
드디어 Steam Upcoming 페이지를 스크래핑 하는 시간이 찾아왔습니다.
어떤 전략으로 했고 코드는 어떻게 작성했는지 천천히 리마인드하기 위해 글을 작성합니다.
핵심만 추려서 정리했으니 자세한 부분은 Github 참고해 주세요!
폴더 구성
upcoming
플랫폼 별로 폴더를 만들고 플랫폼 별로 Log와 Backup 폴더를 만들어 문제가 발생할 때 언제든 플랫폼 별로 빠르게 확인할 수 있게 만들었습니다.
Core
자주 사용하는 기능은 core에 따로 분류하였습니다.
어떤 데이터가 필요할까?
겜린더에서 필요한 데이터를 알아보기 위해선 현재 개발 중인 겜린더 앱 상태를 보면...
연보라색의 둥근 사각형이 필요한 데이터입니다.


최대한 단순하게 보자면 총 8가지가 나오게 되는데..
- 게임 이름 + 영문 이름
- 제작사
- 썸네일
- 플랫폼 지원
- 스크린샷
- 게임의 자세한 정보
- 유튜브 트레일러 링크 (이건 나중에 🥲)
- 출시 날짜
게임의 영문 이름까지 수집하는 이유
사용자가 한국어로만 검색하지 않기 때문에 영문 이름도 수집합니다.
겜린더 검색 자동완성 성능을 개선해보기
전략
- 목록 데이터 수집
- 게임 이름, 출시 날짜, 상세 페이지 링크
- 각 게임의 상세 페이지 데이터 수집
- 제작사, 썸네일, 스크린샷, 게임의 상세한 정보
- 성인 게임은 수집 금지
- 데이터 통합
1. 목록 데이터 수집
분석
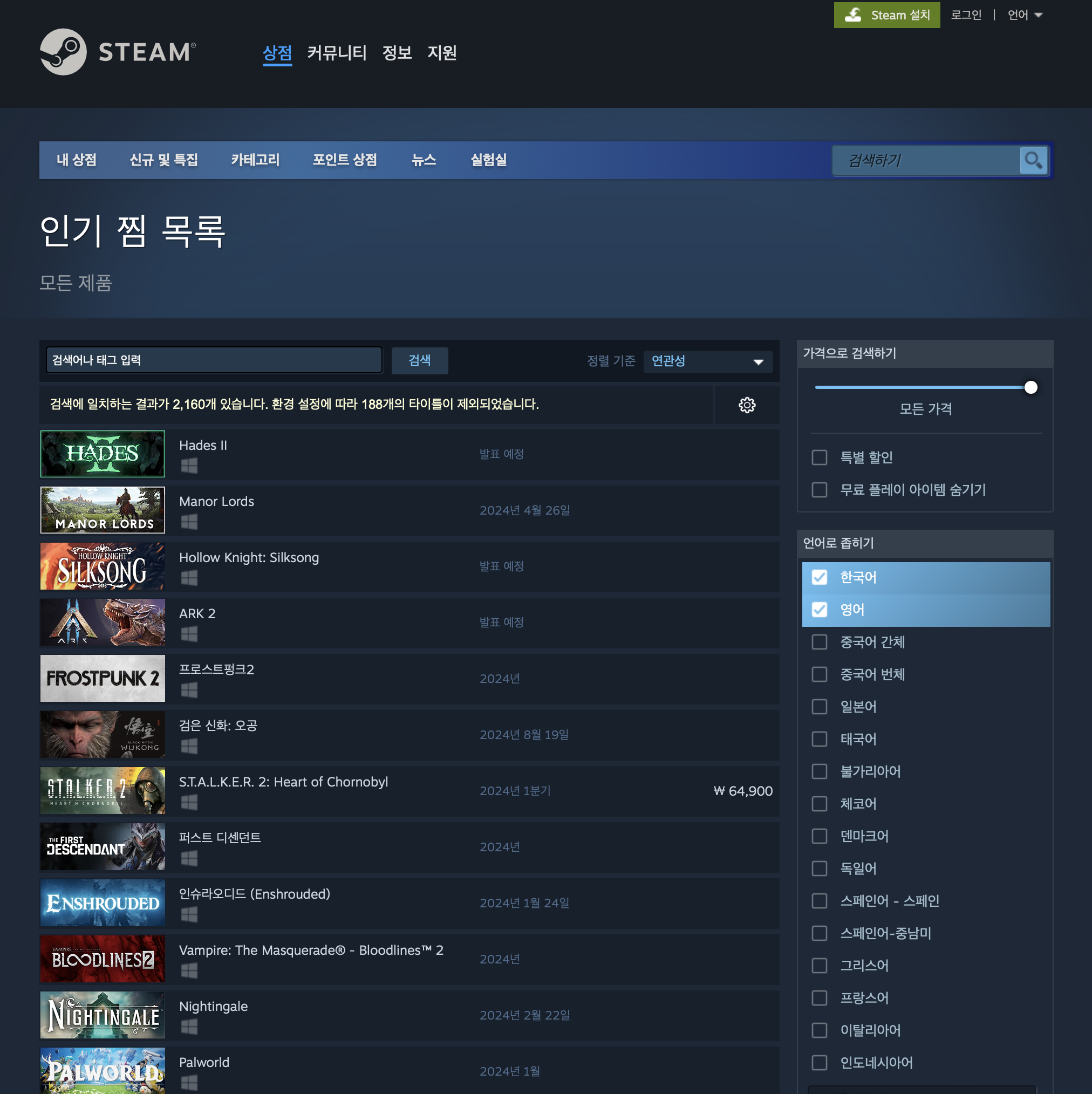 일단 가볍게 페이지를 들어가면 목록들이 나옵니다.
일단 가볍게 페이지를 들어가면 목록들이 나옵니다.
검색에 일치하는 결과가 2,160개가 있다고 나오는데
"오! 그럼 바로 태그 지정해서 수집하면 그만 아닌가!?" 라고 생각하면 큰일 납니다.
