
목차
1. 궁극적인 목표
2. 내가 겪은 문제점
3. 솔루션 (데이터 파이프라인을 만들자!)
4. 의문점
5. 후기
피드백은 언제나 환영합니다.
언제든 훈수해 주셔도 괜찮습니다.
지난 글에 이어서 작성합니다.
겜린더 스크래핑 봇 제작기 Steam편
Github
Gamlendar_Selenium
3줄 요약
- 게임 정보를 자동으로 수집하고 저장하는 데이터 파이프라인 구축
- 데이터 전처리(Data Cleansing)을 통해 일관성 있는 데이터 정제 및 RDB에 저장
- Steam, Xbox, Playstation, Nintendo Switch 합쳐 약 2300개의 데이터를 수집할 수 있었음
궁극적인 목표
리마인드 하기 위해 다시 목표부터 작성해 보자면..
-
게임 정보를 하나하나 손으로 수집하기 힘들기 때문에 자동화하기
-
중복 게임은 하나로 합쳐주기
게임 출시하는 플랫폼은 여러 곳이 존재하는데
만약 A라는 게임이 Playstation, Xbox에 출시한다면
각 플랫폼 페이지에 있는 A 게임의 정보를 하나로 합쳐 정리해 주는 것이 목표였습니다.
예시를 들어보자
| 게임이름 | 게임설명 | 제작사 | 플랫폼 |
|---|---|---|---|
| 엘든링 | 그냥 겁나어려운 게임 | FromSoftware | Playstation |
| 엘든링 | 그냥 겁나어려운 게임 | FromSoftware | Xbox |
| 엘든링 | 그냥 겁나어려운 게임 | FromSoftware | Steam |
이런 식으로 정리가 되면 중복되는 데이터가 너무 많아지는데..
예제라서 별것 아니네~ 할 수 있겠지만 세상에는 게임이 정말 많았습니다..
이런 게임이 수백 개가 쌓이면 저걸 어떻게 관리할 방법이 있을지...
저는 생각나지 않았습니다.
| 게임이름 | 게임설명 | 제작사 | 플랫폼 |
|---|---|---|---|
| 엘든링 | 그냥 겁나어려운 게임 | FromSoftware | Playstation, Xbox, Steam |
이렇게 합쳐 추후에 JSON 형식으로 정리할 때도
{
"게임이름":"엘든링",
"게임설명":"그냥 겁나어려운 게임",
"제작사":"FromSoftware",
"플랫폼":[Playstation, Xbox, Steam"]
}
이런 식으로 손쉽게 정리했으면 좋을 것 같은데
이렇게 정리하면 결과물은 어떻게 나올까요??
예상 결과물
현재 리뉴얼을 진행 중인 겜린더 상세정보 페이지
이미지 우측 하단에 지원 플랫폼 아이콘을 볼 수 있다.

요런 결과물이 나오게 됩니다
내가 겪은 문제점
1. 데이터 수집 전략
- 각 플랫폼마다 형태가 전부 다른데 일일이 하나하나 웹페이지를 분석하여 페이지에 맞게 수집을 해야 하는 것
(이건 당연한 소리지만... 생각보다 애를 많이 먹었네요...😂)
2. 수집한 데이터의 게임 이름을 일치시키기
같은 게임이더라도 각 플랫폼에 등록되어 있는 게임의 이름이 다른 경우가 있었습니다.
| Xbox | Playstation |
|---|---|
| 유니콘 오버로드 | Unicorn Overlord |
이런 식으로 어떤 곳에선 한국어로 되어있고 어떤 곳은 영어로 되어있었던 건 기본이고...
| Xbox | Playstation |
|---|---|
| Taxi Life: A City Driving Simulator | Taxi Life: Supporter Edition |
이런 식으로 DLC 번들팩을 같이 포함해서 노출시키는 경우도 많았습니다.
(사실 이 부분은 완벽하게 해결하진 못했습니다.)
3. 게임 이외의 DLC도 함께 노출
위 사진은 Xbox의 출시 예정 리스트 중 일부
MLB The Show 24만 현재 5개나 겹쳐있는 이런 경우도 많았습니다.
저런 데이터까지 전부 수집하면 중복되는 데이터가 많아져
겜린더를 이용하는 유저 입장에선 필요 없는 데이터까지 노출되어 정작 해당 게임에 대한 핵심 정보는 보지 못할 수 있겠다 생각하였습니다.
4. 닌텐도는 왜... 한국 페이지랑 북미 페이지랑 완전히 다를까요...?
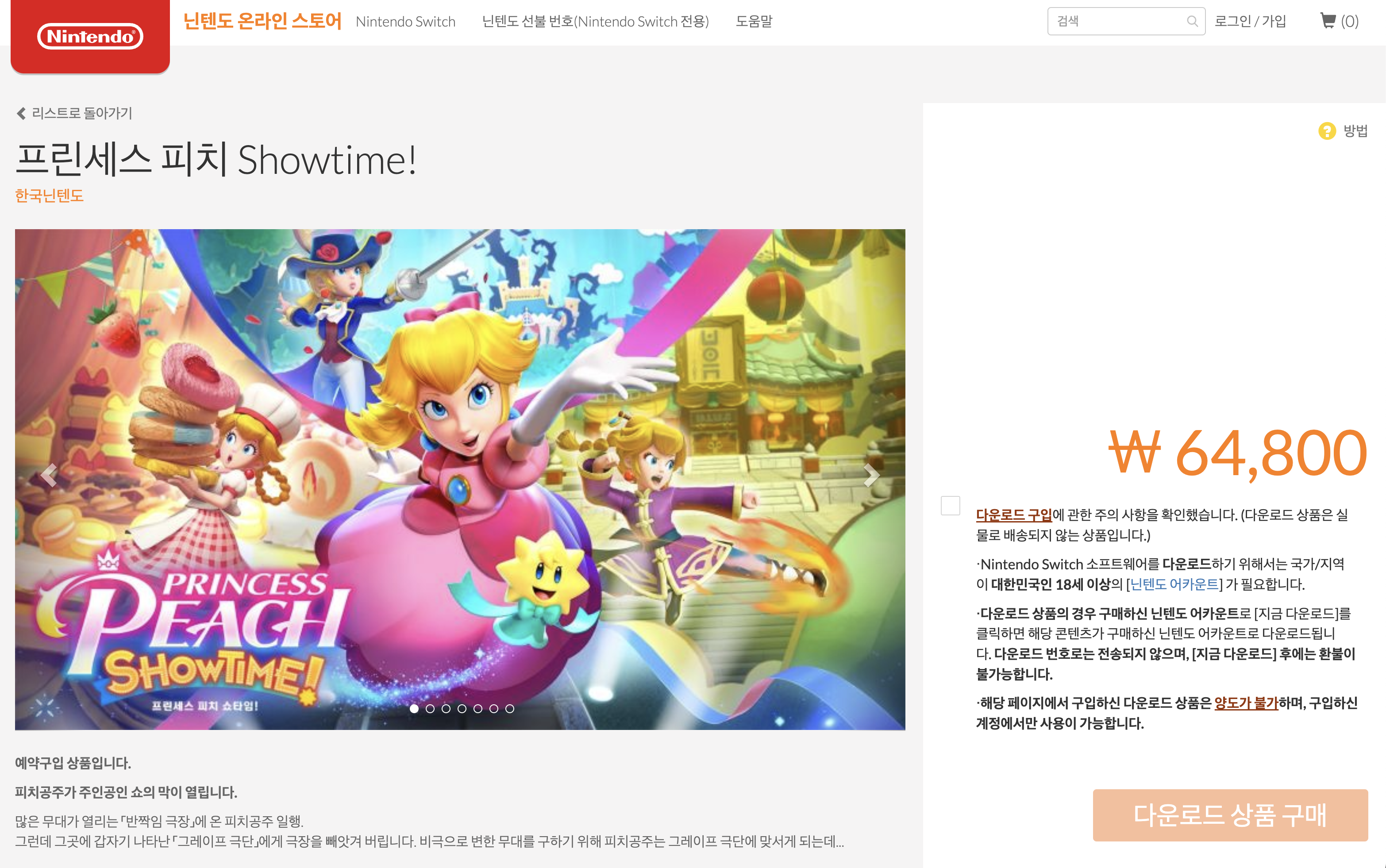
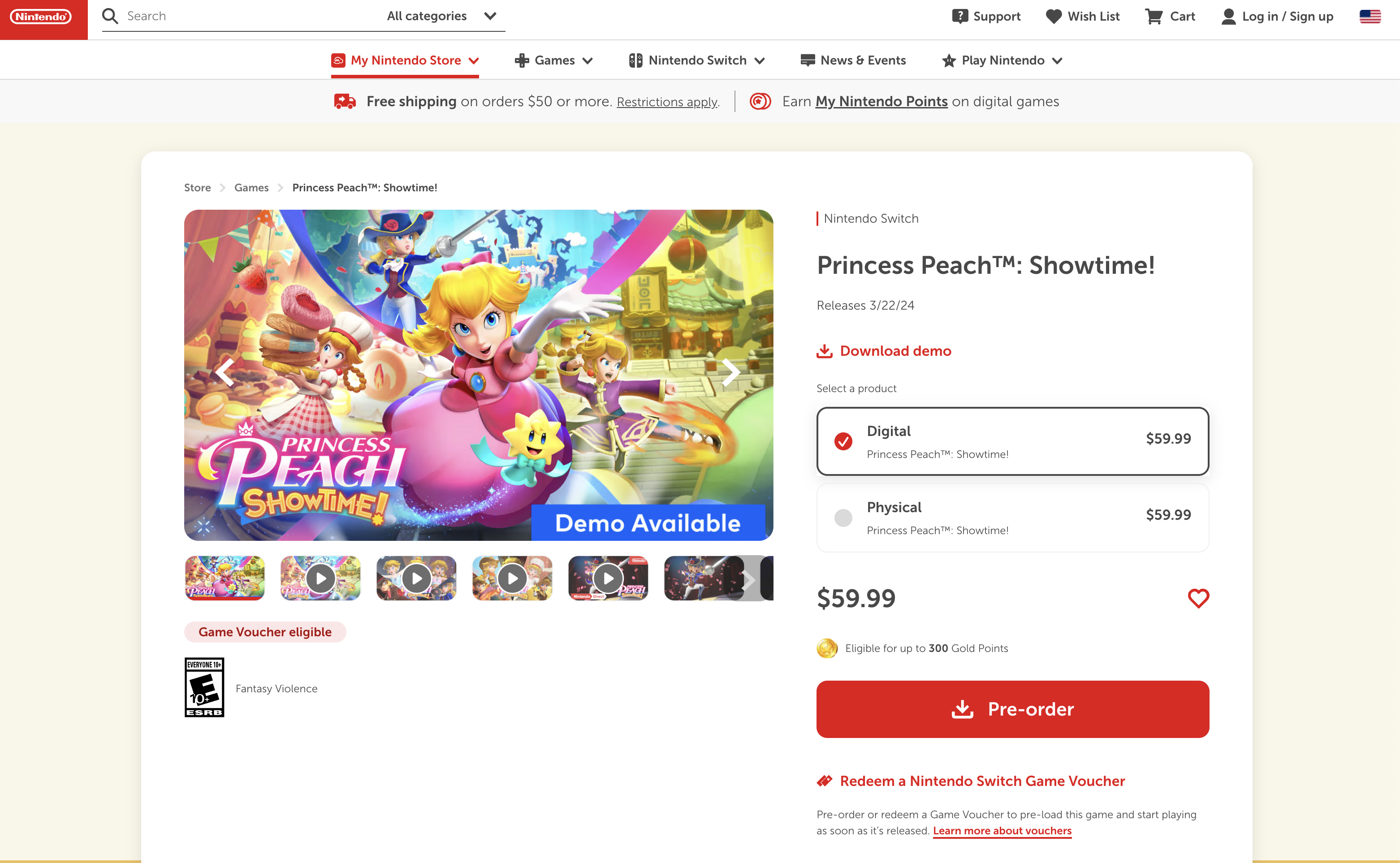
북미 페이지와 한국 페이지의 레이아웃 디자인은 완전히 달랐습니다.
