Chapter 1
Redis Essential의 내용을 정리하였습니다.
번역해서 정리했기 때문에 오역이 있을 수 있습니다.
부족하거나 모르는 내용은 구글링을 통해 정리하였습니다.
Index
- Redis 기본 개념
- Redis Data Types
- Strings
- Lists
- Hashes
Redis 기본 개념
Redis? (REmote DIctionary Server)
고성능 Key-Value를 지원하는 NoSQL Data Structure 서버
유추해보자
Dictionary? 내가 아는 Dictionary는 파이썬의 Dictionary인데 Hash Table이라는 자료구조 기반으로 작동한다. Redis도 Hash Table를 활용해서 데이터를 저장하는 건가?
왜 고성능 Key-Value일까?
수 많은 데이터 타입을 지원한다. (기본 데이터 타입 : Chapter1, 더 많은 데이터 타입 : Chapter 2)
Redis의 모든 데이터는 메모리에 저장된다. (InMemory 저장 방식)
Memory는 Disk보다 속도가 빠르다. 기존 Disk 기반의 DB보다 훨씬 빠르지만 전원 공급이 끊어지면 Memory의 휘발성 특징 때문에 데이터가 전부 사라진다.
간단하게 짚어보는 CS 지식
- (CPU > Memory > Disk) 순으로 CPU가 가장 처리속도가 빠르고 Disk가 가장 느리다
- Memory 종류
DRAM (Dynamic Random Access Memory) : 우리가 흔히 쓰는 램이 DRAM이다.
SRAM (Static RAM) : 용량이 작은 대신 속도가 DRAM보다 빠르다. CPU의 캐시메모리에 활용
Redis의 데이터는 우리가 쓰는 DRAM에 저장된다.
그럼 데이터 저장을 아예 못하는가?
아니다. Redis는 SnapShot(RDB), 혹은 모든 명령의 시퀀스가 포함된 파일(AOF)로 Disk에 저장할 수 있다. 추후 자세하게 알아보자 😃
그 외에도
Redis는 Key Expiration, Transactions, Publish, Subscribe 기능들을 가지고 있다.
Redis Data Types
Redis의 기본적인 데이터 타입들을 알아보자
Strings
우리가 아는 문자열이다.
String은 값과 사용 된 명령에 따라 integer, float, text string, bitmap으로 작동할 수 있다.
String 값은 Text 혹은 Binary 데이터의 크기가 512MB를 초과할 수 없다.
Cache mechanisms(캐시 매커니즘)
Redis는 Text 혹은 Binary 데이터를 캐시로 이용할 수 있다.
Command
SET, GET, MSET, MGET으로 간단한 캐시 시스템 구현이 가능하다.
SET : Key - Value 추가
GET : Key를 대입하면 Value를 출력
MSET : 하나의 명령어로 여러개의 Key - Value 추가
MGET : 하나의 명령어로 여려개 Key를 입력해 각각의 Value를 출력
Example
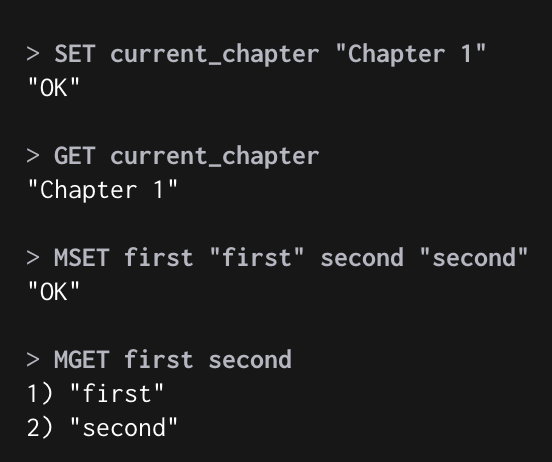
Cache with Automatic expiration (캐시와 자동 만료)
특정 시간이 지나면 자동으로 만료되고
이는 데이터베이스 쿼리를 실행하는데 오랜 시간이 걸리고, 지정된 기간동안 캐시될 수 있는 경우 매우 유용하다.
Command
SETEX, EXPIRE, EXPIREAT으로 구현이 가능하다.