 2,160개의 정보를 한 번에 띄우는 것이 아닌 스크롤을 내리면 데이터를 받아오는 구조이기 때문에
2,160개의 정보를 한 번에 띄우는 것이 아닌 스크롤을 내리면 데이터를 받아오는 구조이기 때문에
위의 사항을 고려해 전략을 세우면
1. 스크롤 전의 페이지 전체 높이 값을 알아낸다. (currnetPageHeight)
2. 페이지 스크롤을 한다.
3. 스크롤 후의 페이지 전체 높이 값을 알아낸다. (newPageHeight)
4. 스크롤 전과 스크롤 후의 페이지 높이가 같은지 비교한다.
5. 같지 않다면 아직 불러올 컨텐츠가 있다는 의미이기 때문에 스크롤을 계속한다.
6. 만약 값이 같다면 스크롤을 다 했다는 의미로 해석해 스크롤을 중지한다.
이런 부분을 인지하고 설계한 플로우차트를 보면
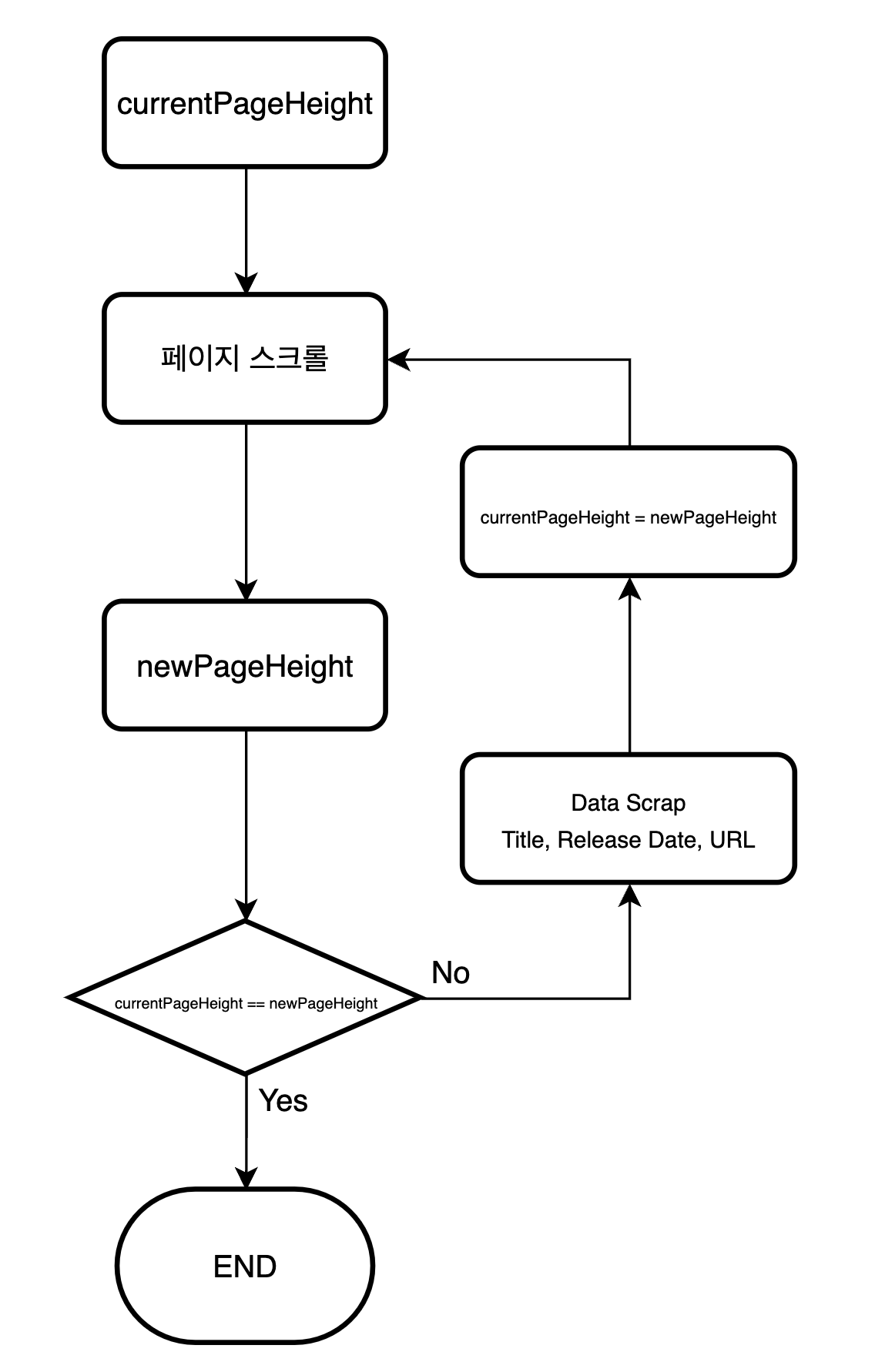
currentPageHeight : 현재 페이지 높이
newPageHeight : 스크롤 후 페이지 높이
두 변수의 높이 값이 다르다면 게임 이름, 출시 날짜 수집
두 변수의 높이 값이 같다면 스크롤 중지
위의 설계를 코드로 구현해 봅시다!
코드 구현
- 페이지 언어 한국어로 바꿔주기
 가장 먼저 수집하기 전에 driver가 실행되고 페이지를 불러오면 영문으로 표시되는데 페이지를 한국어로 바꿔줘야 합니다.
가장 먼저 수집하기 전에 driver가 실행되고 페이지를 불러오면 영문으로 표시되는데 페이지를 한국어로 바꿔줘야 합니다.