심지어 SKU(Stock Keeping Unit)도 형태 자체가 달라 이건 뭐.. 어떻게 수집해야 할지 고민을 많이 했습니다.
5. 성인 게임 필터링
겜린더 스크래핑 봇 제작기 Steam편
여기서 보면 Steam에 있는 성인 게임을 어떻게 필터링했는지 나와있기 때문에 솔루션 부분에서 간단하게 언급만 하겠습니다.
이렇게 5가지를 어떻게 해결했고
어떤 구조로 만들었는지 구체적으로 적어보겠습니다.
솔루션 (데이터 파이프라인을 만들자!)
겜린더 백엔드 구조도
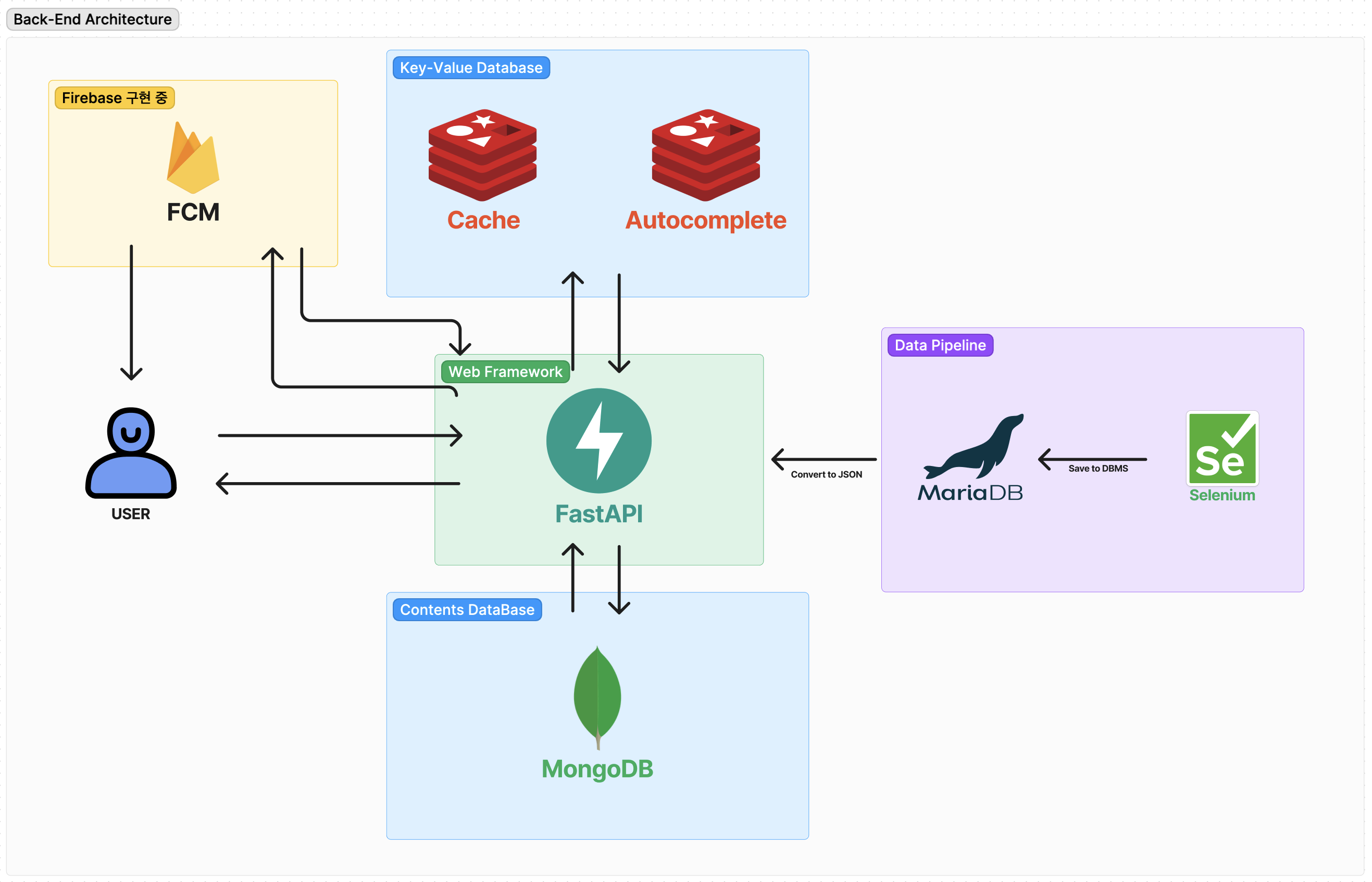
 흐름도..
흐름도..
유저에게 최종적으로 어떻게 전달되는지 보여주는 간략한 구조도입니다.
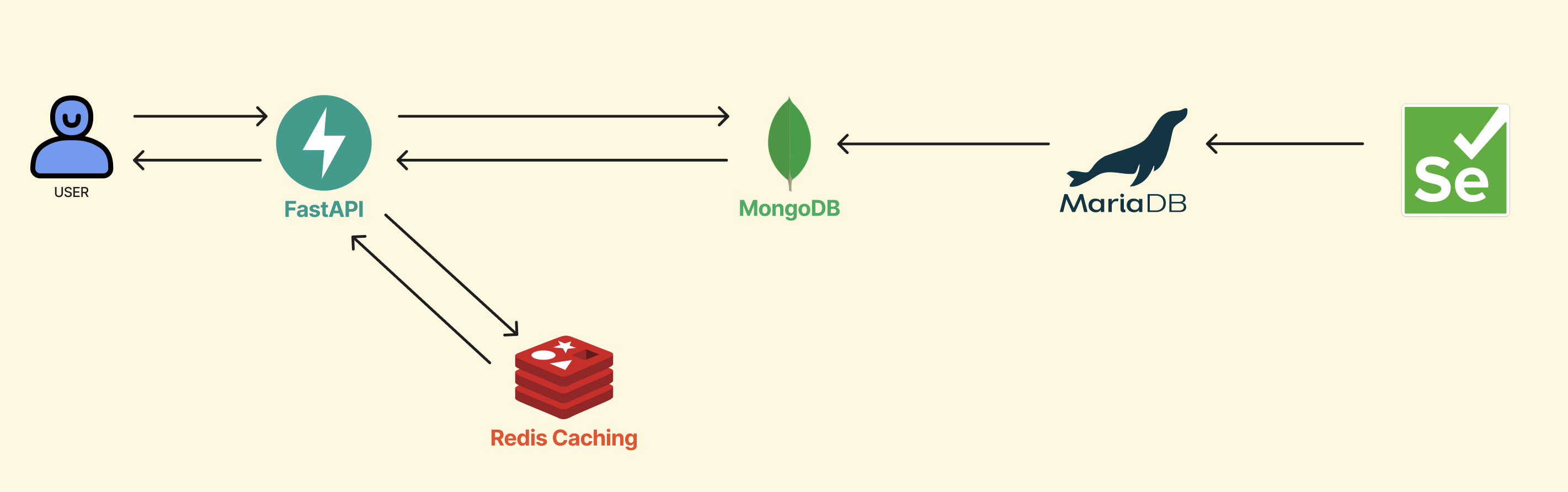
오늘은 MongoDB - MariaDB - Selenium 이렇게 3가지 영역을 좀 더 설명해 볼까 합니다.
