCN은 이미지 분류에서 우수한 성능을 보인 CNN 기반 모델(AlexNet, VGG16, GoogLeNet)을
Semantic Segmentation Task를 수행할 수 있도록 변형시킨 것이다.
FCN 네트워크는 이미지 분류 문제를 먼저 트레이닝 시킨 후 모델을 튜닝해 학습하는 Transfer Learning으로 구현한다. 이후 나온 Semantic Segmentation 방법은 대부분 FCN의 아이디어를 기반으로 하였다.
이러한 [Image classification model] to [Semantic segmentation model]은 크게 다음의 세 과정으로 표현할 수 있다.
- Convolution
- Deconvolution (Upsampling)
- Skip architecture
Convolutionalization
Convolutionalization(컨볼루션화)이라는 표현의 의미를 이해하기 위해서는 기존의 이미지 분류 모델들을 먼저 살펴볼 필요가 있다.
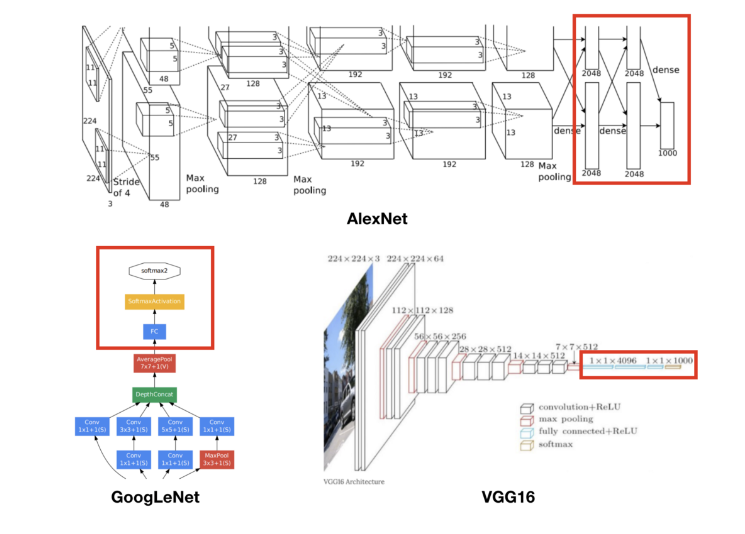
Image classification 모델들은 기본적으로 내부 구조와 관계없이 모델의 근본적인 목표를 위해 출력층이 Fully-connected(이하 fc) layer로 구성되어 있다.
이러한 구성은 네트워크의 입력층에서 중간부분까지 ConvNet을 이용하여 영상의 특징들을 추출하고 해당 특징들을 출력층 부분에서 fc를 이용해 이미지를 분류하기 위함이다.
그런데, Semantic Segmentation 관점에서는 fc layer가 갖는 한계점이 있다.
기존 Classification용 CNN 모델의 문제
- 입력 이미지의 크기가 고정된다.
항상 입력이미지를 네트워크에 맞는 고정된 사이즈로 작게 만들어서 입력해줘야 한다.
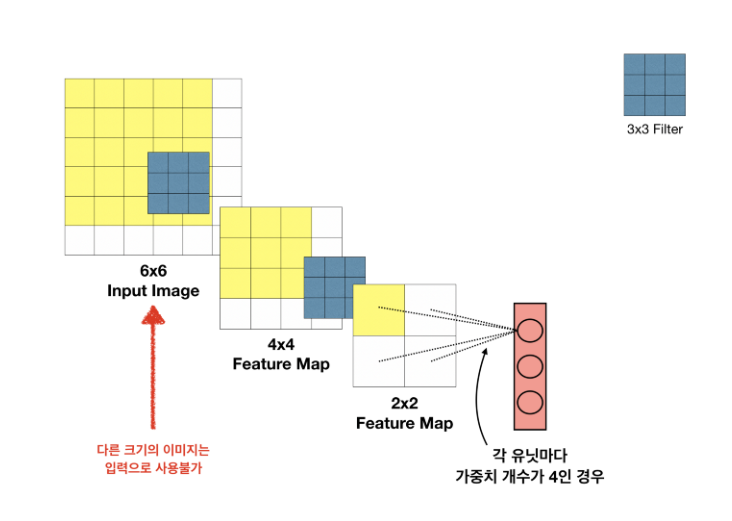
: Dense layer에 가중치 개수가 고정되어 있기 때문에 바로 앞 레이어의 Feature Map의 크기도 고정되며, 연쇄적으로 각 레이어의 Feature Map 크기와 Input Image 크기 역시 고정된다.
- 이미지의 위치 정보가 사라진다.
물체가 어떤 클래스에 속하는 지는 예측해낼 수 있지만, parameter의 개수와 차원을 줄이는 layer들을 가지고 있어서, 자세한 위치정보를 잃게 된다.