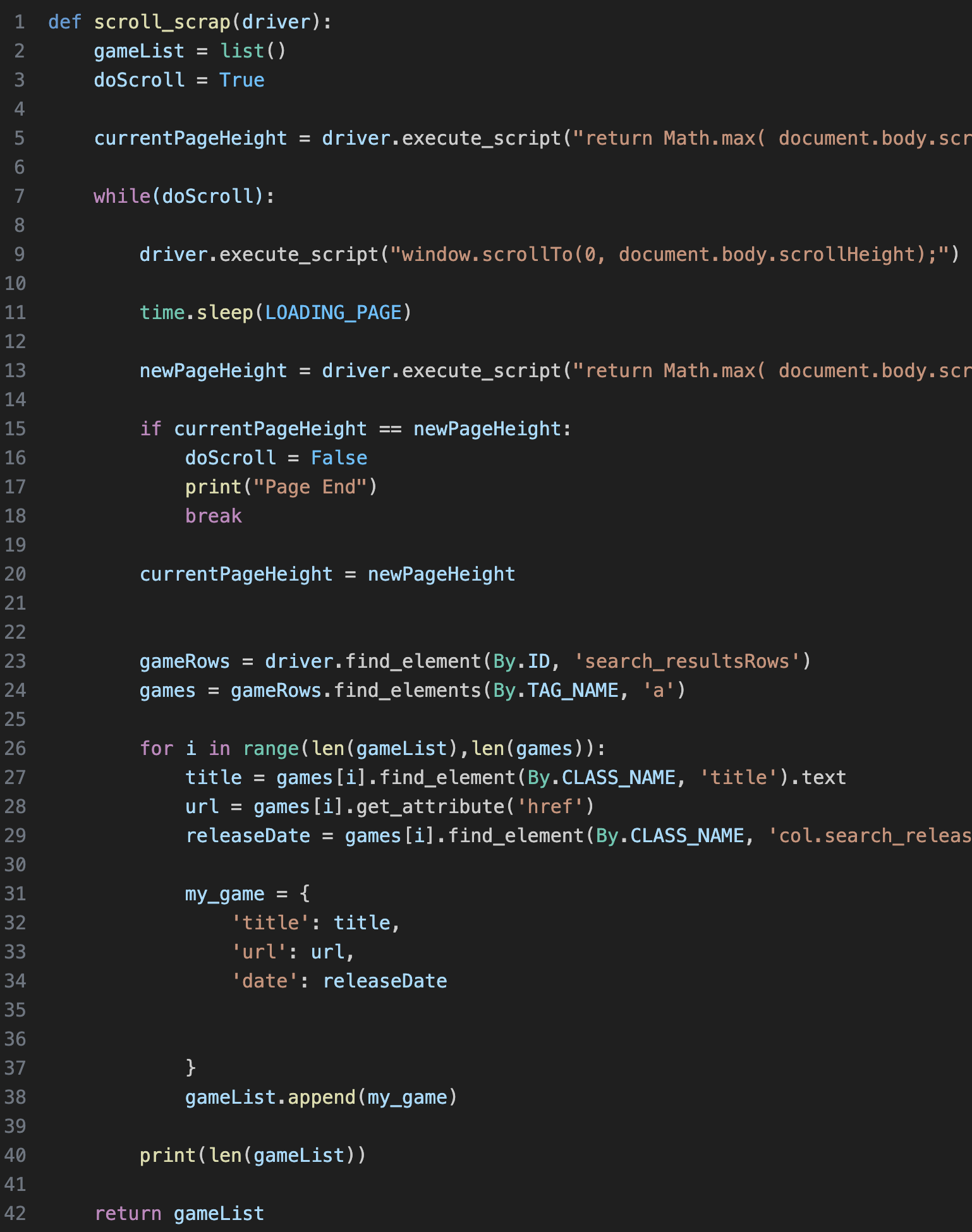
my_game에 게임 이름, 출시 날짜, 상세 페이지 링크까지 수집
실제 결과 값
목록 데이터 수집은 이렇게 마무리하고 이제 상세 페이지 링크를 활용해
상세 페이지를 수집해 봅시다!
2. 각 게임의 상세 페이지 데이터 수집
이제 상세 페이지 수집을 위해 어떻게 해야할지 고민해 봅시다.
일단 저는 대전제 1가지는 무조건 걸었습니다.
"노출이 정말로 심한 성인 게임은 최대한 수집을 하지 않는다."
이 부분을 어떻게 해결했는지 천천히 과정을 설명드리면서 진행하겠습니다.
상세 페이지 분석
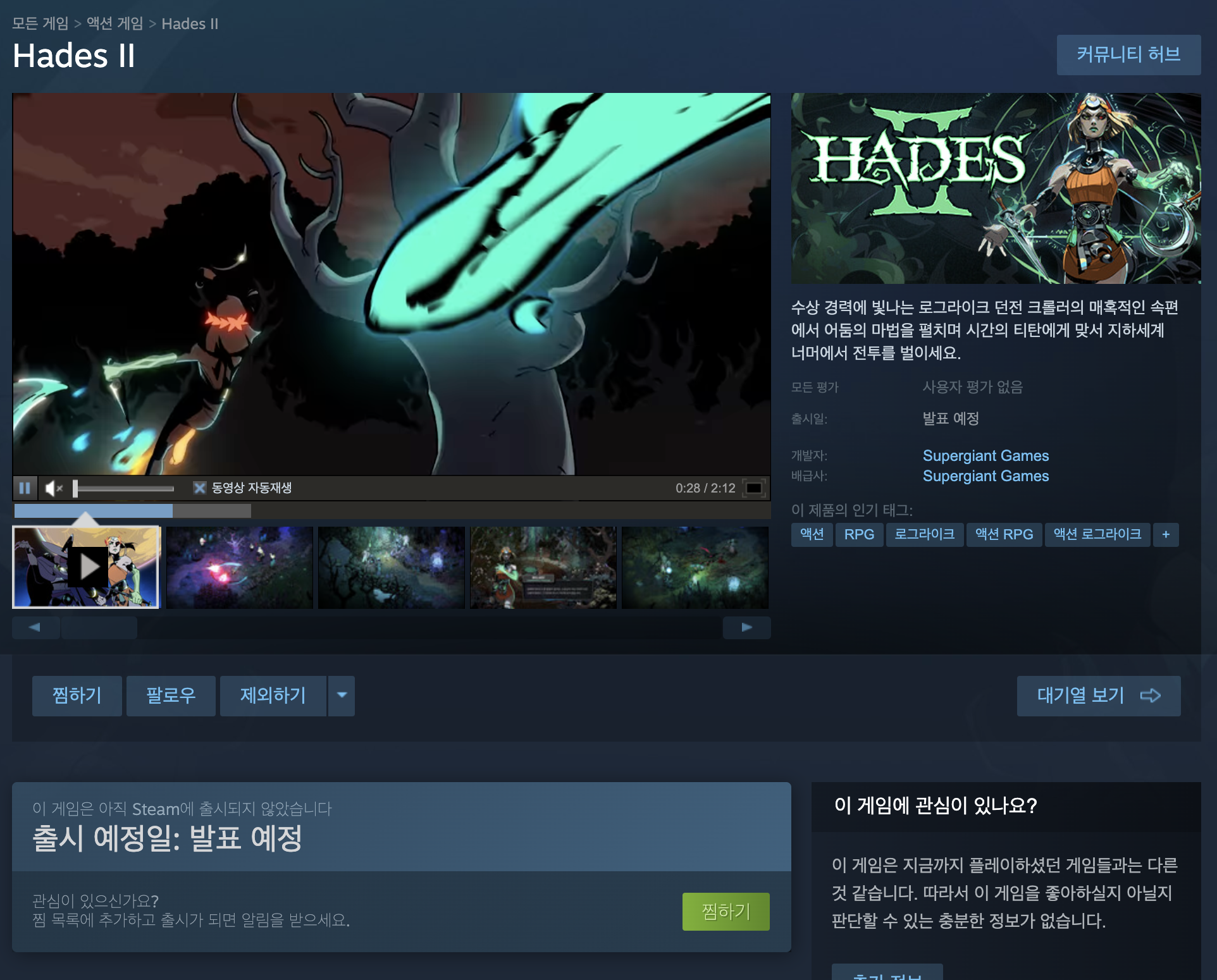 잠깐 숨은 그림 찾기를 해볼까 합니다.