데이터 파이프라인 구조
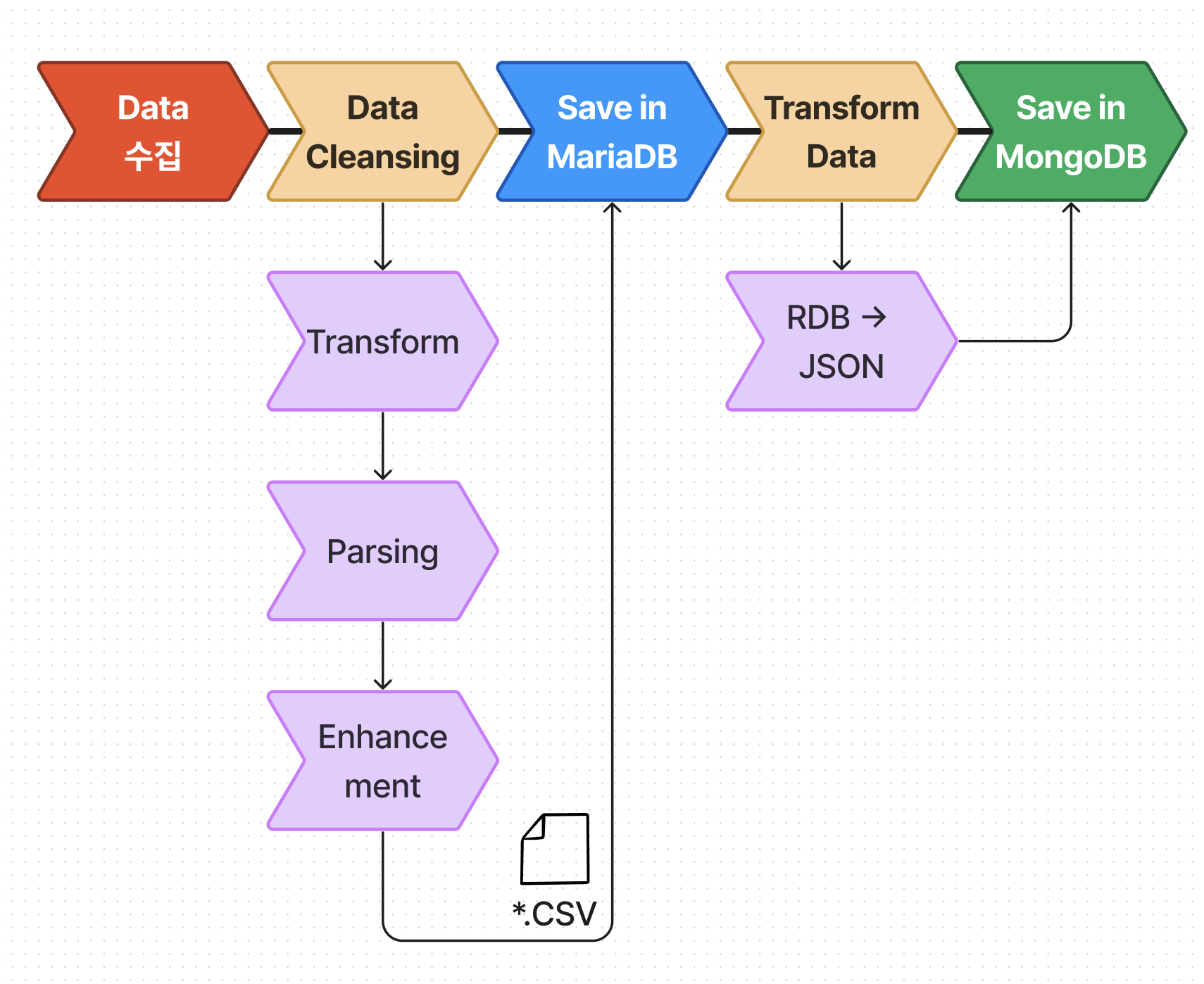
게임 수집과 DB에 저장하기 위한 데이터 파이프라인을 구축해 보았는데요
여기서 영역 별로 쭉 훑어보도록 하겠습니다.
Data 수집
데이터 수집을 시작할 때 처음부터 Selenium 브라우저를 2개를 실행하기로 했습니다.
겜린더 스크래핑 봇 제작기 Steam편 이유는 여기에 나오지만 간략한 설명을 하자면
게임 검색에 필요한 게임 이름이 한국어뿐만 아니라 영어도 필요했기에
2개를 실행해 각각 수집하기 위해서였죠
여기선 겪은 문제점 중 3번(게임 이외의 DLC 노출) 을 어떻게 해결했는지 적어보려고 합니다.
번들 탐지 기능

여기 중 가장 좌측 상단의 첫 번째 MVP 에디션을 눌러보면
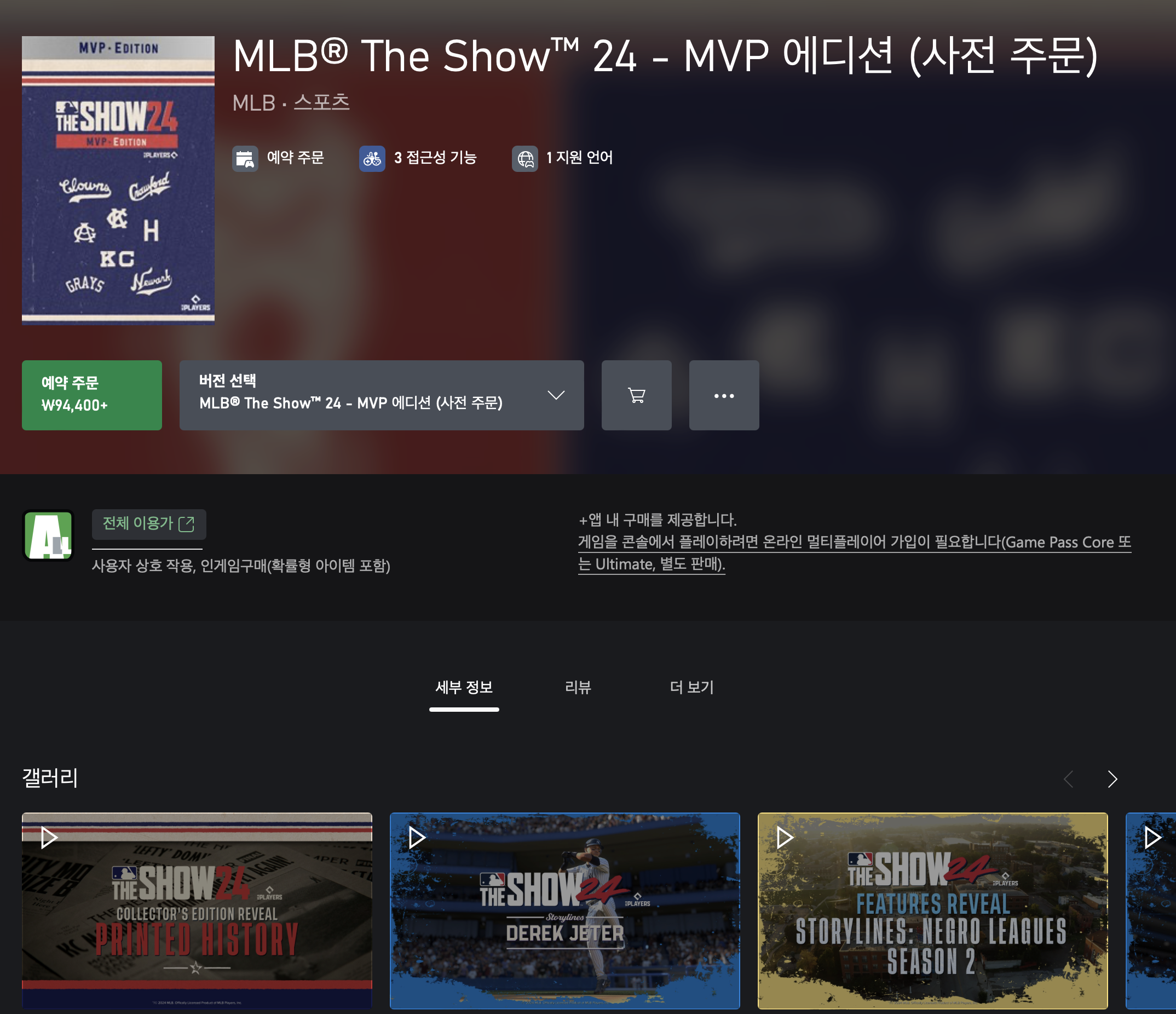
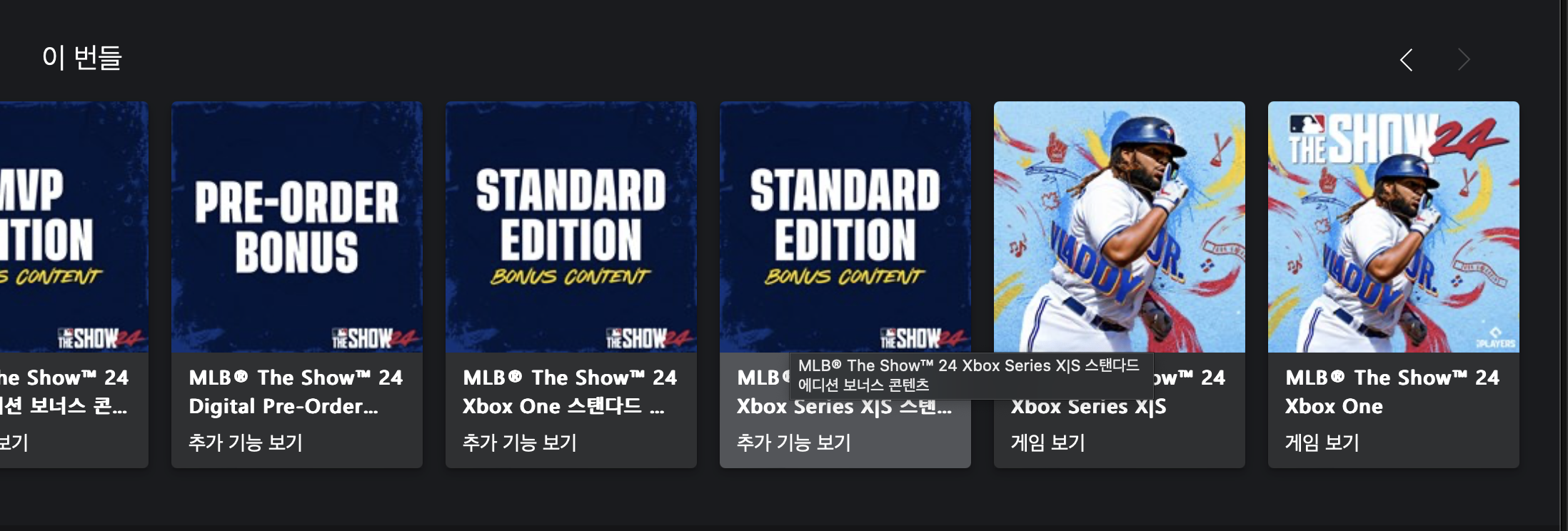
게임의 정보와 함께 하단을 내렸을 때 "이 번들"이라는 정보가 나오게 됩니다.
제가 원하는 정보는 DLC가 아닌 순수한 게임의 정보였기 때문에
"이 번들" 정보를 수집해
"MLB The Show 24 Xbox One" 혹은 "MLB The Show 24 Xbox X|S" 둘 중 하나의 페이지로 다시 리다이렉트 시키는 것이 목표였습니다.
반대로 저런 번들이 없다는 건 순수한 게임 페이지로 판단할 수 있어 바로 게임 정보를 수집할 수 있게 만들었습니다.
코드
주의⚠️ 스파게티 코드라 눈뽕이 있을 수 있으니 참고 바랍니다. 죄송합니다...🙇
(물론 Refactoring 할 예정입니다...)