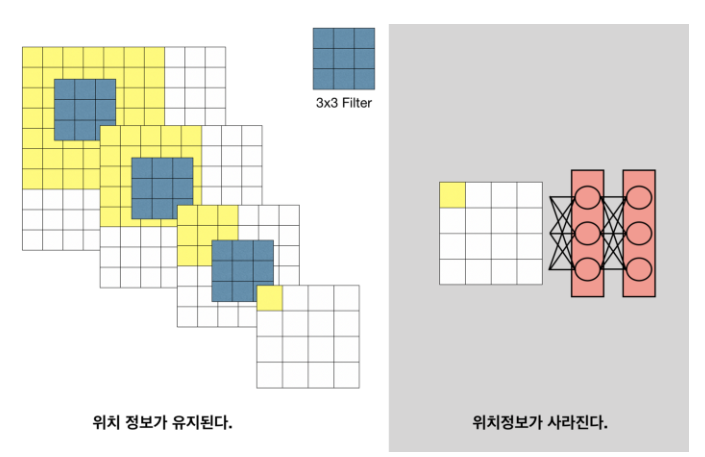
: Fully connected layer 연산 이후 Receptive field 개념이 사라진다.
따라서 이러한 문제를 해결하기 위해, FCN 은 모든 fc-layer를 Conv-layer로 대체하는 방법을 택하였다.
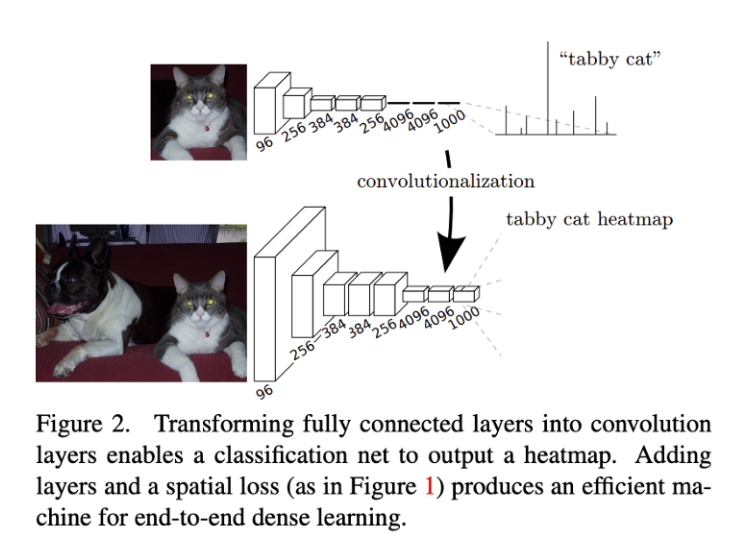
: Fully connected layer는 입력의 모든 영역을 Receptive field로 보는 필터의 Conv layer로 생각할 수 있다.
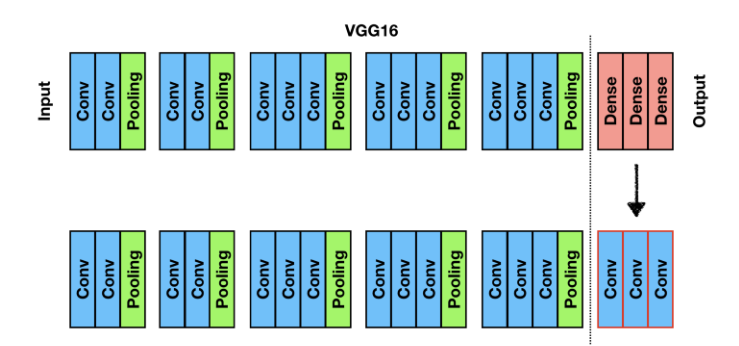
: VGG16
이를 통해,
-
네트워크 전체가 convolution층들로 이루어지게 되며,
-
fully connected 층들이 없어졌으므로, 더 이상 입력 이미지 크기에 제한을 받지 않게 된다.
즉, 이제 어떠한 사이즈(H x W)의 이미지든 네트워크에 입력될 수 있다. -
여러 층의 convolution층들을 거치고 나면, 특성맵(feature map)의 크기가 H/32 x W/32가 되는데, 그 특성맵의 한 픽셀이 입력이미지의 32 x 32 크기를 대표하게 된다.
즉, 입력이미지의 위치 정보를 '대략적으로' 유지하고 있는 것. -
여기서 중요한 것은, 이 convolution 층들을 거치고 나서 얻게 된 마지막 특성맵의 갯수는, 훈련된 클래스의 갯수와 동일하다는 것이다. 5개의 클래스로 훈련된 네트워크라면, 5개의 특성맵(heatmap)을 산출해낸다. 각 특성맵은 하나의 클래스를 대표하고, 만약, 고양이 클래스에 대한 특성맵이라면 고양이가 있는 위치의 픽셀값들이 높고, 강아지 클래스에 대한 특성맵이라면 강아지 위치의 픽셀값들이 높게 산출된다.
Dense -> Conv
Dense layer에서 Conv layer로 변환하는 방식은 다음과 같다.