잠깐 숨은 그림 찾기를 해볼까 합니다.
여기서 찾을 수 있는 요소는 총 4가지가 존재합니다.
게임 이름(영문 이름), 개발자, 태그, 스크린샷
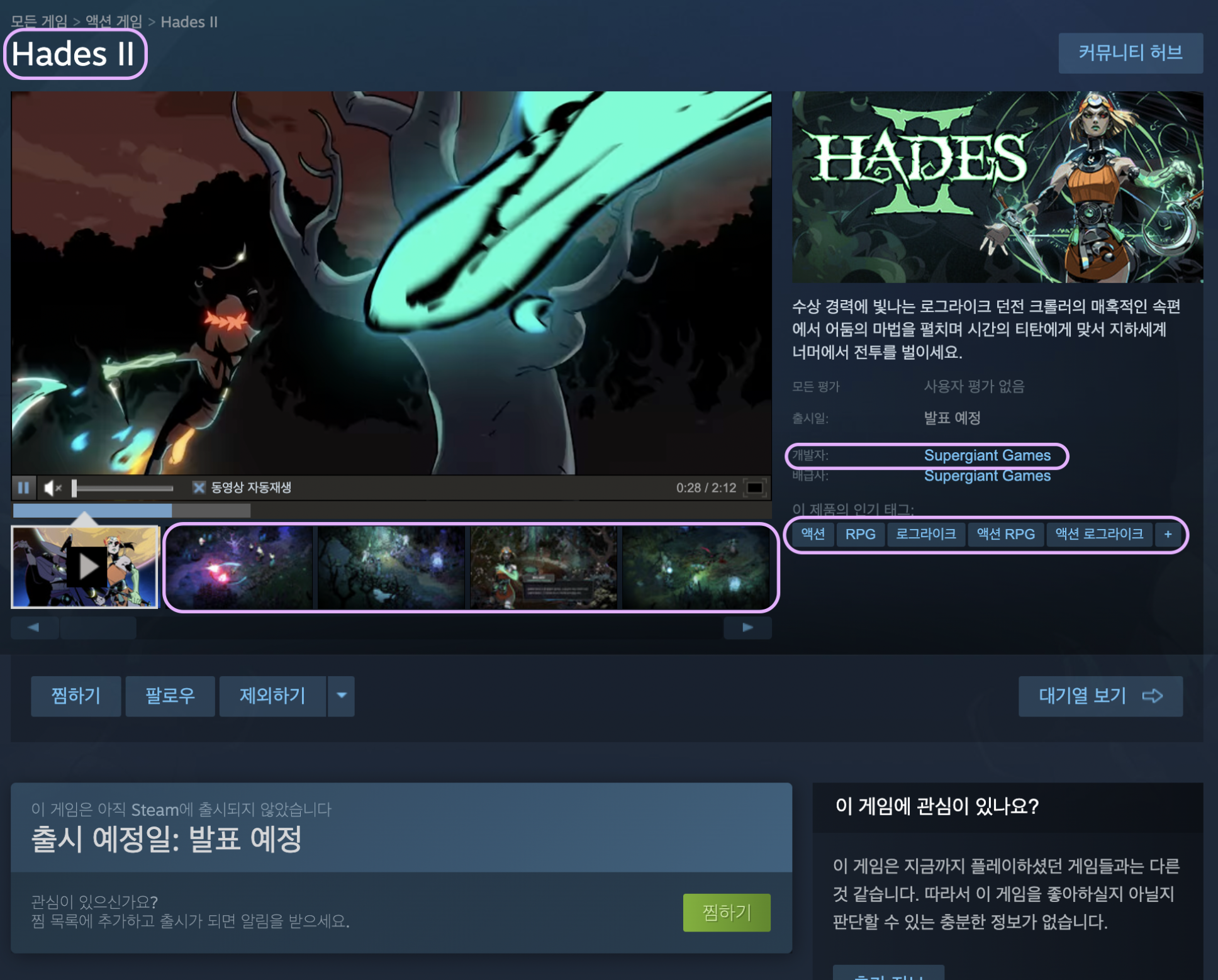
또 하단으로 내리면 게임의 상세 정보가 나옵니다.
