[모두를 위한 딥러닝] #01-03. ML 용어 정리 및 Simple linear regression_2022.05.02
Deep Learning Zero To All
목록 보기
1/13

Lec 01 . 기본적인 Machine Learning의 용어와 개념 설명
머신러닝이란
학습하는 방법에 따른 분류
- SUPERVISED LEARNING
레이블이 정해져있음 = 학습 데이터 - UNSUPERVISED LEARNING
레이블이 정해져있지 않음
일일히 우리가 레이블 주기 어려운 경우가 있음,
또는 비슷한 단어들이 모아져있고 그에 대해 학습하는 경우 = 인공지능 모델이 데이터를 보고 스스로 학습.
supervised learning은 크게 두가지 문제로 분류된다.
regression (시험 점수 예측)
x = input, y = output

classification (binary, multi)
x = input, y = output

Lec 02 . Simple Liner Regression
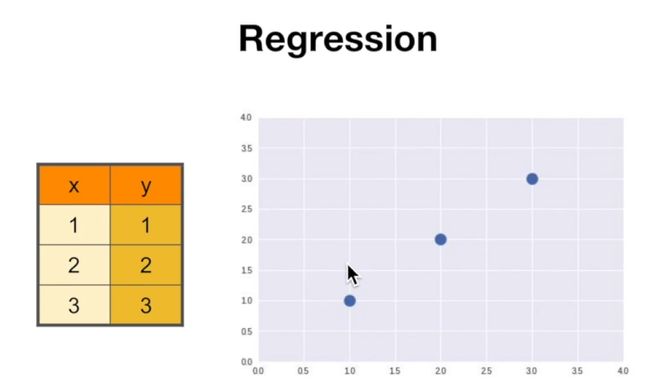
Regression
후퇴 아님, 전체 평균을 가장 잘 나타내는 값
Linear Regression
데이터를 가장 잘 설명할 수 있는 직선
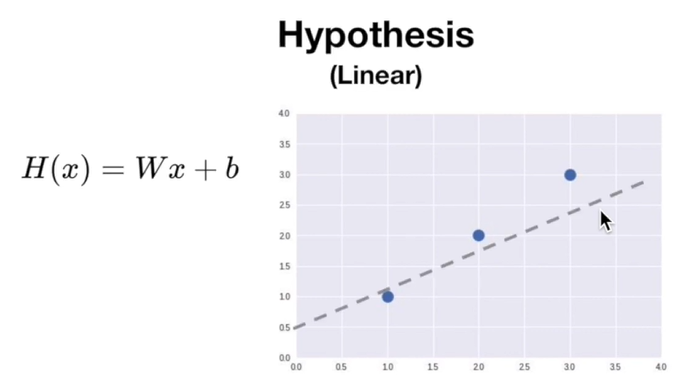
Hypothesis
말 그대로 가설
데이터를 가장 잘 설명할 수 있는 직선에 대한 가상의 직선 방정식
Which hypothesis is better?
방정식의 다름을 결정하는 즉 방정식을 결정하는 인자는 W, b일 때, 어떤 값이 가장 적합한지 어떻게 정할 수 있을까?
Cost, Cost function
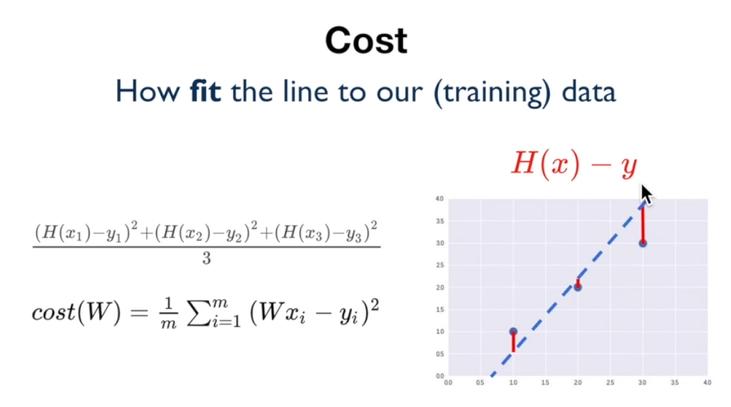
cost = loss = error
이를 최소화하는 것이 cost function의 목적.
cost 의 총합= 최소화시켜야 되는 값.
cost 의 총합을 계산하는 것의 문제점 :
단순 총합에는 음수와 양수가 섞여있어 다 더했을 때 총 손실값이 0이 되는 문제가 발생함.
그래서 cost function에는 "각 손실에 대한 제곱"값을 넣어줌
보편적으로 사용되는 손실함수 = cost(W)

w = 손실
y = 실제 데이터
Goal : Minimize cost
학습 = cost 를 minimize하는 과정
Lab-02 Simple Liner Regression LAB
Build hypothesis and cost 실습
cost 함수 최소화 알고리즘
Gradient descent
cost가 최소화되는 W, b를 찾는 알고리즘이다.
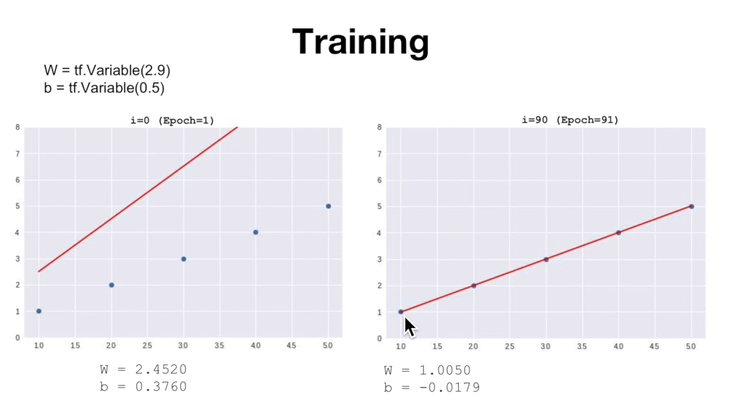
상식적으로 W = 1에, b = 0에 가까워져야한다.
그래디언트 디센트의 업데이트 과정을 직접 도출해봄으로써, 후반으로 갈 수록 W = 1, b = 0에 가까워지는 것을 확인할 수 있다.

with tf.GradientTape() as tape:
=> 의미 : 미분값을 계산한 후 tape에 저장
Learning_rate: 미분값 계산하는 과정을 얼마나 반영할 것인지에 대한 지표

training
predict

Today What I Learned
- tensorflow 의 tensor의 기초함수를 다루는 데에 익숙해짐.
- machine learning의 기본적인 개념, 학습 분류(regression, classification)에 대한 개념을 재정비하는 시간을 가짐.
- 현재 갖춰진 다양한 loss function의 기반이 되는 hypothesis와 cost function을 직접 코드로 구현해보고 손실값이 수렴하는 것을 직접 관찰하면서, loss function을 단순히 api 만 가져다 썼던 것에서 좀 더 원리를 체감할 수 있었음.

veloger