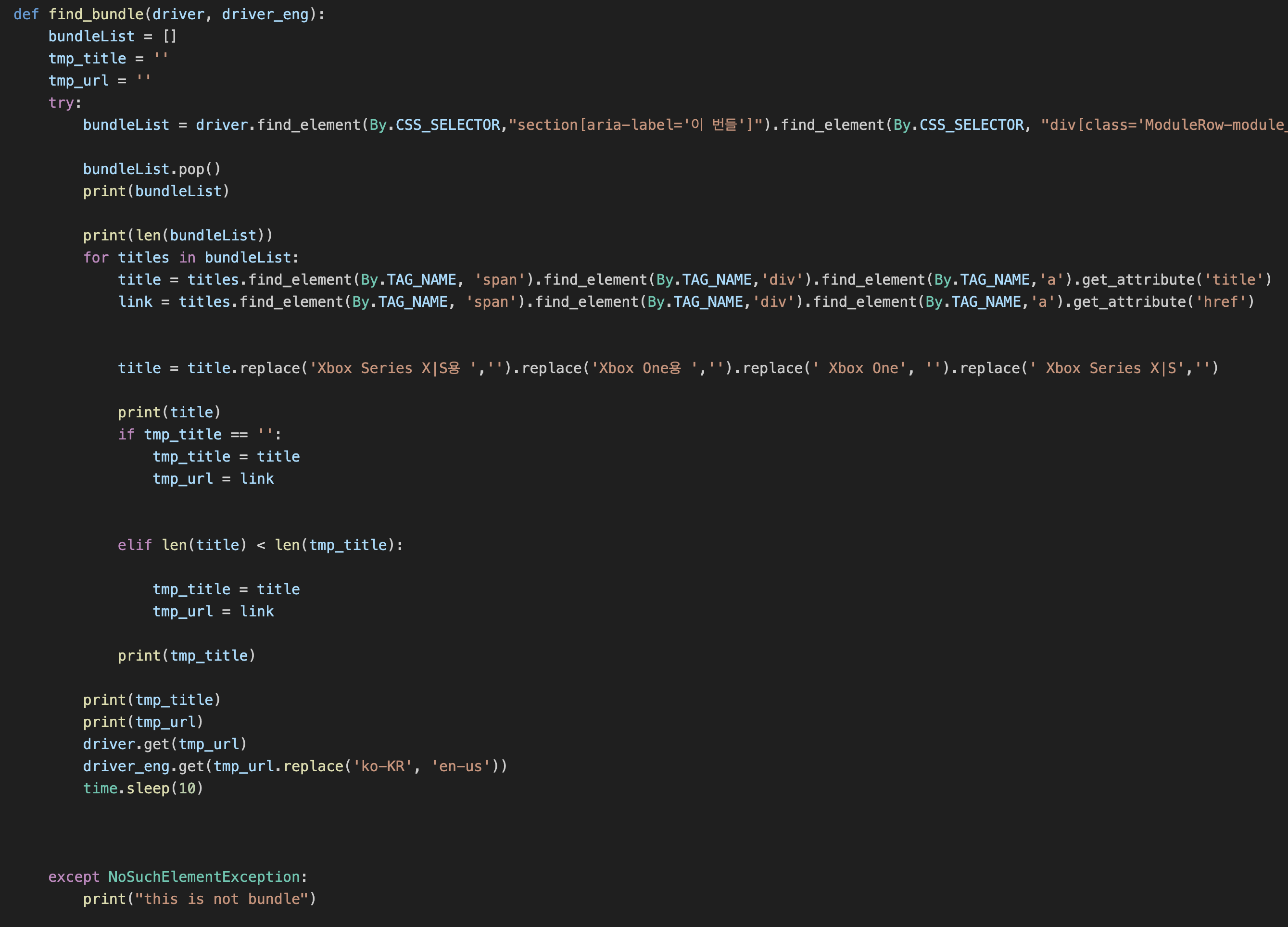
물론 다른 것들도 여러 가지 번들이 많기 때문에
처음 게임 리스트에서부터 사전에 정해둔 단어가 포함되어 있으면 수집 대상에서 제외하는 1차 필터링 기능을 넣었습니다.
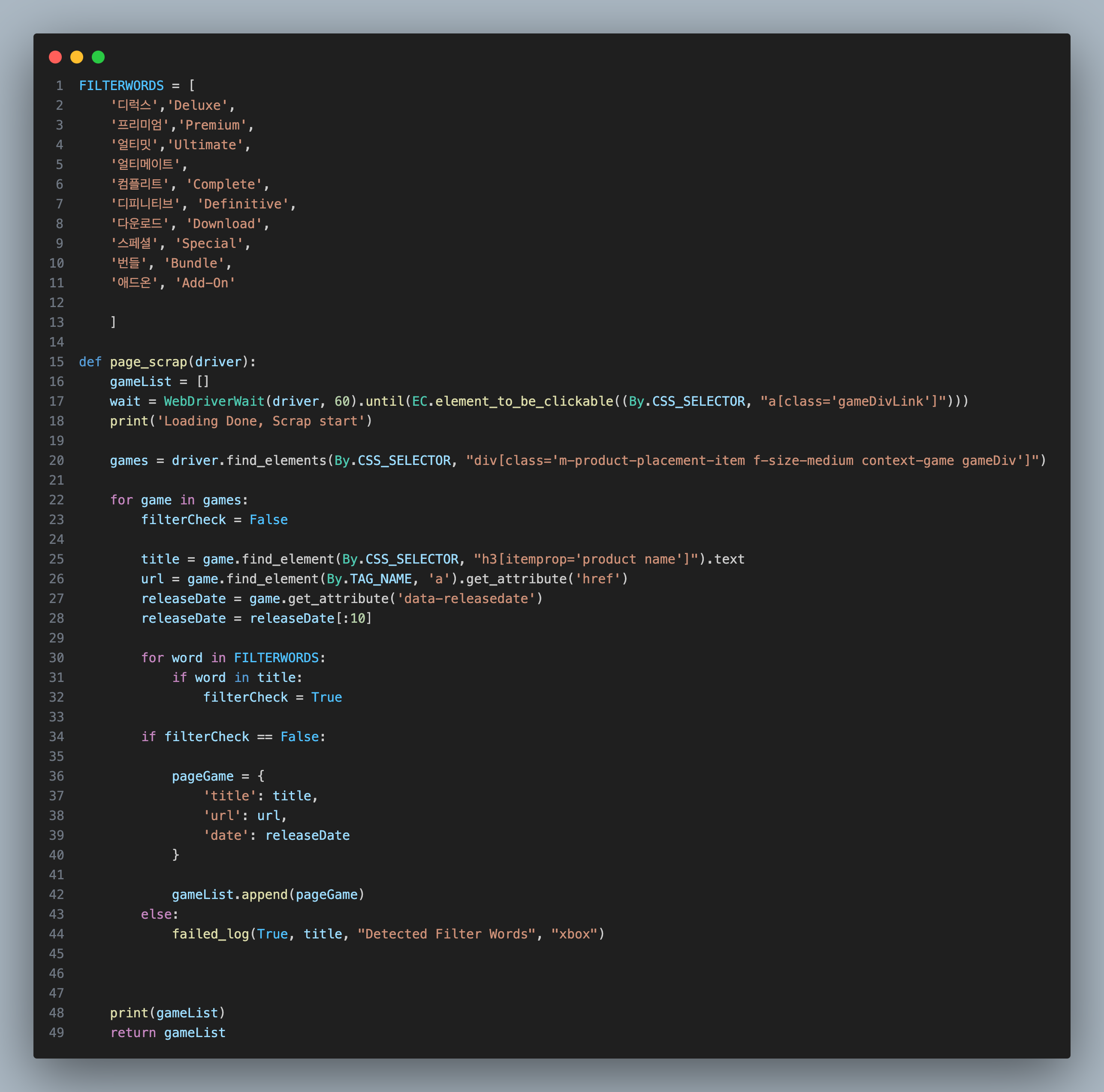
하지만 1차 필터링으론 한계가 꽤 많았습니다.
필터링 단어에 "Edition"이란 단어를 넣으면
게임 이름에 Edition이 들어간 게임이 의도치 않게 제외될 수도 있어 번들 탐지 기능을 추가하였습니다.
Xbox 페이지를 수집하면서 꽤나 중복된 게임 정보가 많았기 때문에 여러 수집 전략을 생각해 볼 수 있었습니다.
성인 게임 필터링
겪었던 문제점 중 5번 성인 게임 필터링이 있었죠?
이 부분은

그냥 필터링 걸어서 해결했습니다.
저 태그가 들어간 친구들은 도저히 겜린더에 들어가기 힘들겠단... 게임들도 많았습니다.
그래서 그냥 자체적으로 걸러냈습니다.
아직 성인 인증 기능이 겜린더에는 안 들어갔거든요...🥲
Data Cleansing
사실상 여기가 제일 중요한 지점인데요 이 부분을 잘해야
나중에 DB에 저장할 때 데이터 무결성과 중복 데이터를 잘 처리할 수 있었기 때문이었습니다.
그래서 수집한 사이트마다 미묘하게 다른 게임 데이터들을 일관성 있게 정제해야 했습니다.
정제 기법은 3가지가 존재하는데요 3가지의 소개와 겜린더에는 어떻게 적용했는지 같이 설명하겠습니다.
1. 변환
다양한 형태로 표현된 값을 일관된 형태로 변환하는 작업
- 수집된 게임 이름 중 불필요한 데이터를 없앴습니다.