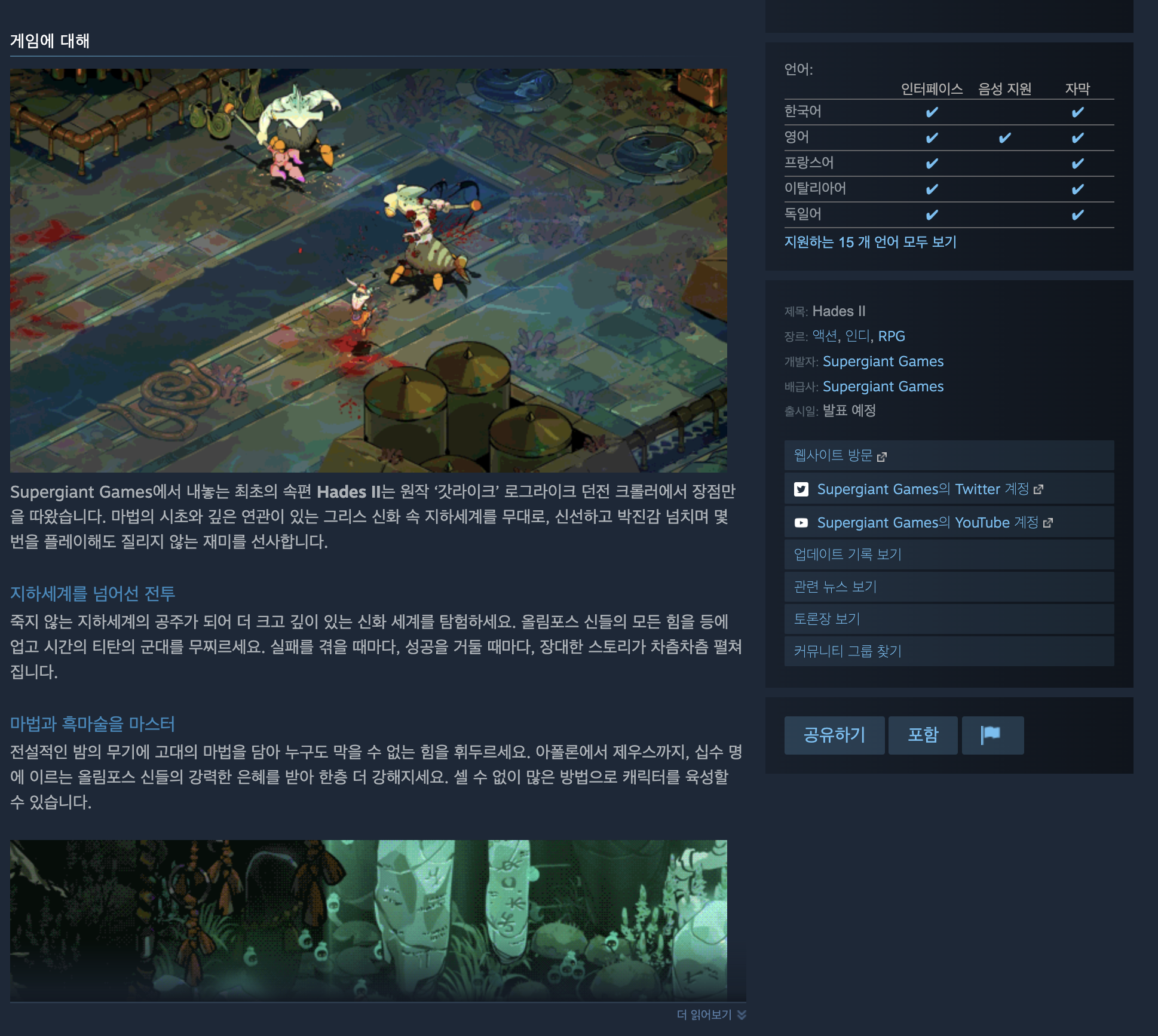
그럼 총 5가지를 수집할 수 있네요!
수집한 상세 페이지 데이터와 목록 페이지 데이터를 하나로 통합해 CSV 파일로 통합하는 과정까지 해봅시다!
코드 구현
성인 게임 인증
스팀 성인 게임 인증은 특징이 있습니다.
한 번만 인증하면 모든 성인 게임 열람이 가능합니다.
그래서 저는 GTA 5의 페이지로 먼저 성인 게임 인증을 하고 상세 페이지를 수집하기 시작했습니다.
성인 게임 인증
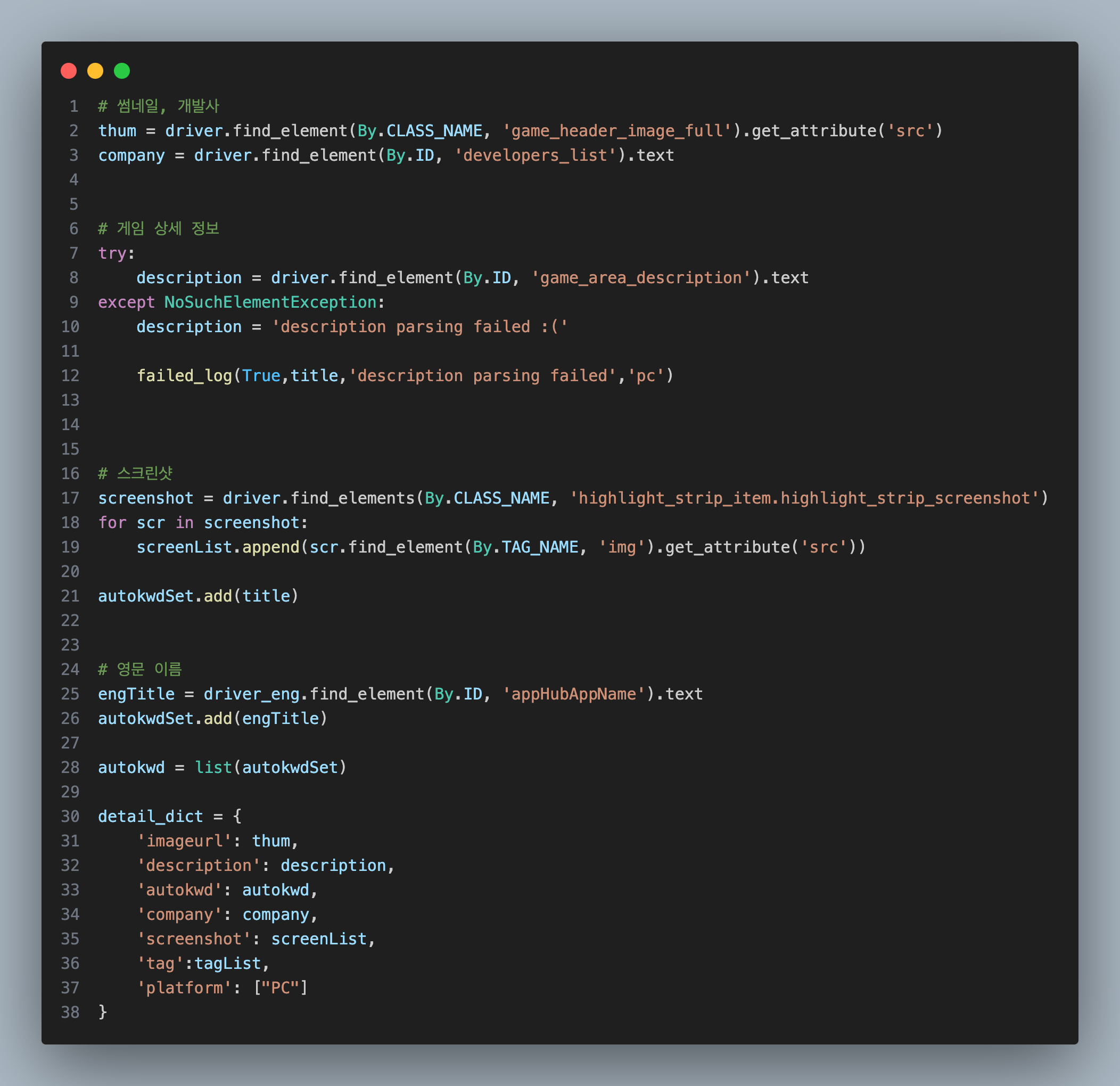
영문 이름 수집 방법
영문 이름을 수집하기 위해서 webdriver를 2개를 실행해 진행하기로 했습니다.