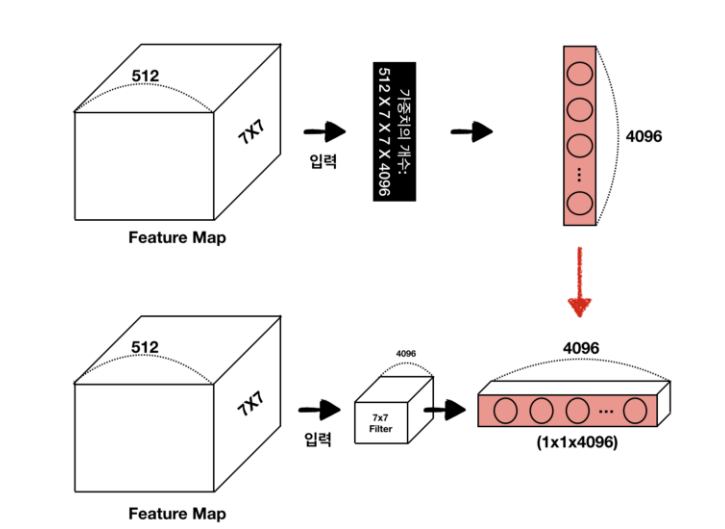
-> 첫번재 fully-connected layer (7x7x512)4096 filter conv로 변경하면 "가중치의 수가 유지된다."
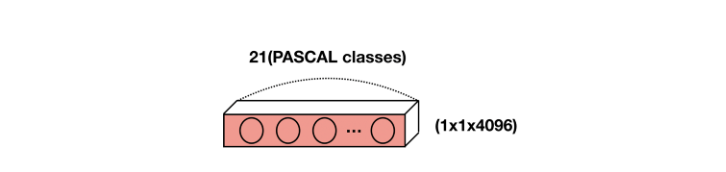
-> 마지막 fully-connected layer의 경우, 채널 차원을 클래스 수에 맞춘 1x1 conv로 변환한다.
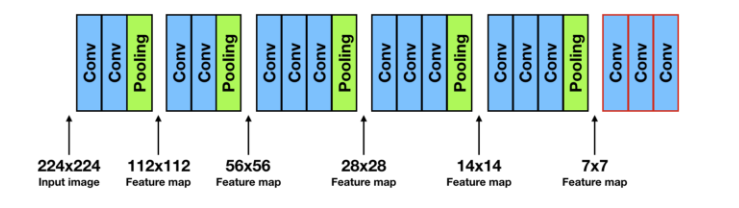
-> VGG16에서 다섯번째 max-polling (size: 2x2, stride: 2) 연산 후, feature map의 크기는 7x7이 된다. (입력이미지의 크기가 224x224인 경우)
Convolutionalization을 통해 출력 Feature map은 원본 이미지의 위치 정보를 내포할 수 있게 된다.
그러나 Semantic segmentation은 최종 목적인 픽셀 단위 예측과 비교했을 때, FCN의 출력 Feature map은 너무 coarse(거친, 알맹이가 큰)하다.
따라서, Coarse map을 원본 이미지 크기에 가까운 Dense map으로 변환해줄 필요가 있다. 적어도 input image size * 1/32보다는 해상도가 높을 필요가 있다.
Deconvolution
Coarse map에서 Dense map을 얻는 몇가지 방법이 있다 :
- Interpolation
- Deconvolution
- Unpooling
- Shift and stitch
-> Pooling을 사용하지 않거나, Pooling의 stride를 줄임.
이렇게 되면, Feature map의 크기가 작아지는 것을 처음부터 피할 수도 있고, 이 경우 필터가 더 세밀한 부분을 볼 수 있지만,
Receptive Field가 줄어들어 이미지의 Context를 놓치게 된다.
또한, Pooling의 중요한 역할 중 하나는 Featuremap의 크기를 줄임으로써 학습 파라미터의 수를 감소시키는 것인데, 이러한 과정이 사라지면 파라미터의 수가 급격히 증가하고, 이로 인해 많은 학습시간을 요구하게 된다.
따라서, Coarse Feature map을 Dense map으로 Upsamping하는 방법을 고려해야한다.
Bilinear Interpolation
10x10 이미지를 320x320 이미지로 확대하기 위한 대표적인 방법이 Bilinear Interpolation이다. Bilinear Interpolation을 이해하기 위해서는 Linear Interpolation을 우선적으로 이해할 필요가 있다.
다음의 두 값을 예측해보자.