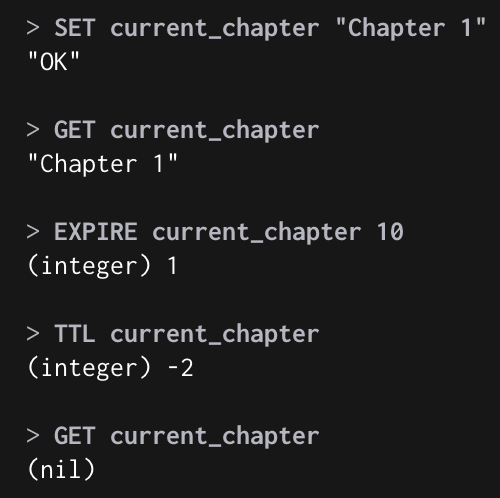
TTL (Time To Live)
EXPIRE : Key에 만료시간 추가 (단위 : 초, TTL)
**EXPIREAT** : Key에 만료시간 추가 (단위 : Unix Timestamp)
~~SETEX : Deprecated 사용하지 않음~~
TTL (Time To Live)
표시 상태
양수 : 만료 시간이 주어진 상태 초 단위로 점점 감소한다.
-2 : 키가 만료되었거나, 존재하지 않는 경우
-1 : 키가 존재하지만 Expire을 설정하지 않은 경우
Example
Counting
간단하게 카운트를 구현할 수 있는 기능
좋은 예시로 조회수나 좋아요 같은 카운팅을 활용한 기능을 만들 수 있다.
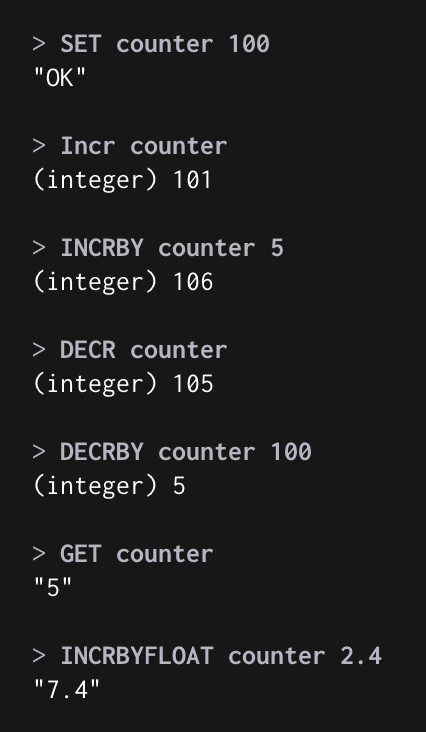
Command (Atomic)
INCR : +1
DECR : -1
INCRBY : 원하는 값 증가
DECRBY : 원하는 값 감소
INCRBYFLOAT : 원하는 소수점 값 증가
DECRBYFLOAT : 원하는 소수점 값 감소
Atomic?
해당 명령을 수행하는 도중에 다른 명령이 끼어들 수 없는 명령
Example
SET counter 100
→ OK
INCR counter
→ (integer) 101
INCRBY counter 5
→ (integer) 106
DECR counter
→ (integer) 105
DECRBY counter 100
→ (integer) 5
GET counter
→ “5”
INCRBYFLOAT counter 2.4
→ “7.4”
Counting 명령어는 단일 명령으로만 처리할 수 있다.
MSET 같은 멀티작업으로 여러개의 Key를 동시에 카운팅을 할 수 없게 설계되어있단 의미
Example
만약 두 개 혹은 여러 개의 클라이언트가 동시에 INCR key 명령어를 실행할 경우 중복처리가 되지 않고 모두 처리할 수 있다.
Why?
“Redis is Single threaded”
레디스는 싱글 스레드로 동작하고 이 의미는 항상 하나의 명령을 수행하기 때문이다.
Lists
List는 Redis에서 매우 유연한 데이터 타입이다.
단순 수집, Stack, Queue 처럼 동작하게 만들 수 있다.
Blocking Command
Redis의 List에는 Blocking Command가 있다.
클라이언트가 비어있는 리스트에 Blocking Command를 실행할 때, 클라이언트는 List에 새로운 Element가 추가될 때까지 기다린다.
List 성능
Redis의 List는 Linked List 라서 리스트의 처음 또는 끝에서 Element의 추가 및 삭제는 항상 O(1) 즉 일정 시간의 성능을 가진다.