driver 1개로 하면 계속 언어를 바꿔가면서 수집해야 하는데 언어 전환할 때 소요시간이 약 3초 정도가 소요됩니다.
단순하게 3초 * 2000개의 게임 = 6000초의 시간이 그냥 소비가 되기 때문에
2개로 실행하는 것이 더 합리적이라 판단했습니다.
driver : 한국어
driver_eng : 영어driver은 이미 목록 데이터 수집할 때 한국어로 변경하였고
driver_eng는 새로운 프로세스로 실행이 되기 때문에 페이지를 불러올 때 영문 페이지가 나옵니다.
성인 게임 수집 시 문제점과 해결 방안
"노출이 정말로 심한 성인 게임은 최대한 수집을 하지 않는다."
성인 게임은 최대한 보수적으로 수집한다고 했지만
우리가 하는 게임 중에 성인 인증이 필요한 게임은 생각보다 많았습니다.
(GTA, 용과 같이 시리즈 등..)
그리고 분명 노출이 엄청 심한 성인 게임인데도 오히려 성인 인증을 거치지 않는 게임들이 많았기 때문에 이걸 필터링을 어찌해야 할까... 고민을 정말 많이 했습니다.
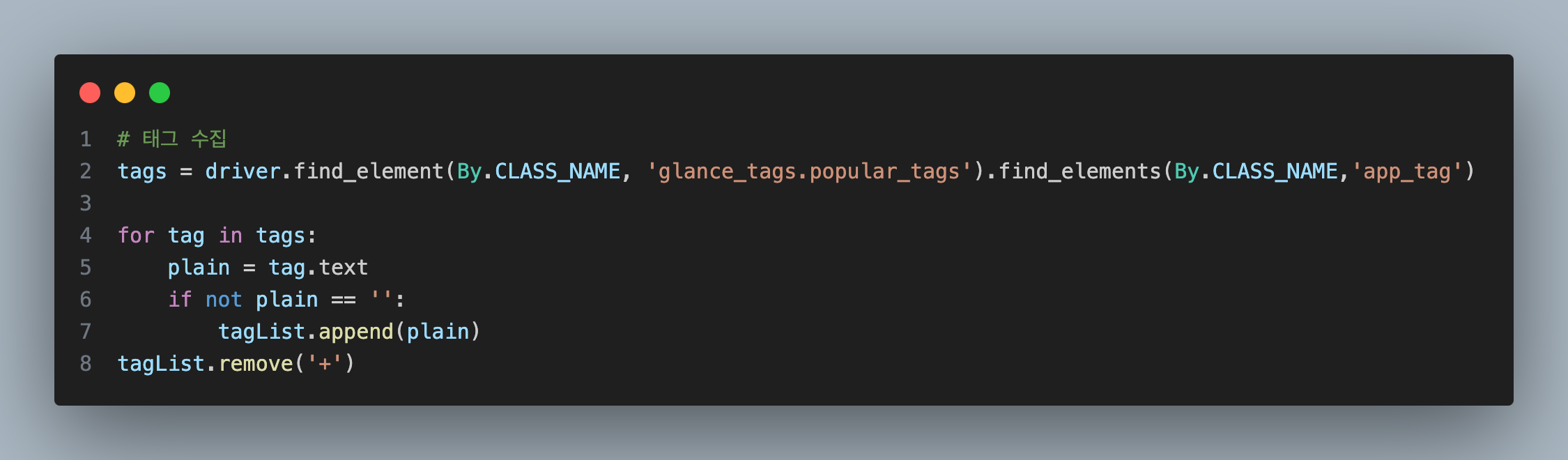