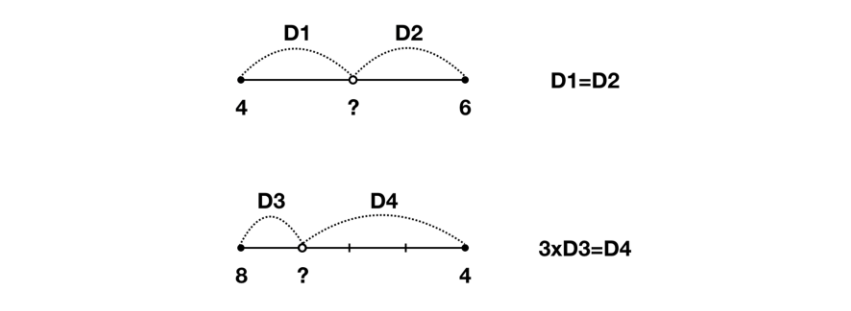
위의 값은 5, 아래 값은 7임을 어렵지 않게 예측할 수 있다.
이처럼 두 지점 사이의 값을 추정할 때 직관적으로 사용하는 방법이 "Linear interpolation"이다.
위의 추정 방식은 다음과 같이 식으로 표현할 수 있다.
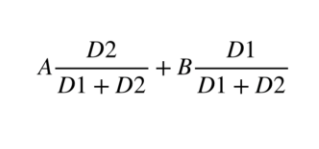
계산하면 다음과 같다.

-> 4(1/2)+6(1/2) = 2+3 = 5

-> 8(3/4)+4(1/4) = 6+1 = 7
Bilinear Interpolation은 이러한 1차원의 Linear Interpolation을 2차원으로 확장한 것이다.
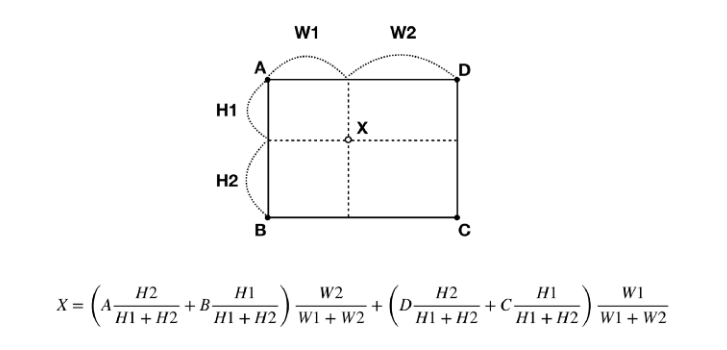
-> 네 지점 A,B,C,D 사이의 임의의 점 x를 추정할 수 있다.
이제 다음과 같은 Feature map이 빈 영역을 추정할 수 있다.
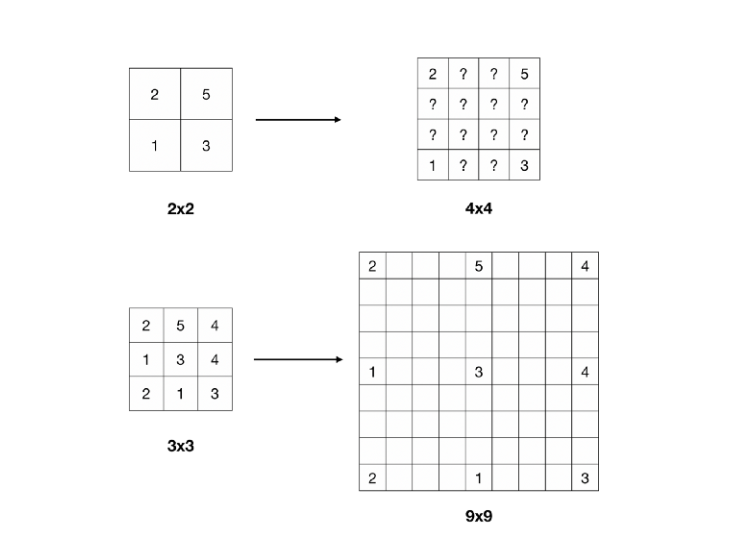
Backwards convolution
Dense prediction을 위한 Upsampling 방법에는 Bilinear interpolation처럼 정해진 방법만 있는 것은 아니다. 즉, Up-sampling도 학습이 가능하다.
Stride가 2 이상인 Convolution 연산의 경우 입력 이미지에 대해 크기가 줄어든 Feature map을 출력한다. 이것은 Down-sampling에 해당한다.
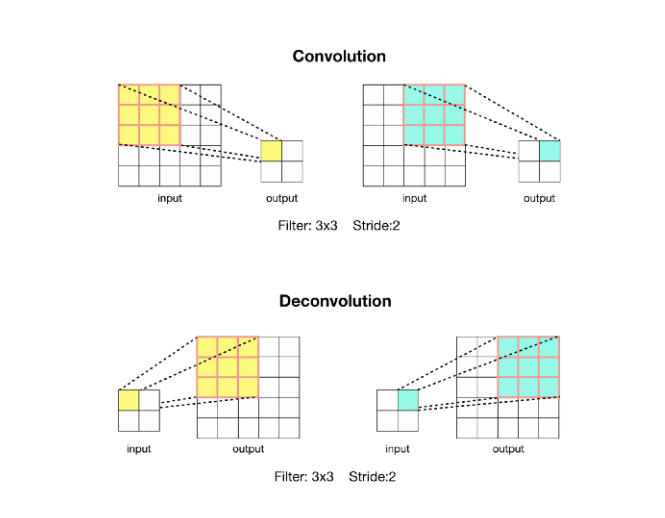
Convolution 연산을 반대로 할 경우(Deconvolution), 자연스럽게 Up-sampling효과를 볼 수 있다. 또한, 이때 사용하는 Filter의 가중치 값은 학습 파라미터에 해당한다.