Element 접근시간 : O(N)
첫번째 또는 마지막 Element 접근 시간 : O(1)
List Encoding
List 크기의 엘리먼트가 list-max-ziplist-entires 설정보다 작고, List 의 개별 바이트가 list-max-ziplist-value 설정보다 작으면
→ ziplist로 최적화
List 크기의 엘리먼트가 list-max-ziplist-entires 설정보다 크거나, List 의 개별 엘리먼트의 바이트가 list-max-ziplist-value 설정보다 크면 → Linked List로 최적화
하지만
현재는 QuickList만 사용한다.
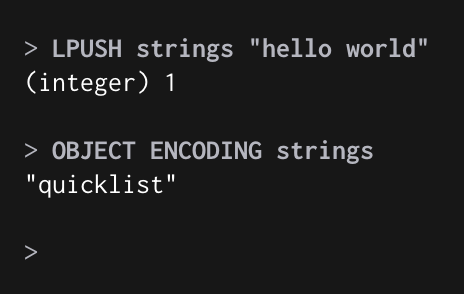
QuickList
- ziplist가 여러개 리스트로 되어 있는 형태
- ziplist의 마지막보다 찾는 인덱스가 다음에 있으면 다음 ziplist로 이동하는 형식으로 다수를 skip하여 리스트 탐색 시간을 줄였다고 한다…
Redis의 List는 최대 2^32 - 1의 Element를 가질 수 있다.
Command
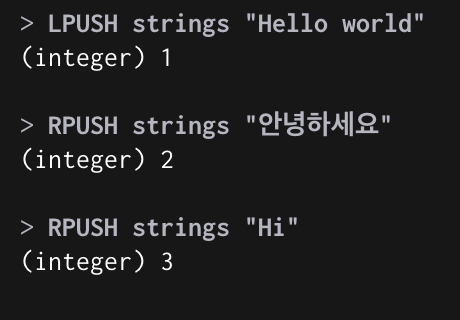
LPUSH : List 처음에 Element 추가
RPUSH : List 마지막에 Element 추가
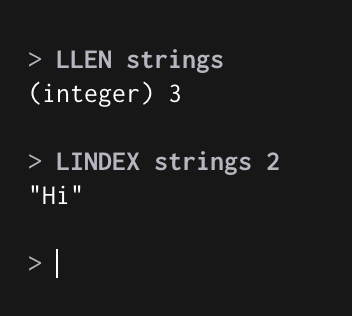
LLEN : List 길이 출력 (Length)
LINDEX : List의 Index 값을 볼 수 있음 (0부터 시작)
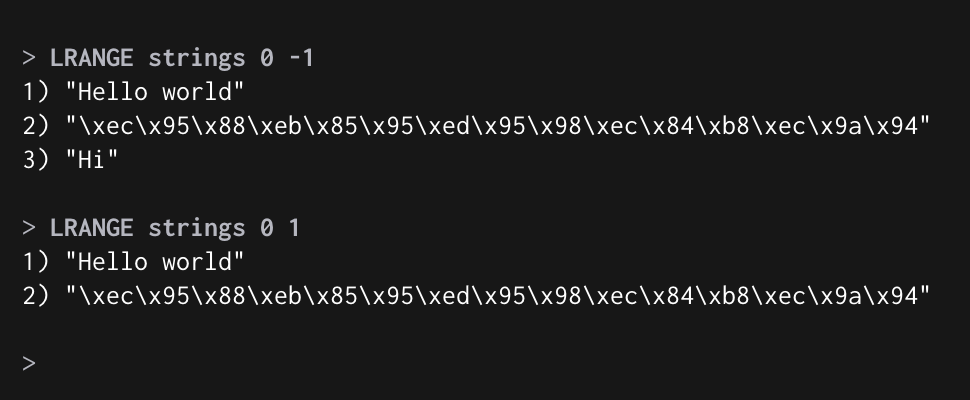
LRANGE : For문처럼 Index 범위를 지정해 지정된 모든 값을 출력한다.
-1은 List의 마지막 Element
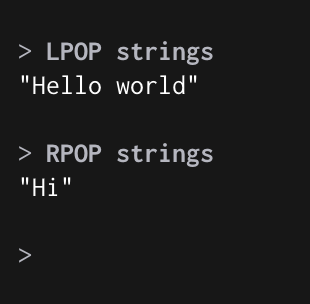
LPOP : 가장 처음 Element 삭제 후 출력
RPOP : 가장 마지막 Element 삭제 후 출력
BLPOP, BRPOP : LPOP과 RPOP을 Blocking하면서 기다린다.
