# 1. AutoGrad & Optimizer
[부제] 클래스 torch.nn.Module
- 공식 Documentation https://pytorch.org/docs/stable/generated/torch.nn.Module.html
- 정의
모든 딥러닝을 구성하는layer의Base Class다. (Base class for all neural network modules.)- 역할
Input,Output,Forward,Backward, 그리고 학습의 대상이 되는parameter(Tensor)를 정의할 수 있다. (Custom Dataset 만들기 가능!)
- CustomModel 구조
nn.Module상속받아, 오버라이딩 가능
- ❗
__init()함수에서는,weight,bias,gradient등 parameters 계산에 사용할 수식 커스텀 가능- ❗
forward()함수에서는, 모델 Output으로 나올 예측 값 계산 적용 가능
(✨forward()함수의 return 값은 결국,y hat)
backward()함수도 오버라이딩 가능optimize함수도 오버라이딩 가능- (But, PyTorch의 장점 중 하나는
Autograd개념이므로, 실제로 커스텀하는 일은 거의 없음)
- (➕ ❓
Autograd원리?
https://velog.io/@euisuk-chung/%ED%8C%8C%EC%9D%B4%ED%86%A0%EC%B9%98-%ED%8C%8C%EC%9D%B4%ED%86%A0%EC%B9%98-%EA%B8%B0%EC%B4%88-%EC%9A%94%EC%86%8C-Autograd%EB%9E%80)
class 커스텀모델(nn.Module):
## [1번] __init__() 함수
def __init__(self, dim, lr=torch.scalar_tensor(0.01)):
super(커스텀모델, self).__init__()
## 의미: 현재 커스텀모델에서 정의한 인자 외의 인자들이 있다면, 부모클래스인 nn.Module에서(self) 알아서 잘 받아와라
## 생략하고 super().__init__() 로만 작성해도 됨.
# intialize parameters
self.w = torch.zeros(dim, 1, dtype=torch.float).to(device) # 가중치 계산에 사용할 수식
self.b = torch.scalar_tensor(0).to(device) # 편향 계산에 사용할 수식
self.grads = {"dw": torch.zeros(dim, 1, dtype=torch.float).to(device),
"db": torch.scalar_tensor(0).to(device)}
self.lr = lr.to(device) # 미분에 사용할 Gradient 커스텀 정의
## [2번] forward() 함수
def forward(self, x):
# compute forward
z = torch.mm(self.w.T, x) + self.b
a = self.sigmoid(z)
return a
def sigmoid(self, z):
return 1/(1 + torch.exp(-z))
## [추가] backward() 함수
## 미분 값 선언
def backward(self, x, yhat, y):
# compute backward
self.grads["dw"] = (1/x.shape[1]) * torch.mm(x, (yhat - y).T)
self.grads["db"] = (1/x.shape[1]) * torch.sum(yhat - y)
## [추가] optimize() 함수
## 미분에 대한 Update 값 선언
def optimize(self):
# optimization step
self.w = self.w - self.lr * self.grads["dw"]
self.b = self.b - self.lr * self.grads["db"][추가] Buffer
- Parameter로 지정하지 않아서 gradient 계산 값이 업데이트 되지 않는다 해도 저장하고싶은 tensor가 있을 경우
- ➡️ buffer에 tensor 등록!
- ➡️ 모델을 저장할때 Parameter뿐만 아니라 buffer로 등록된 tensor들도 같이 저장된다!
- 비교
- "Tensor"
- ❌ gradient 계산
- ❌ 값 업데이트
- ❌ 모델 저장시 값 저장
- "Parameter"
- ✅ gradient 계산
- ✅ 값 업데이트
- ✅ 모델 저장시 값 저장
- "Buffer"
- ❌ gradient 계산
- ❌ 값 업데이트
- ✅ 모델 저장시 값 저장
- "Tensor"
(But, Custom 모델을 만들때 대부분 torch.nn에 구현된 layer들을
가져가다 사용하기 때문에 Parameter를 직접 다뤄볼 일은 매우 드물다.)