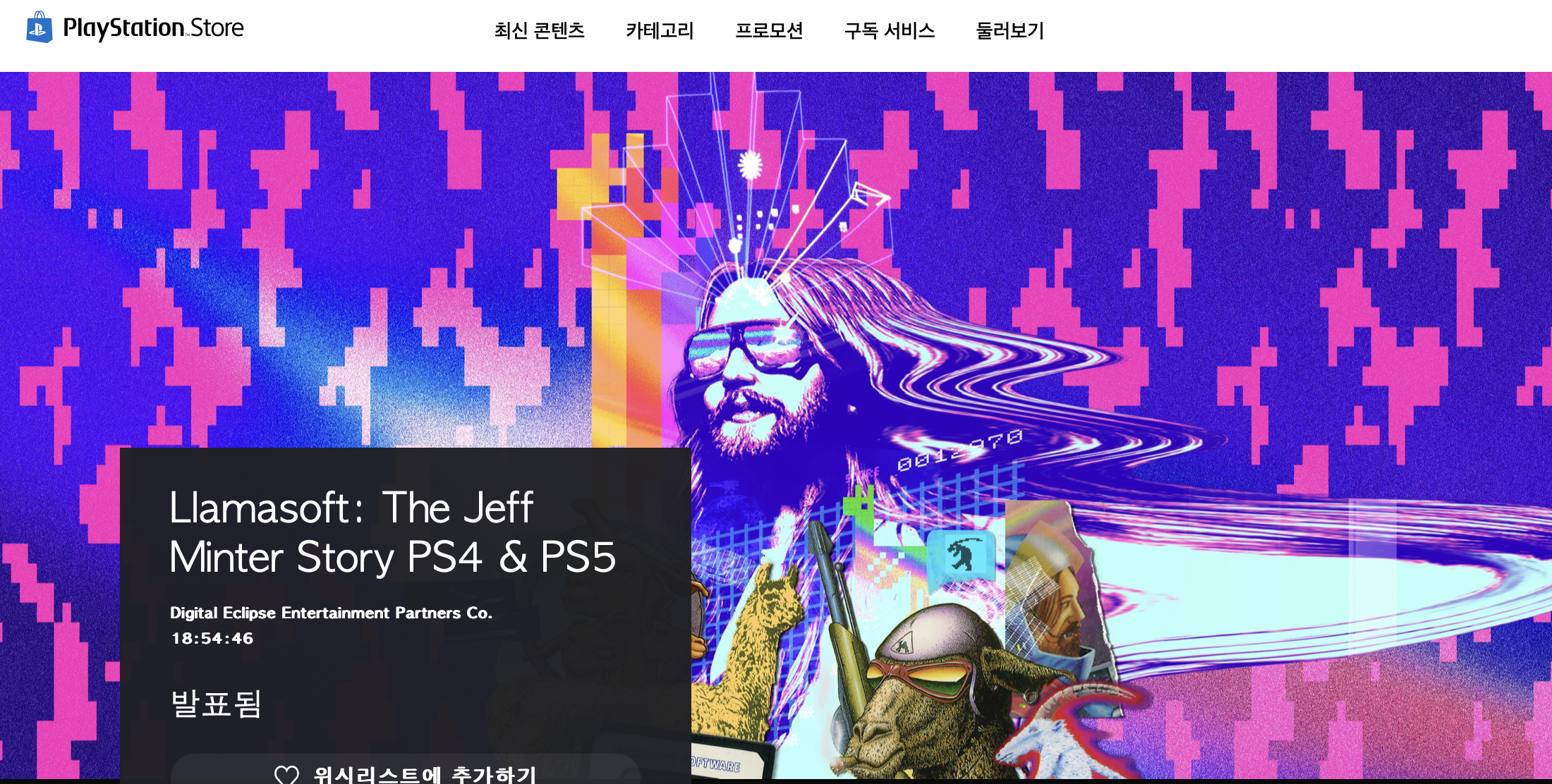
게임 이름 뒤에 있는 PS4 & PS5는 필요 없기 때문에 replace로 간단하게 지워주었습니다.
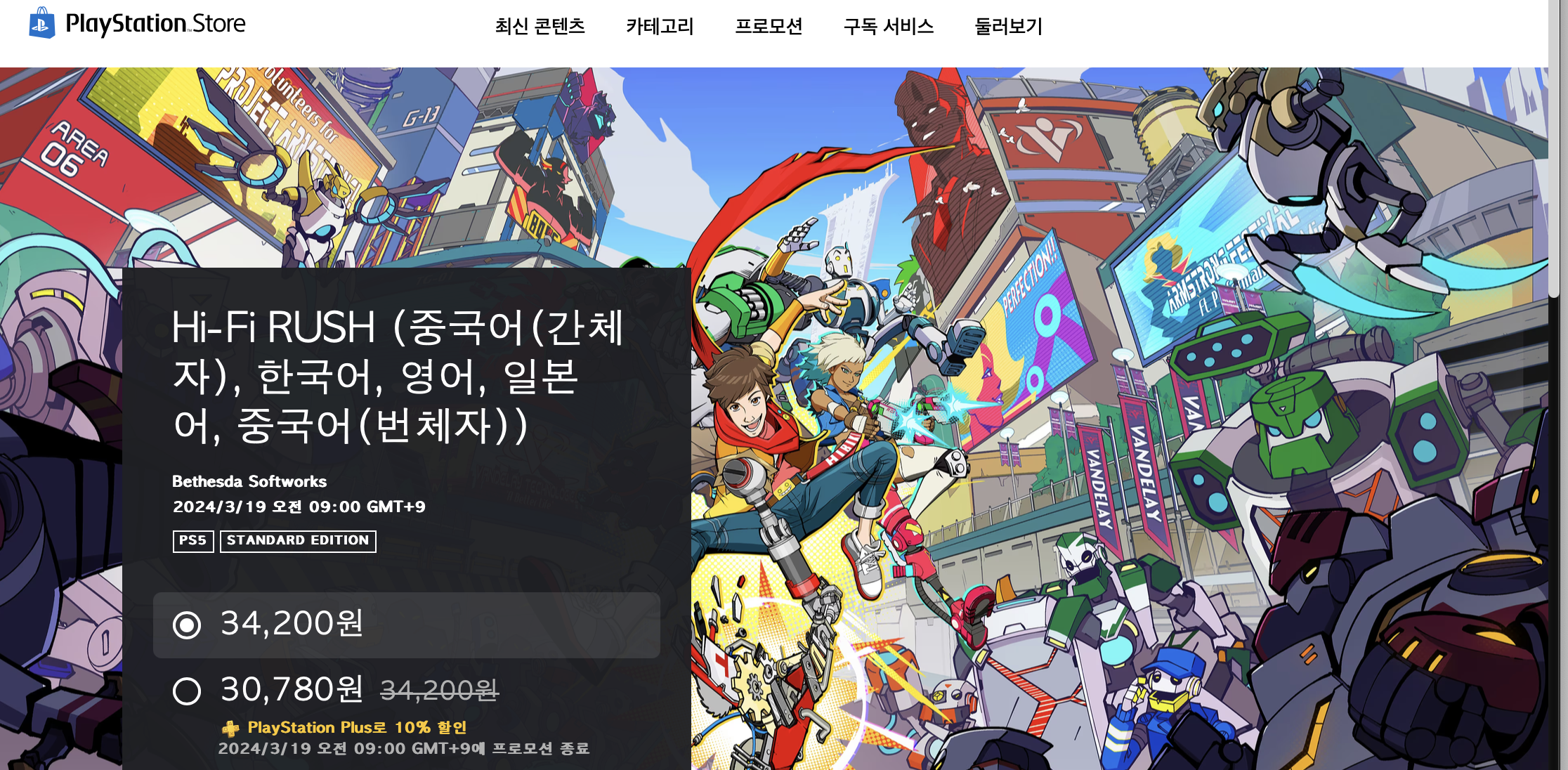
이렇게 괄호가 정말 많이 들어간 게임도 존재했는데요

코드로 보여드리는 게 빠를 것 같네요
정규식을 이용했습니다.
굳이 두 번 넣은 이유는 괄호 안에 괄호가 있는 경우가 많아 2번 넣어 해결했습니다.
2. 파싱
데이터를 정제 규칙을 적용하기 위한 유의미한 최소 단위로 분할하는 과정
- 수집한 데이터 중에서 날짜를 예시로 들면 좋겠네요
Steam은 연, 월, 일로 날짜를 표시하고 (2024년 3월 12일)
Xbox는 '-'로 표시 (2024-03-12)
Playstation은 '/' (2024/3/12)
Nintendo Switch는 '.' (2024.03.12)
각각 달랐기 때문에 연, 월, 일의 최소 단위로 분할부터 하였습니다.
2024, 3, 12 이런 식으로 추출하였습니다.
3. 보강
변환, 파싱, 수정, 표준화 등을 통한 추가 정보 반영
- 겜린더에 적용하기 위해선 YYYY-DD-MM 형식으로 만들어야 했습니다.
그래서 보강이 좀 필요했는데요

Playstation을 예시로 들면 '/'을 기준으로 split 후
월, 일에 zfill(2)를 통해 3을 03으로 변환하는 작업을 거쳐
겜린더 형식에 맞게 '-'.join을 넣어 2024-03-12 가 최종적으로 출력되도록 하였습니다.
닌텐도 페이지 수집
사실 이게 제일 난제였습니다.
다른 페이지들은 페이지 주소만 바꿔서 영문 페이지나 한국 페이지로 변경할 수 있었는데
얘네는 각각 독립적으로 사이트를 운영하고 있었습니다...
어.. 그러면 영문 게임 이름 수집을 어떻게 해야하지...?라고 고민을 많이 했습니다.
고민한 흔적들..