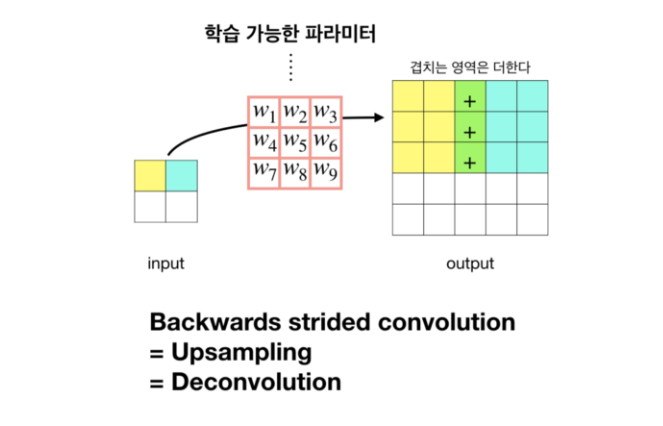
FCNs에서는 Bilinear Interpolation과 Backwards convolution 두 가지 방법을 사용하여 Coarse Feature map으로부터 Dense prediction을 구했다.
초기 Segmentation을 위한 모델은 다음과 같이 VGG 모델을 convolutionalization한 구조에 Bilinear Interpolation 작업을 더함으로써 얻을 수 있다.
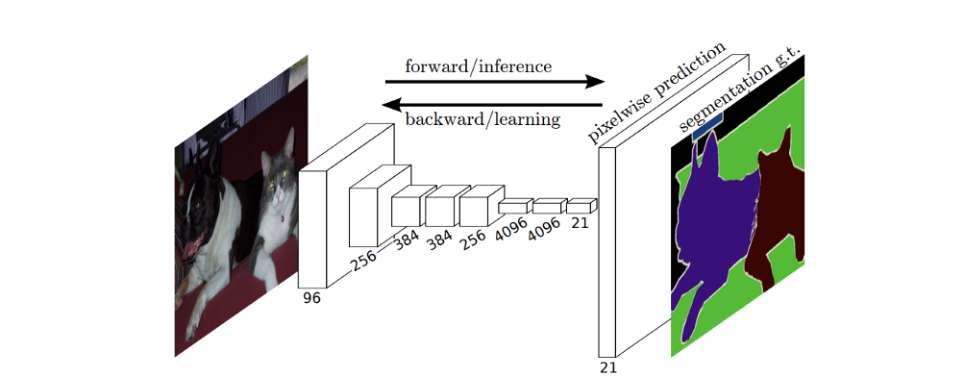
-> 마지막 layer에 Up sampling 연산을 추가해 Dense prediction을 처리함.
이처럼, Interpolation을 통해 Coarse map에서 dense map을 도출할 수 있었지만, 근본적으로 feature map의 크기가 너무 작기 때문에, prediction된 dense map의 정보는 여전히 거칠 수 밖에 없다.
Architecture of FNCs
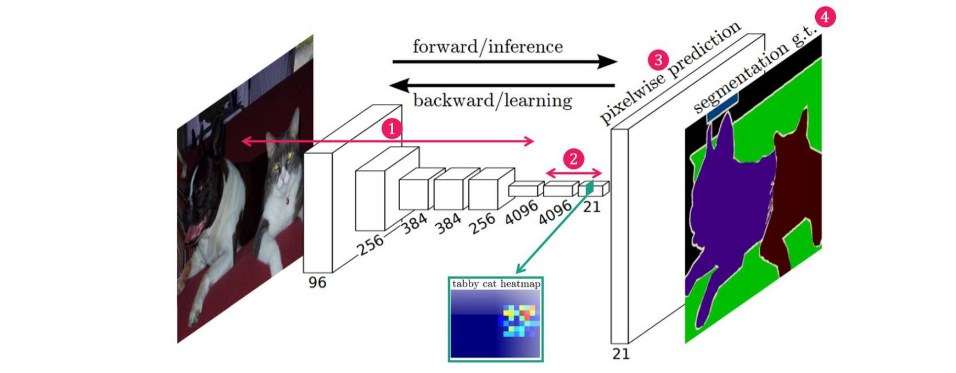
FCN의 architecture는 크게 4단계로 구성된다.