# 2. Dataset & Dataloader
- 전체 Flow
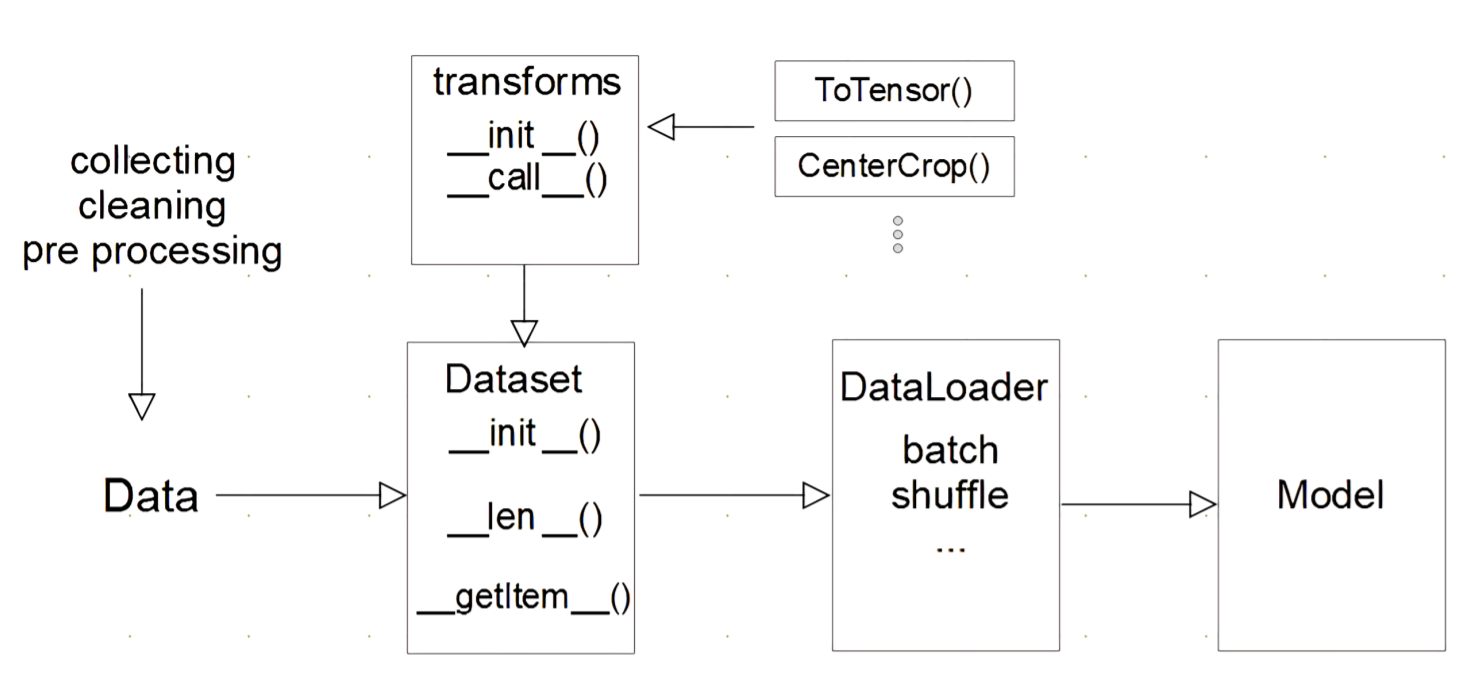
transforms함수에서 전처리, 텐서 변환 등 정의- (➕ Tensor로 변환해주는
ToTensor()는transforms함수 내에서 정의한다.)
Dataset함수는 하나의 데이터셋 파일을 넘겨주는 역할
DataLoader는Dataset에서 받아온 데이터를 batch size만큼 묶어서 모델에 feeding(먹이는) 역할- (
shuffle,sampler등 인자 추가 가능)
[1] Dataset
import torch
from torch.utils.data import Dataset, DataLoader
class CustomDataset(Dataset):
def __init__(self, text, labels):
self.labels = labels
self.data = text
## 경로도 설정 가능 (이미지 분야에서 많이 사용)
def __len__(self):
return len(self.labels)
def __getitem__(self, idx):
label = self.labels[idx]
text = self.data[idx]
## 추가 가능 - transform 활용할 시
# if self.transform:
#im = self.transform(im)
sample = {"Text": text, "Class": label}
return sample- [2] DataLoader
- Data의 Batch를 생성해주는 클래스
- data를 불러와서 GPU에 Feeding하는 학습 진전에 데이터를 변환하는 과정입니다.