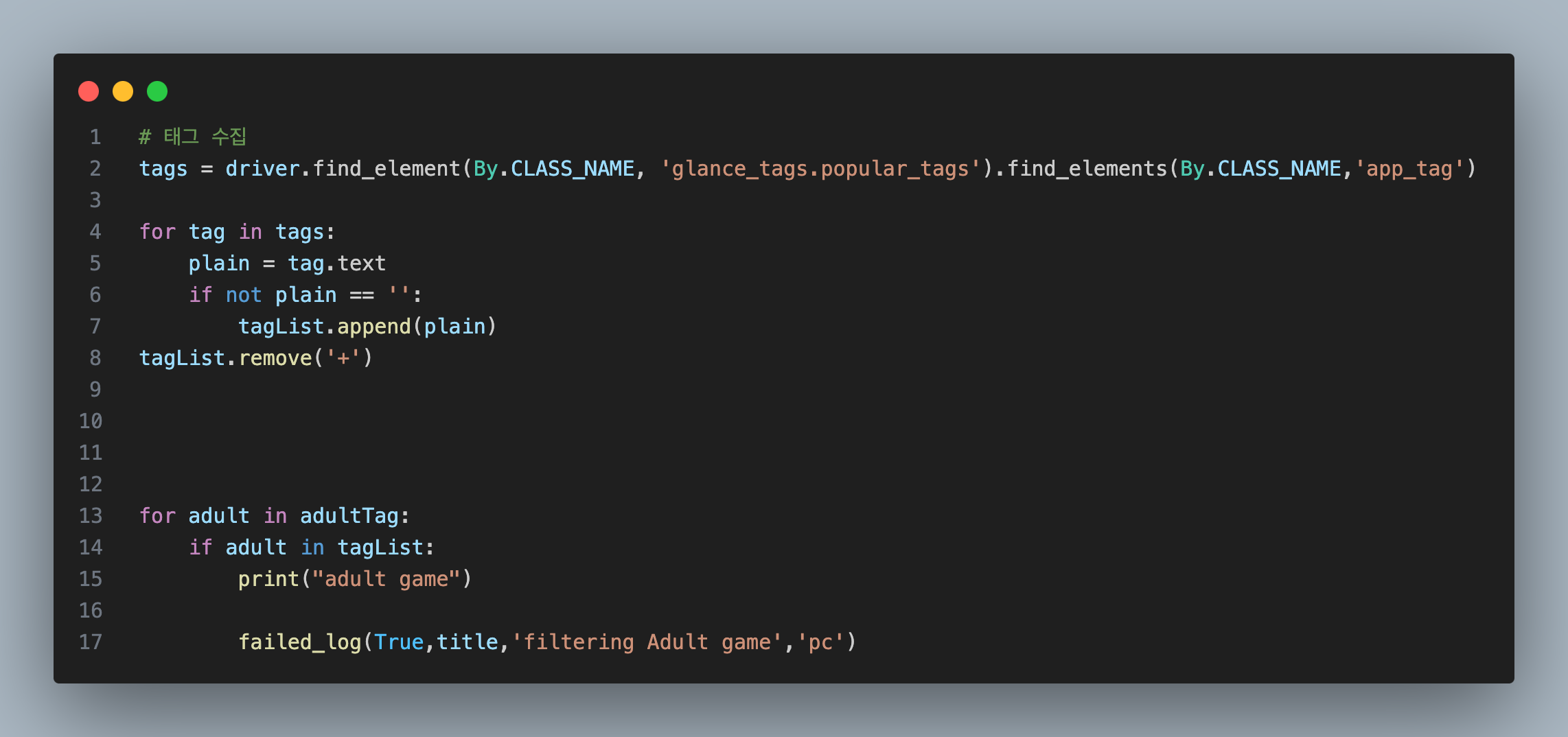
그래서 생각한 방안 중 하나가 태그를 이용한 필터링을 생각해냈습니다.
정말 노출이 심한 성인 게임을 찾아보면서 공통적으로 들어가는 태그가 있었는데
대표적으로 '헨타이','후방주의','선정적인 내용' 이런 태그가 무조건 상위 태그에 존재하는 사실을 알았습니다.
실제로 필터링 되었던 게임의 태그...
그래서 저런 게임들을 필터링하기 위해 태그를 수집했고 위의 3개 중 1개라도 존재하면 수집하지 않는 방향으로 구성하였습니다.

수집 완료된 데이터
이제 하나로 통합해 봅시다
목록 + 상세 페이지 데이터 하나로 통합시키기
데이터를 통합시키는 건 Pandas의 concat 함수를 이용해 하나로 통합시켰습니다.
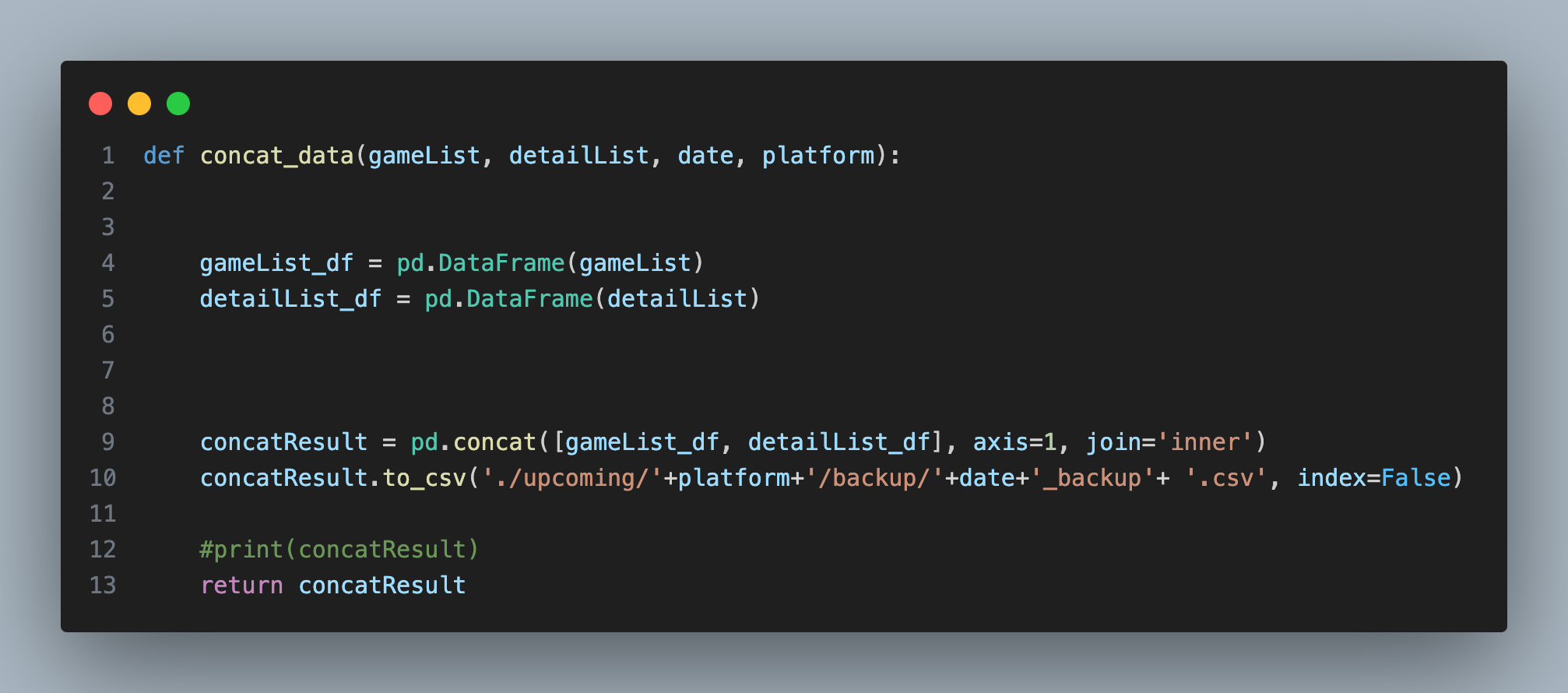
백업을 위한 csv까지 생성할 수 있게 하였고
이 함수는 자주 사용하기 때문에 Core에 따로 분리해 언제든 불러와 사용할 수 있게 만들었습니다.