- Convolution layer를 통해 Feature 추출
- 1x1 Convolution layer를 통해, 낮은 해상도의 Class Presence Heat Map 추출
- Transposed Convolution을 통해, 이 낮은 해상도의 Heat Map을 Upsampling한 뒤, Input과 같은 크기의 Map 생성
- Map의 각 pixel class에 따라 색칠한 뒤, Segmentation 결과 반환
-
1, 2 과정은 downsampling 단계로, convolution을 통해 차원을 줄이는 단계이다.
-
3번 과정은 upsampling 단계로, 1,2번 과정을 통해 만들어진 Feature map(heatmap)의 크기를 원래 이미지의 크기로 다시 복원해주는 단계이다.
(이미지의 모든 픽셀에 대해서 클래스를 예측하는 것이, semantic segmentation의 목적이기 때문) -
4번 과정은 upsampling된 특성맵(heatmap)들을 종합해서, 최종적인 segmentation map을 만드는 단계이다.
간단히 말해서, 각 픽셀당 확률이 가장 높은 클래스를 선정해주는 것.
만약, 클래스가 5개이며, (1, 1) 픽셀에 해당하는 클래스당 확률값들이 강아지 0.45, 고양이 0.94, 나무 0.02, 컴퓨터 0.05, 호랑이 0.21 라면, 0.94로 가장 높은 확률을 산출한 고양이 클래스를 (1, 1) 픽셀의 클래스로 예측하는 것이다.이런 식으로 모든 픽셀이 어느 클래스에 속하는지 판단한다.
위 방식의 한계점
그런데 단순히 upsampling을 시행하면, feature map의 크기는 한 번에 원래 이미지의 크기로 복원되고, 그것들로부터 원래 이미지 크기의 segmentation map을 얻을 수 있지만, 디테일하지 못한 segmentation map을 얻게 된다.
1/32만큼 줄어든 feature map들을 한 번에 32배만큼 upsampling 했기 때문에, 당연히 coarse할 수 밖에 없다.
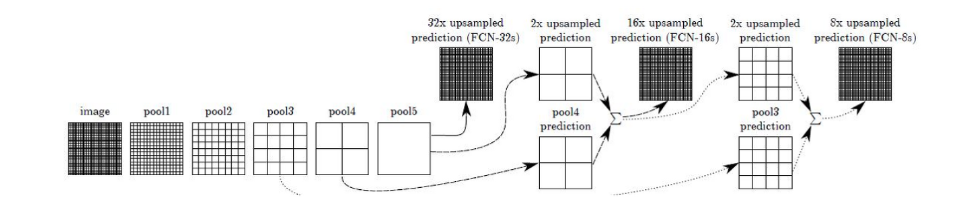
EX) 한 번에 32배 upsampling하는 방법 -> FCN-32s
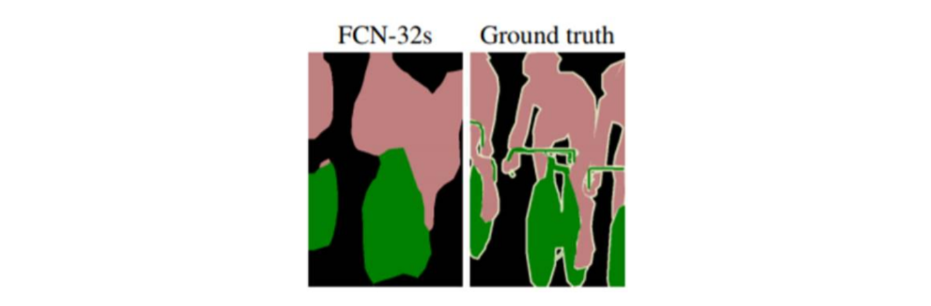
-> ground truth와 비교해, FCN-32s로 얻은 segmentation map은 많이 뭉뚱그려져있고, 디테일하지 못함.
새로 제안하는 방법: Skip combining
기본적인 생각은 다음과 같다.
Convolution과 Pooling 단계로 이루어진 이전 단계의 Convolution 층들의 Feature map을 참고하여 Upsampling을 해주면, 좀 더 정확도를 높일 수 있지 않겠냐는 것이다.
왜냐하면, 이전 Convolution 층들의 Feature map들이 해상도 면에서는 더 낫기 때문이다.
따라서, 바로 전 Convolution 층의 Feature map(pool4)과 현재 층의 Feature map(conv7)을 2배 Upsampling한 것을 더한다.
FCN-16s
그 다음 (pool4 + 2 x conv7)을 16배 Upsampling 해 얻은 Feature map들로 segmentation map을 얻는 방법을 FCN-16s라고 부른다.