하지만 고민하면서 사이트를 둘러보고 있을 때
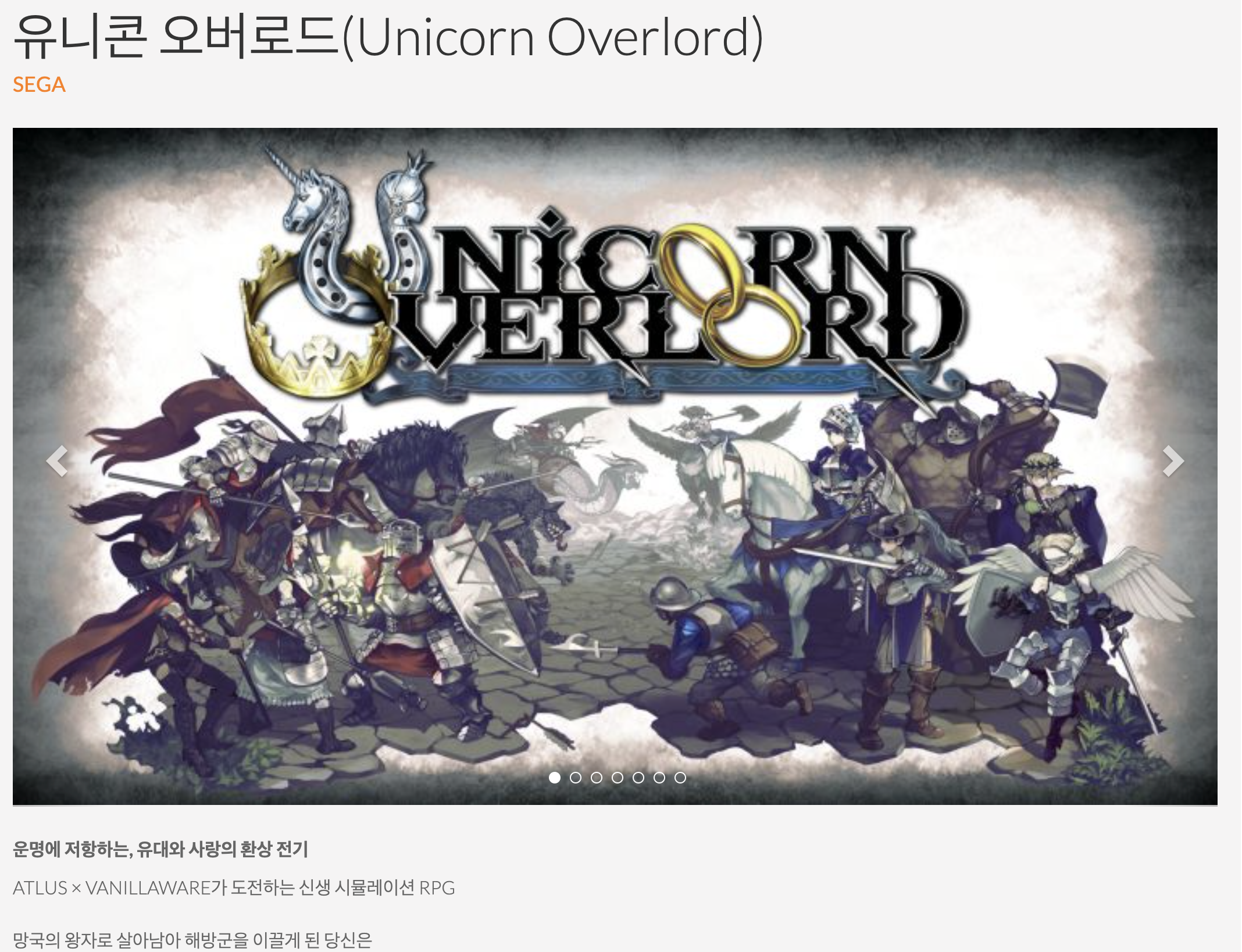 게임 이름 중에 이렇게 괄호로 영문 이름을 사용한 게임이 있더군요!
게임 이름 중에 이렇게 괄호로 영문 이름을 사용한 게임이 있더군요!
그 반대의 경우도 있었습니다. 영어(한국어) 형태로
이거라도 추출해야겠다 싶었습니다. 이게 제 최선이 아닐까 싶었습니다.
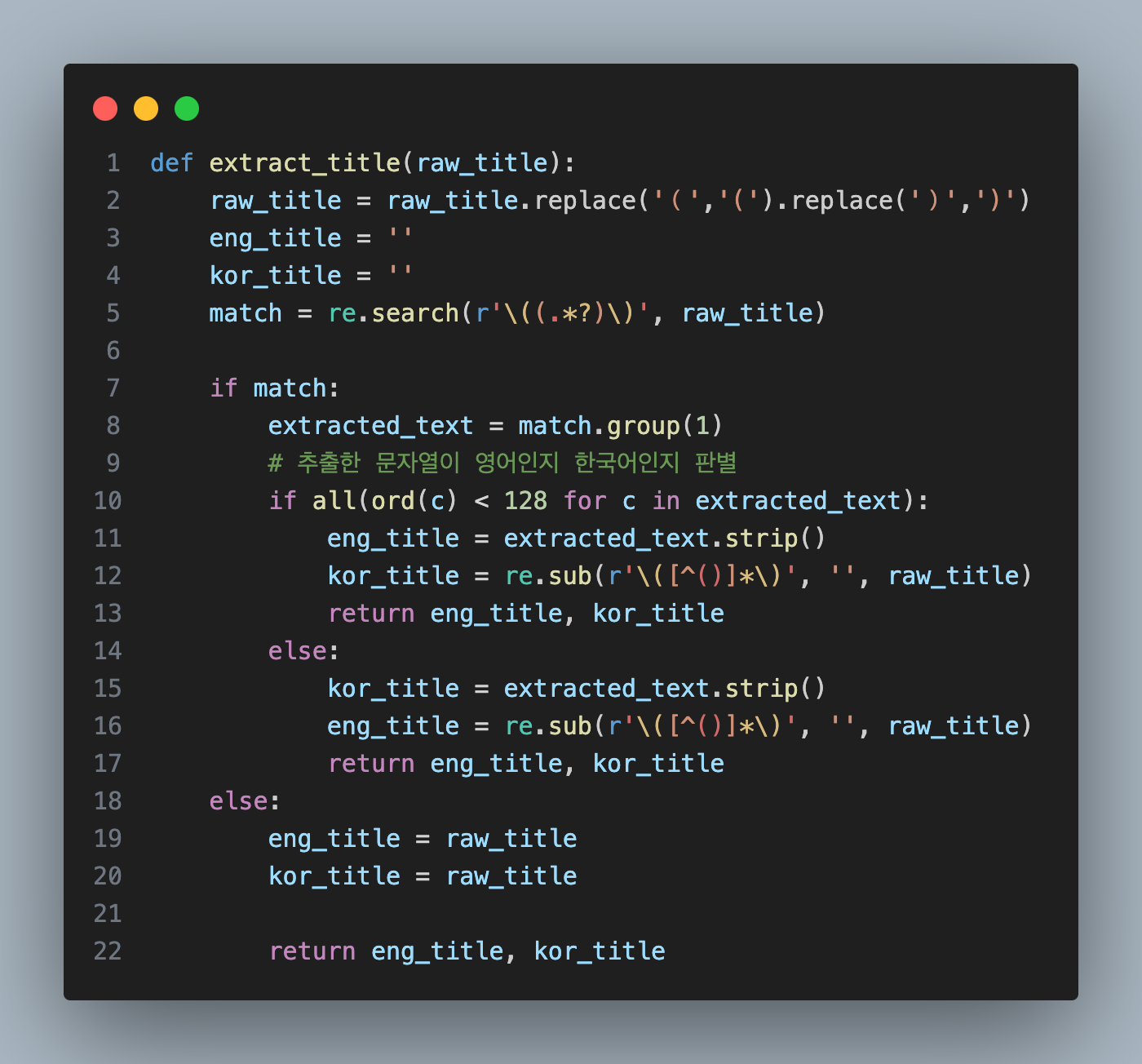
이런식으로 추출하는 코드를 만들었는데
- raw_title에 괄호가 존재하는지 re.search로 확인
- match가 True인 경우 추출한 문자열이 영어인지 ASCII 코드로 확인
- True면 괄호 안의 문자열은 영어이므로 eng_title에 저장 kor_title은 raw_title에서 괄호를 제거해 저장하였습니다.
- match가 False인 경우는 그 반대로 했습니다.
- 아예 위 조건에 맞지 않는 경우는 그냥 raw_title를 eng, kor 둘 다 저장했습니다.
데이터 무결성
데이터 무결성을 위해 여러 작업도 거쳤는데요
한국어로 된 게임 이름은 추후 DB에 넣을 때 무결성이 좋지 못하다고 판단했고
그래서 영문 이름을 기준으로 넣어야겠다는 생각이 들었습니다.
영문 이름을 수집한 이유도 그중 하나였는데요
데이터를 CSV로 전환하는 작업 중 title column 데이터를 autokwd에 있는 영문 이름으로 덮어씌우는 작업까지 해 데이터 무결성을 지킬 수 있었습니다.
for 문만 보시면 됩니다.
왜 concat을 하는지는 겜린더 스크래핑 봇 제작기 Steam편 참고해주시면 감사하겠습니다... 🙇
최종적으로 CSV 파일로(백업용) 저장되는데 이 파일은 DB로 저장됩니다..
Save to MariaDB
여러 가지 과정을 거쳐 결국 MariaDB에 저장하게 되는데
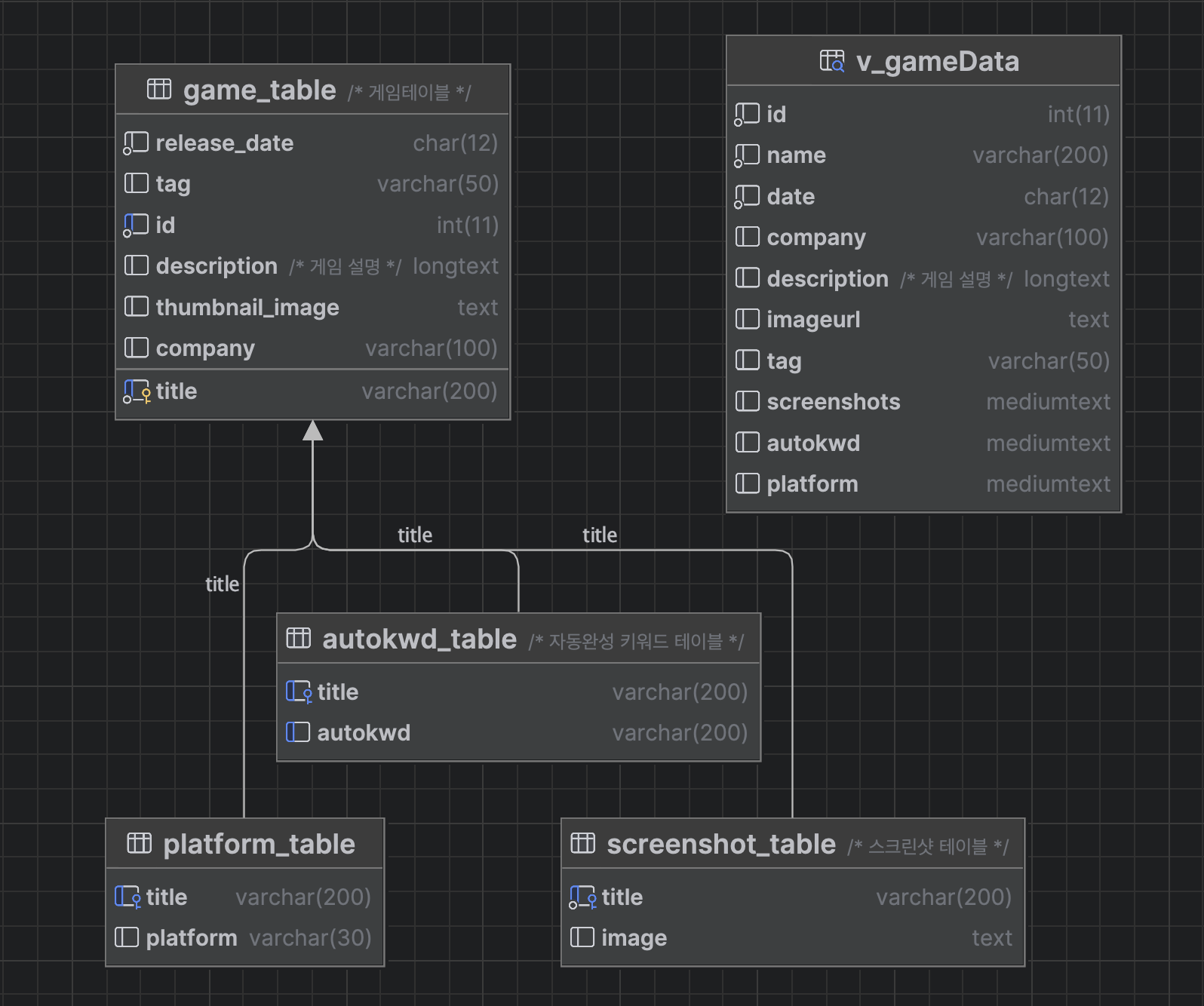
전체적인 ERD입니다. (
Platform, autokwd, screenshot이 중복되는 데이터가 많기 때문에 1정규화를 거쳤습니다.