3. 결과
csv 파일은 깃허브에서 확인해 주시면 감사하겠습니다 :)
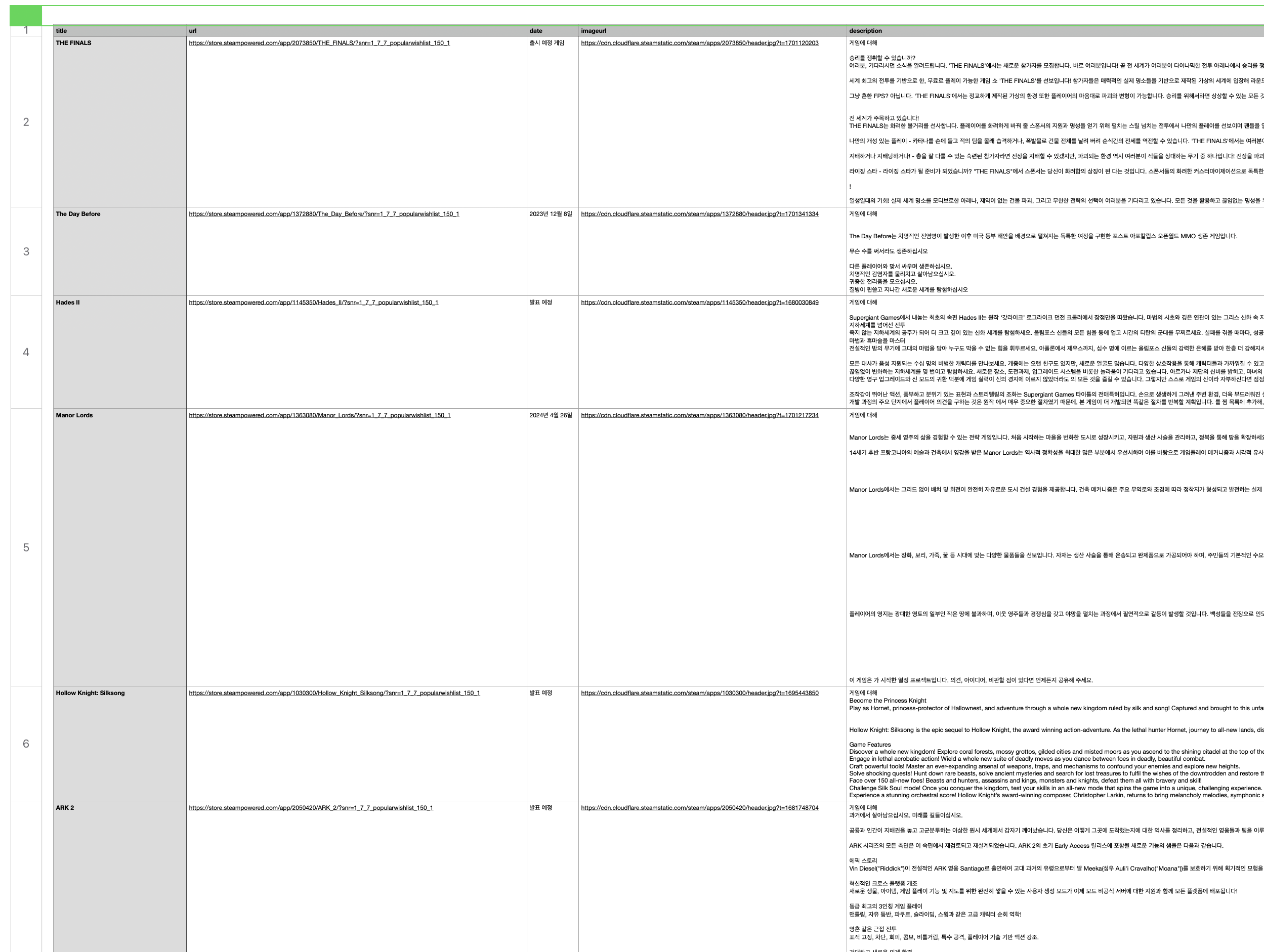
깔끔하게 csv로 통합해서 결과물이 나오는데
이 데이터를 추후에는 MariaDB에 정리할 예정입니다.
아무래도 이런 데이터는 MongoDB보단 RDB인 MariaDB로 해야 가독성이나 추후 join을 이용한 데이터 조회에도 도움이 될 것 같다고 판단했습니다.
4. 후기
이제 겨우 스팀의 데이터를 수집했지만 할 일이 정말 많습니다.
겜린더라는 프로젝트를 하면서 많이 느낀 부분은
원하는 기능을 구현하기 위해 여러 가지 조사를 하면서
내가 이 기술을 왜 써야 하는가에 대해 항상 스스로 질문하고 합리적인 판단을 하는 과정이
정말 저에겐 공부할 목적을 만들 수 있어 정말 좋은 것 같습니다.
단, 조심해야 할 건
단순히 구현하는 것에 목적을 두는 게 아닌 제대로 원리를 배워가면서 추후 협업을 위한 가독성이 좋은 코드를 작성하는 것을 목표로 프로젝트를 진행해야겠네요.