torch.utils.data.DataLoader()를 사용해 불러온 데이터 결과값은Generatior형식..!- 따라서, iter()로 불러와서 next()로 감싸면 전체 데이터를 사용할 수 있다.
x, y = next(iter(불러온 데이터셋))shuffle인자 외에도 알고 있으면 좋을 인자들- ❗
sampler인자와batch_sampler인자 - ❗
collate_fn인자
# 3. 모델 불러오기
- model.save() 함수
- 학습 결과를 저장하기 위한 함수로, 모델 architecture와 parameter를 저장 (
early stopping옵션도 함께 사용 가능)
- 모델의
parameters는 state_dict로 저장,model은 ordered_dict로 저장

💡 모델 정보 확인할 때 (방법 3가지)
- ❗
model.state_dict()로 찍어보기 (➕ type: collections.OrderedDict)# Print model's state_dict print("Model's state_dict:") for param_tensor in model.state_dict(): print(param_tensor, "\t", model.state_dict()[param_tensor].size())
- ❗ `torchsummary`로 모델 정보 찍어보기from torchsummary import summary summary(model, (인풋 사이즈))
- ❗ `named_modules()`로 모델 정보 찍어보기 (➕ 접근도 가능)for name, layer in 모델명.named_modules(): print(name, layer) ## 모델의 특정 layer의 feauture 값 수정 예시 #vgg.classifier._modules['6'] = torch.nn.Linear(4096, 1) #vgg.cuda()
- checkpoints
- early stopping 기법 사용 시 이전 학습의 중간 결과물을 저장할 때 사용 (
epoch,loss,metric함께 저장하여 확인)

- pretrained model을 Transfer learning하기
- 다른 데이터셋(General한 대용량 데이터셋)으로 만든 모델을 현재 데이터에 적용
- backbone architecture가 잘 학습된 모델에서 일부분만 변경하여 학습을 수행하는 방식
(ex. 만들어진 Source Task 모델을 Target Task에 전이 학습 Fine-Tuning)- NLP에서는 Huggingface가 표준
💡
frozen기법...! ✨ (거의 Must)
- ❗ 모델에서 각 layer를 번갈아 가며 frozen시키고, 나머지 layer들로부터 학습을 backpropagation하는 방법론도 있다...!
- 보통은 마지막
linear layer를 제외하고는 모두(=pretrained model의 모든 layer) frozen시키고, 내가 마지막으로 커스텀해서 붙인 `linear layer'의 파라미터들만 학습을 시킨다..!
from torch import nn
from torchvision import models
## [1] Custom Model 정의 ✨
class 커스텀모델_클래스명(nn.Module):
def __init__(self):
super(커스텀모델_클래스명, self).__init__()
self.기존모델 = models.사전학습모델(pretrained=True) ## 사전학습모델의 모든 layer 받아오기 (✨pretrained=True 설정 필수!)
self.linear_layers = nn.Linear(사전학습모델's Output 크기, 내가 사용할 클래스 개수 크기) ## 기존 사전모델에 커스텀한 Linear layer 추가
# Defining the forward pass
def forward(self, x):
x = self.기존모델(x)
return self.linear_layers(x)
## cuda 설정
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
## 사용할 accuracy 지표 필요에 따라 함수 정의
def binary_acc(y_pred, y_test):
y_pred_tag = torch.round(torch.sigmoid(y_pred))
correct_results_sum = (y_pred_tag == y_test).sum().float()
acc = correct_results_sum/y_test.shape[0]
acc = torch.round(acc * 100)
return acc
## [2] Model Training (Transfer Learning) ✨
my_model = 커스텀모델_클래스명()
my_model = my_model.to(device)
#print(my_model)
for param in my_model.parameters():
param.requires_grad = False ## 사전모델학습로부터 활용하는 파라미터 값은 학습을 시키지 않음 (✨Frozen!!)