Dragon's Dogma 2를 기준으로 찾아보면
platform 테이블


screenshot 테이블
autokwd 테이블
Dragon's Dogma 2는 한국어 이름이 없어서 다른 게임으로 대체하였습니다.
Transform Data (RDB -> JSON)
자.. 이제 모은 정보들을 다시 하나로 합쳐 JSON 형태로 변환해 API로 전송해야 합니다.
MongoDB로 보내는 작업을 해야 하는데...
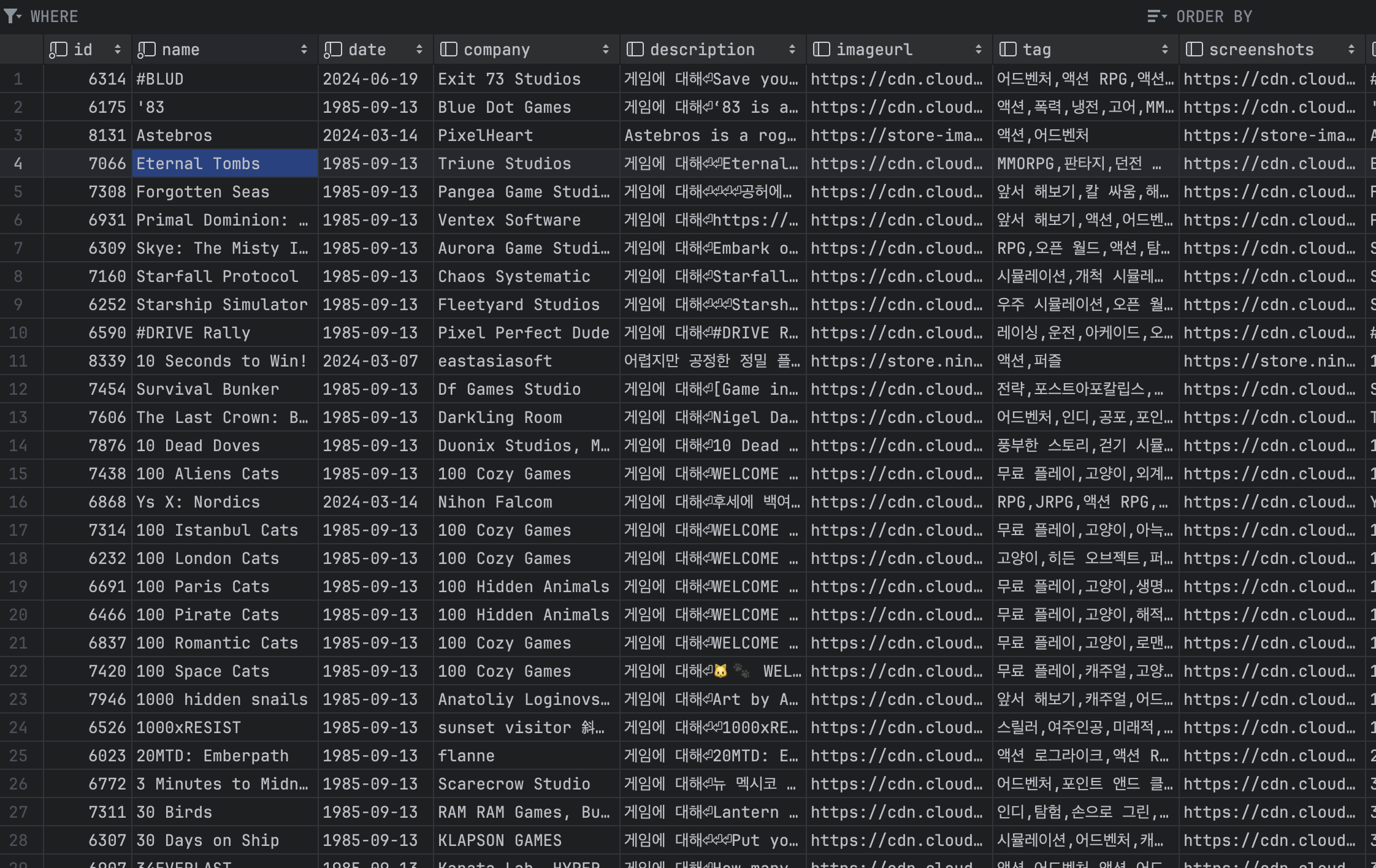
View를 따로 만들어서 조회하고
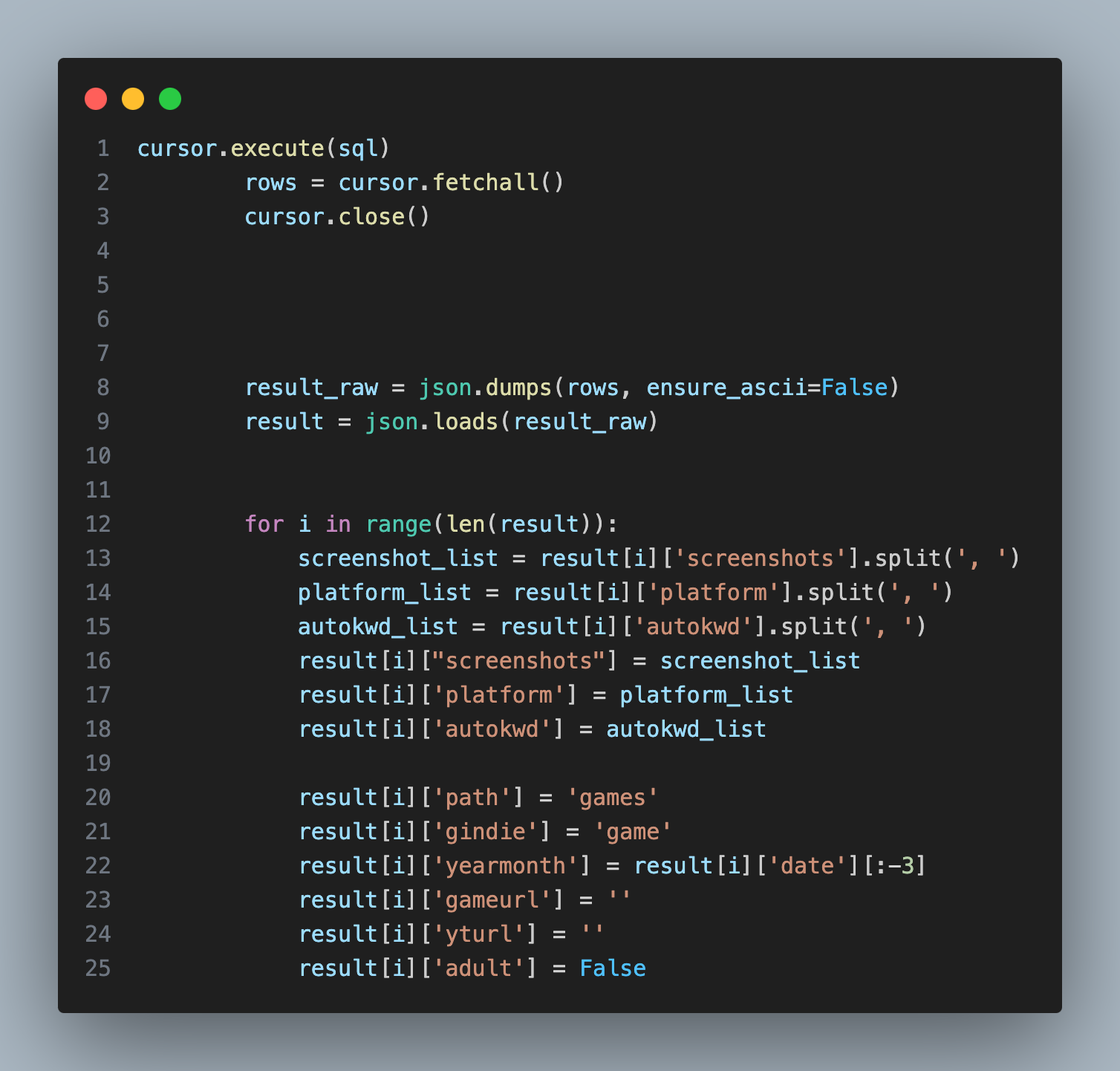
일부 필요한 데이터를 또 추가로 넣어둔 다음...