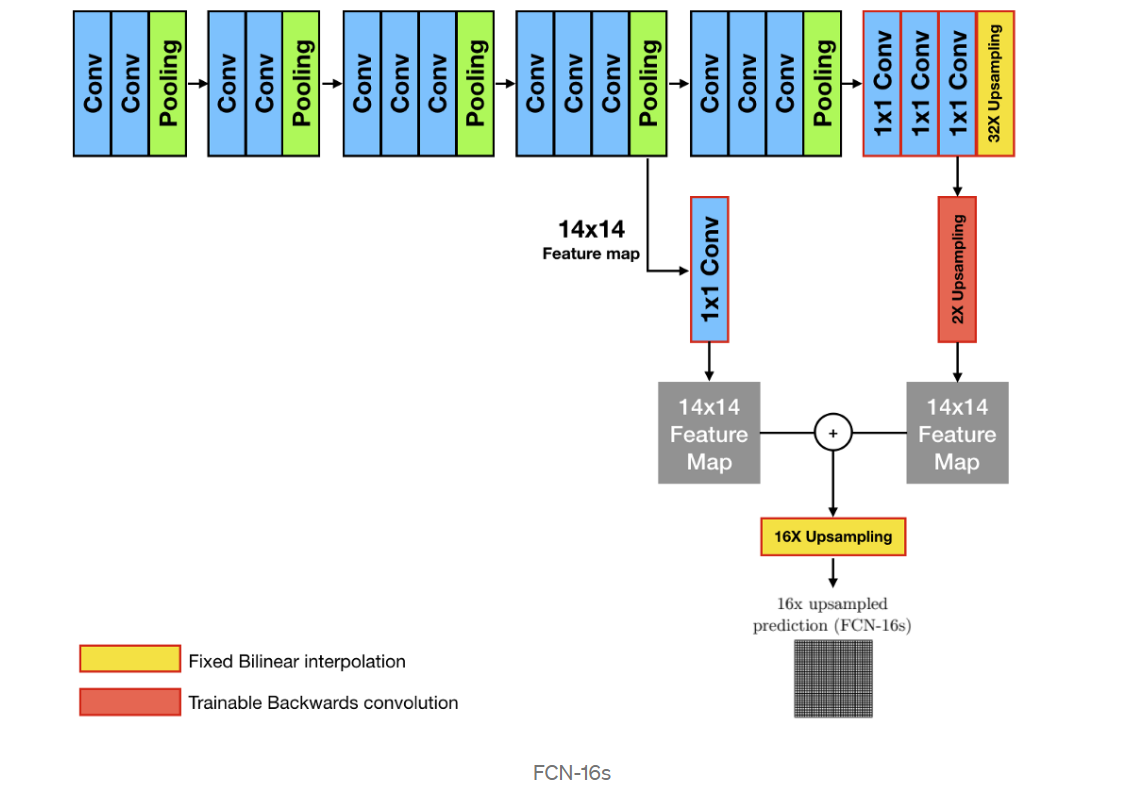
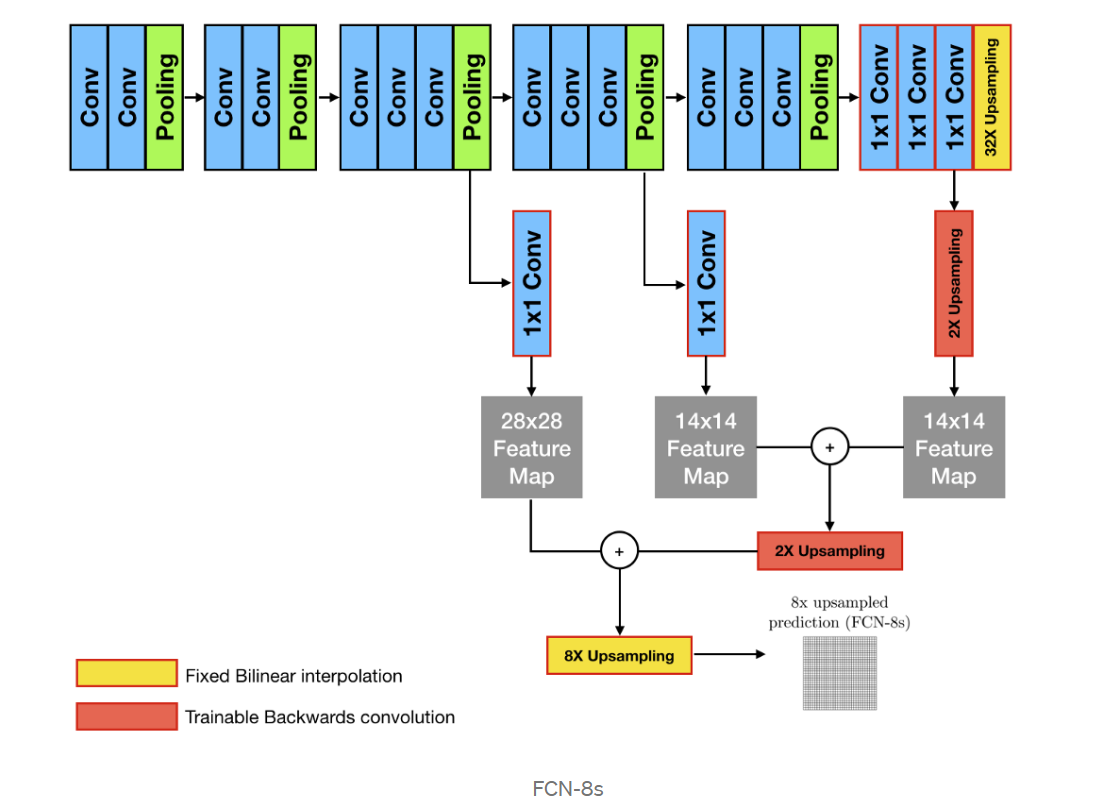
FCN-8s
더 나아가서, 전전 단계의 Feature map(pool3)과, 전 단계의 Feature map(pool4)을 2배 upsampling한 것과, 현 단계의 특성맵(conv7)을 4배 upsampling 한 것을 모두 더한 다음에,
(pool3 + 2xpool4 + 4xcon7)을 8배 upsampling을 해 얻은 Feature map들로 segmentation map을 얻는 방법을 FCN-8s라고 부른다.