for param in my_model.linear_layers.parameters():
param.requires_grad = True ## ## 내가 추가로 붙인 마지막 Linear Layer 층의 파라미터 값은 학습을 시킴
## 사용할 Loss 및 Optimizer 함수 정의
criterion = nn.BCEWithLogitsLoss()
optimizer = optim.Adam(my_model.parameters(), lr=LEARNING_RATE)
## Training !!
for e in range(1, EPOCHS+1):
epoch_loss = 0
epoch_acc = 0
for X_batch, y_batch in 나의데이터셋: ## ✨ 위에서 내가 PyTorch의 DataLoader API 활용해 로드해온 batch 단위의 데이터셋
X_batch, y_batch = X_batch.to(device), y_batch.to(device).type(torch.cuda.FloatTensor)
optimizer.zero_grad()
y_pred = my_model(X_batch)
loss = criterion(y_pred, y_batch.unsqueeze(1))
acc = binary_acc(y_pred, y_batch.unsqueeze(1))
loss.backward()
optimizer.step()
epoch_loss += loss.item()
epoch_acc += acc.item()
## Checkpoints 및 Early Stopping 설정 추가 가능
print(f'Epoch {e+0:03}: | Loss: {epoch_loss/len(dataloader):.5f} | Acc: {epoch_acc/len(dataloader):.3f}')
# 4. Monitoring tools for PyTorch
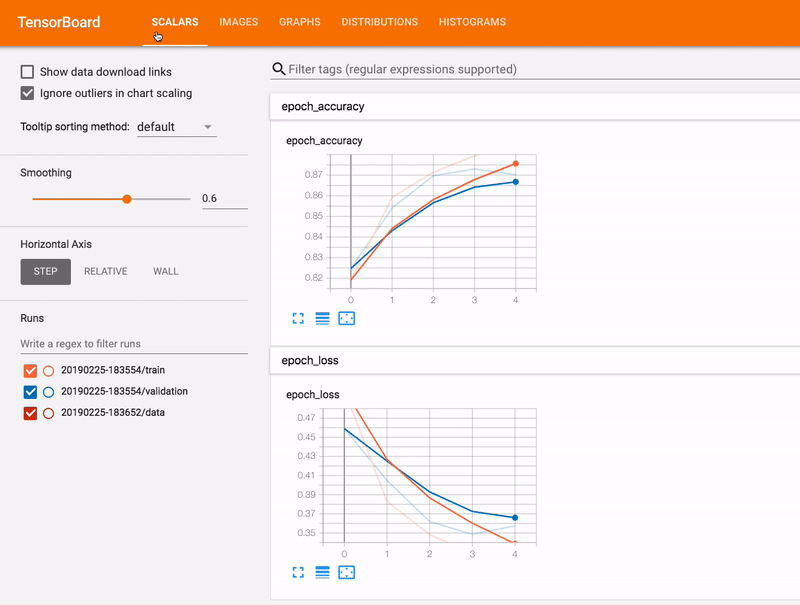
- ❗ [1] Tensorboard
- NLP에서도 Text의 예측 값과 실제 값을 비교할 때 사용 가능
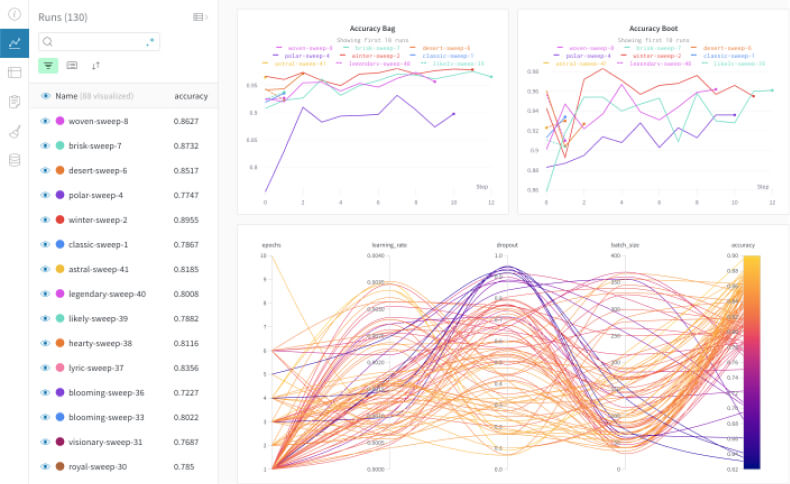
- ❗ [2] weight & biases
- 협업이 가능..!, 코드 versioning, 프로젝트 단위, 최근 MLOps의 대표 Tool로써 사용됨

AI, Big Data, Industrial Engineering