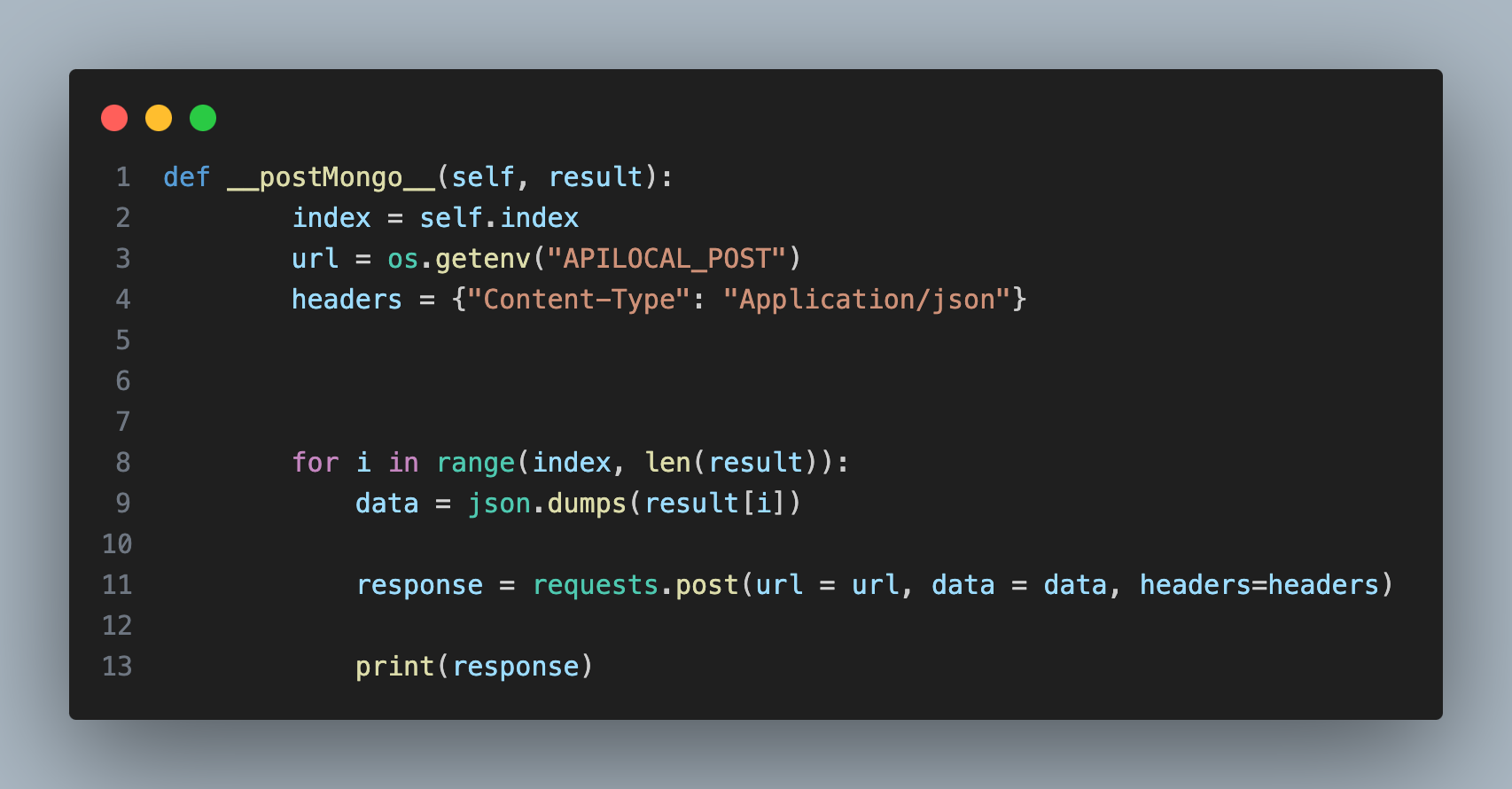
Request로 간단하게 넣어주면 MongoDB로 옮기는 작업이 끝나게 됩니다.
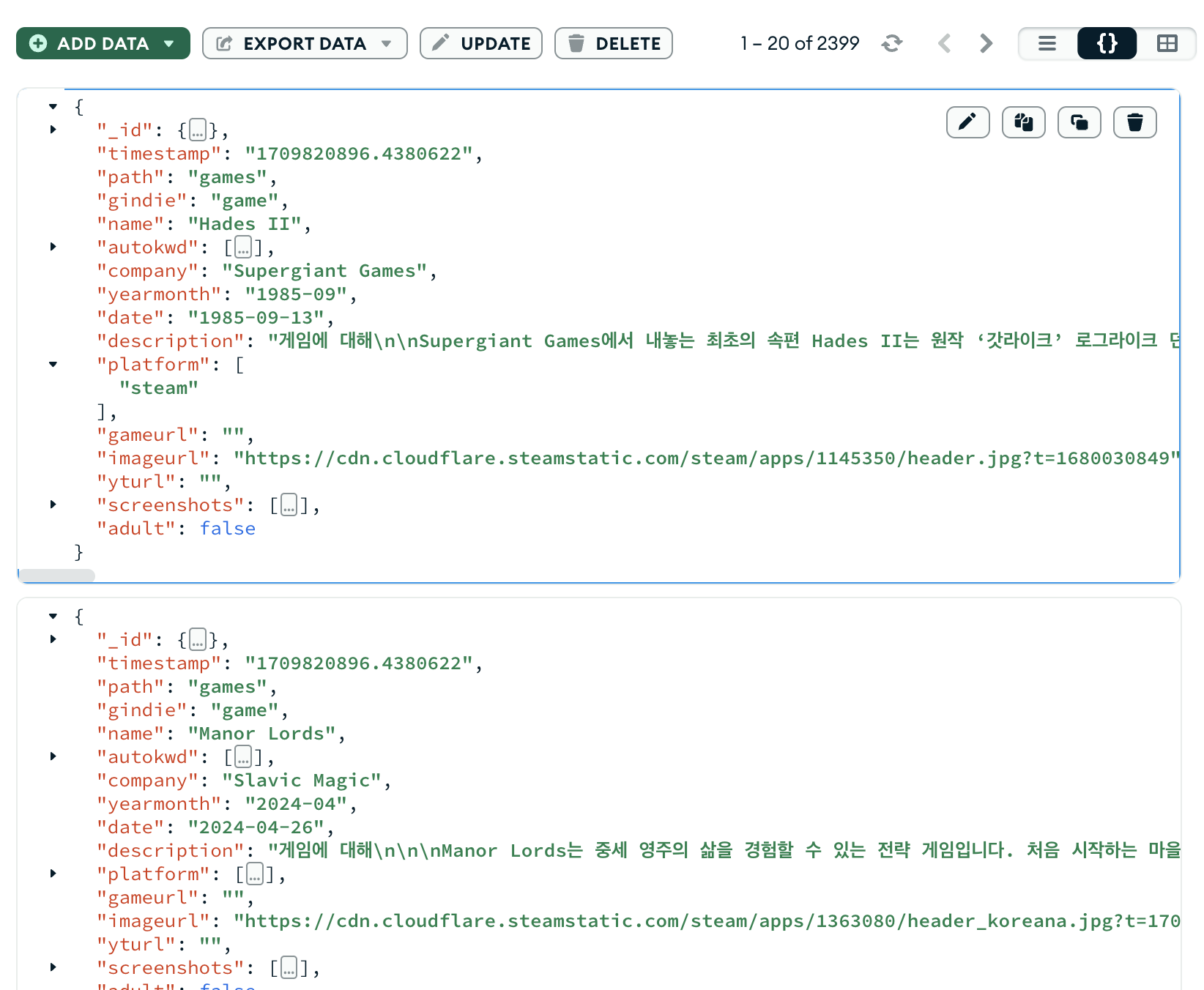
MongoDB에 이쁘게 옮겨진 모습입니다.
위에 보니 2399개가 저장되었네요 😊
의문점
실제로 지인들에게 들었던 말인데
"이럴 거면 그냥 CSV에서 데이터 통합해서 JSON으로 보내는 게 더 낫지 않냐! 굳이 왜 RDB같은 거 왜 씀?"
(Pandas 뒀다 뭐 함?)
어.. 물론 맞는 말 같아서 할 말 없었는데 굳이 이유를 설명하자면
RDB에 저장해 두는 게 추후 데이터 관리에 매우 용이할 것 같아서 저렇게 번거로워도 작업했던 것이 가장 큰 이유였고 언제든 데이터 복구를 위해 사용한 것도 있습니다.
(그냥 RDB를 제대로 써보고 싶었던 욕심도 있었습니다.)
겜린더는 라즈베리파이 환경에서 돌릴 예정이기 때문에 여러가지 요인으로 서버가 다운될 수도 있습니다. (정전, SD카드 수명, 라즈베리파이 수명 등..)
그래서 데이터를 지켜야 하는데 관리를 하려면 아무래도 2중으로 DB를 나누는 것이 좋다고 생각했고
MongoDB는 유저가 볼 수 있는 "Contents DB"라고 생각하고
MariaDB는 서버 단에서 데이터를 관리할 수 있는 DB로 생각하고 있었습니다.
물론 이렇게 되면 데이터 불일치(Data Inconsistency) 현상이 발생할 수 있지만
MariaDB는 데이터를 용이하게 관리하고 백업의 목적성이 크기 때문에 일단 이렇게 유지해 볼까 합니다.
후기
되찾은 본질
처음 겜린더를 만들 때도 겜린더의 본질은 무엇일까 생각했었는데
"출시 예정의 게임을 누구나 빠르고 쉽게 볼 수 있었으면 좋겠다"였습니다.
왜냐하면 친구가 게임 스트리머를 준비하는 데 게임을 일일이 스팀에서 찾기 귀찮아했었기 때문이었죠
하지만 그때는 너무 방대한 스팀 게임들에 압도당해 다른 기능을 만든다던가 본질을 좀 회피했었는데
이제서야 본질에 제대로 맞게 플랫폼이 만들어질 것 같습니다.
생각보다 어렵고 복잡했던 데이터 파이프라인 작업
데이터 전처리 작업이 엄청 힘든 작업일 거라곤 생각하지 못했습니다.
여태 간단하게 수집만하고 이쁘게 표시해주는 크롤링 작업만 해봤었는데요
이렇게 데이터를 하나하나 정제하고 일관성 있게 맞추는 작업까지 하려니 정말 힘든 작업이었지 않나 싶습니다.
예상하지 못하는 변수들이 정말 많은 것 같아요...😂
아직 부족한 점은 많습니다.
사실 DB도 제가 제대로 구성해서 효율적인 구조인지 정확히 잘 몰라서 피드백은 언제나 환영입니다. 댓글로 훈수 좀 해주세요...
작업하다 보니 더러워진 스파게티 코드들은 당연히 정리해야 하고, 제대로 정제되지 않는 데이터도 있어서 그런 부분들을 좀 더 고민해 보고 보강도 해야 합니다.
하지만 여태 테스트를 해봤을 땐 100개 중에 3개(3%) 정도의 데이터가 제대로 정제되지 못해 DB에 중복되어 저장되는 경우도 있었습니다.
(이건 좀 더 수집해보고 확인해야할 것 같습니다.)
이런 부분들은 제가 수 작업을 좀 거쳐 MongoDB로 보내는 작업을 거칠 예정입니다.
그래도 일일이 60개 이상의 게임을 수집하는데 8시간 쓰는것보다 정말 많이 좋다고 생각합니다.
일이 줄었네요 😁

좋은 글 잘 읽고 갑니다!