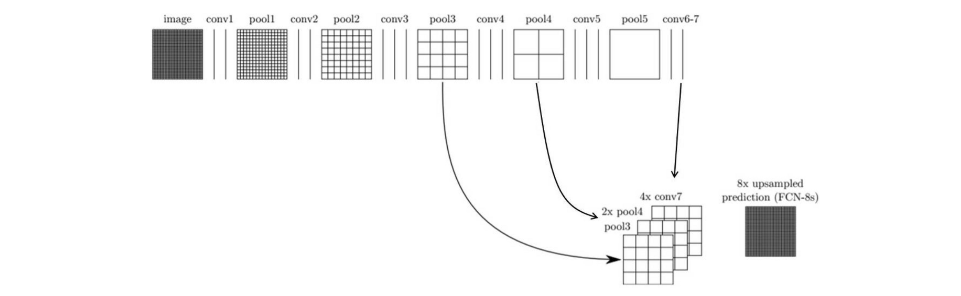
FCN-32s, FCN-16s, FCN-8s 그림
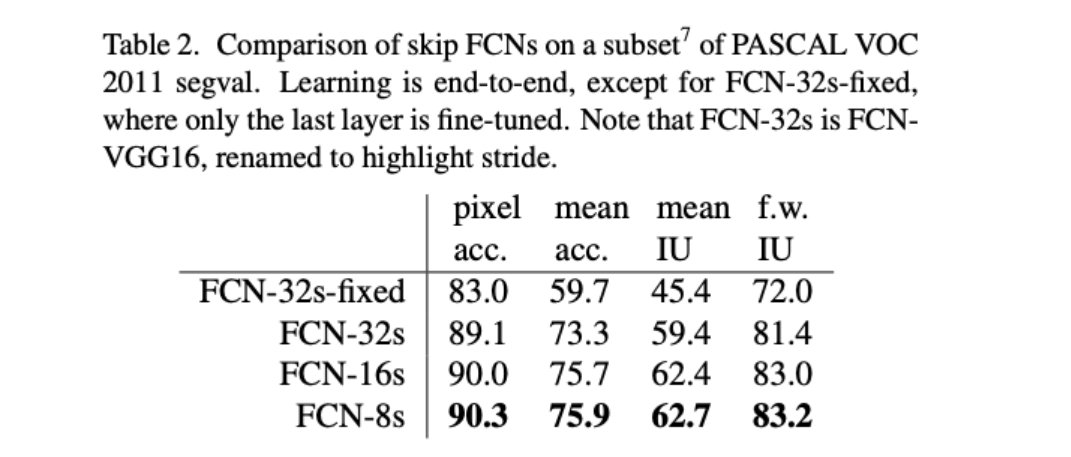
아래 그림을 보면, FCN-8s가 FCN-16s보다 좀 더 세밀하고, FCN-32s보다는 훨씬 더 정교해졌음을 알 수 있다.
다른 논문에서, 또는 웹상에서 누군가 FCN을 말할 때는 보통 이 FCN-8s를 의미한다고 봐도 무방하다.

실제 성능 지표에서도 FCN-32s, > FCN-16s > FCN-8s 순으로 결과가 좋아진다.

정리
FCNs은 기존의 딥러닝 기반 이미지 분류를 위해 학습이 완료된 모델의 구조를 Semantic Segmentation 목적에 맞게 수정하여 Transfer learning 하였다.
Convolutionalized 모델을 통해 예측된 Coarse map을 원본 이미지 사이즈와 같이 세밀(Dense)하게 만들기 위해 Up-sampling을 수행하였다.
또한 Deep Neural Network에서 얕은 층의 Local 정보와 깊은 층의 Semantic 정보를 결함하는 Skip architecture를 통해 보다 정교한 Segmantation 결과를 얻을 수 있었다.
FCNs은 End-to-End 방식의 Fully-Convolution Model을 통한 Dense Prediction 혹은 Semantic Segmentation의 초석을 닦은 연구로써 이후 많은 관련 연구들에 영향을 주었다.
References