구글링을 해보니 Message Queue처럼 활용이 가능하다고 한다. 나중에 예제를 만들어보자
Example
LPUSH, RPUSH
LLEN, LINDEX
LRANGE
LPOP, RPOP
BLPOP, BRPOP

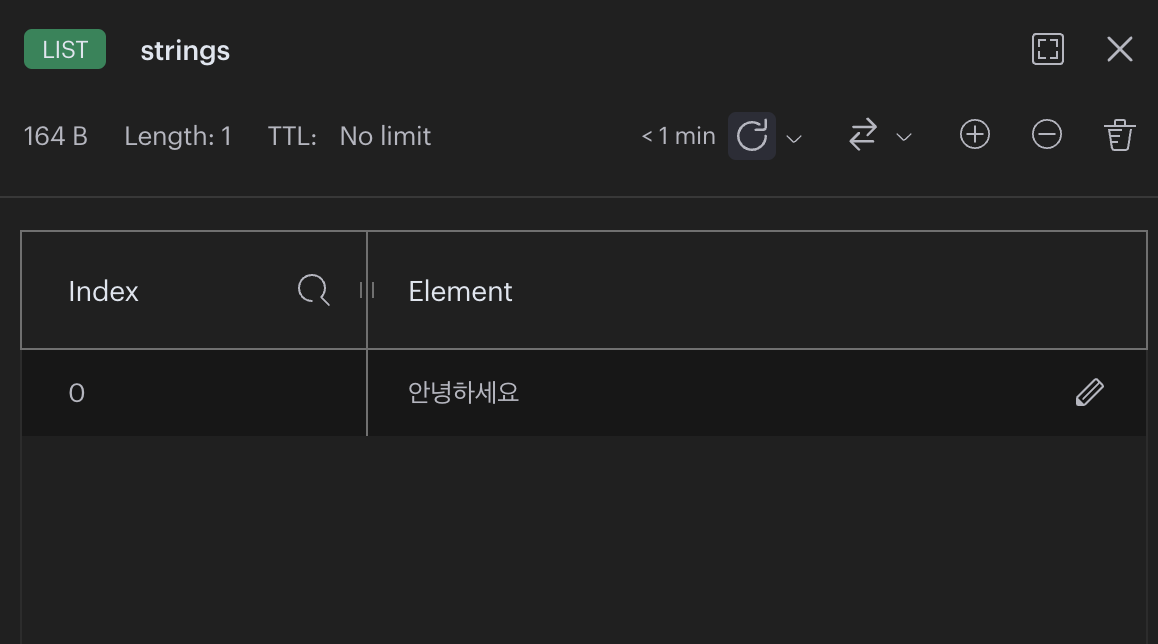
strings Key에 Element가 있을 경우 → strings에 있는 “안녕하세요”를 POP 하였다.
strings Key가 없을 경우 → Executing command 라고 뜨고 만료시간 30000초가 넘기 전까지 대기한다.
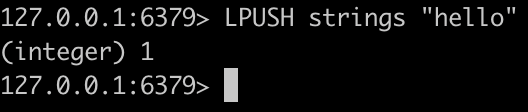
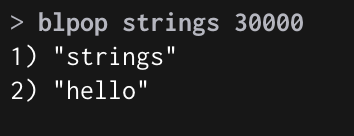
만료시간 이내에 strings key에 “hello” Element를 추가 → 대기하던 blpop명령어가 동작해 출력
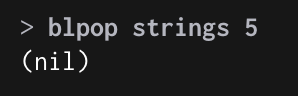
만료시간이 지나면 → (nil)을 출력
Hashes
메모리를 효율적으로 사용하고 데이터를 빠르게 찾도록 최적화 되어있다.
Field name 그리고 Value 둘 다 String으로 구성되어있다.
따라서 Hash는 문자열을 문자열로 매핑한다.
Hash는 내부적으로 ziplist와 Hash Table이 될 수 있다.
Ziplist & Hash Table
Ziplist? → 메모리 효율화에 목적을 둔 양쪽으로 연결된 리스트 (연결 리스트)
ziplist는 정수를 일련의 문자로 저장하지 않고 실제 정수의 값으로 저장한다.
ziplist는 메모리 최적화가 되어있어도 일정한 시간 내로 검색이 수행 되지는 않는다.
Hash Table에서는 일정한 시간 내로 검색은 되지만 메모리 최적화가 이루어지지 않는다.
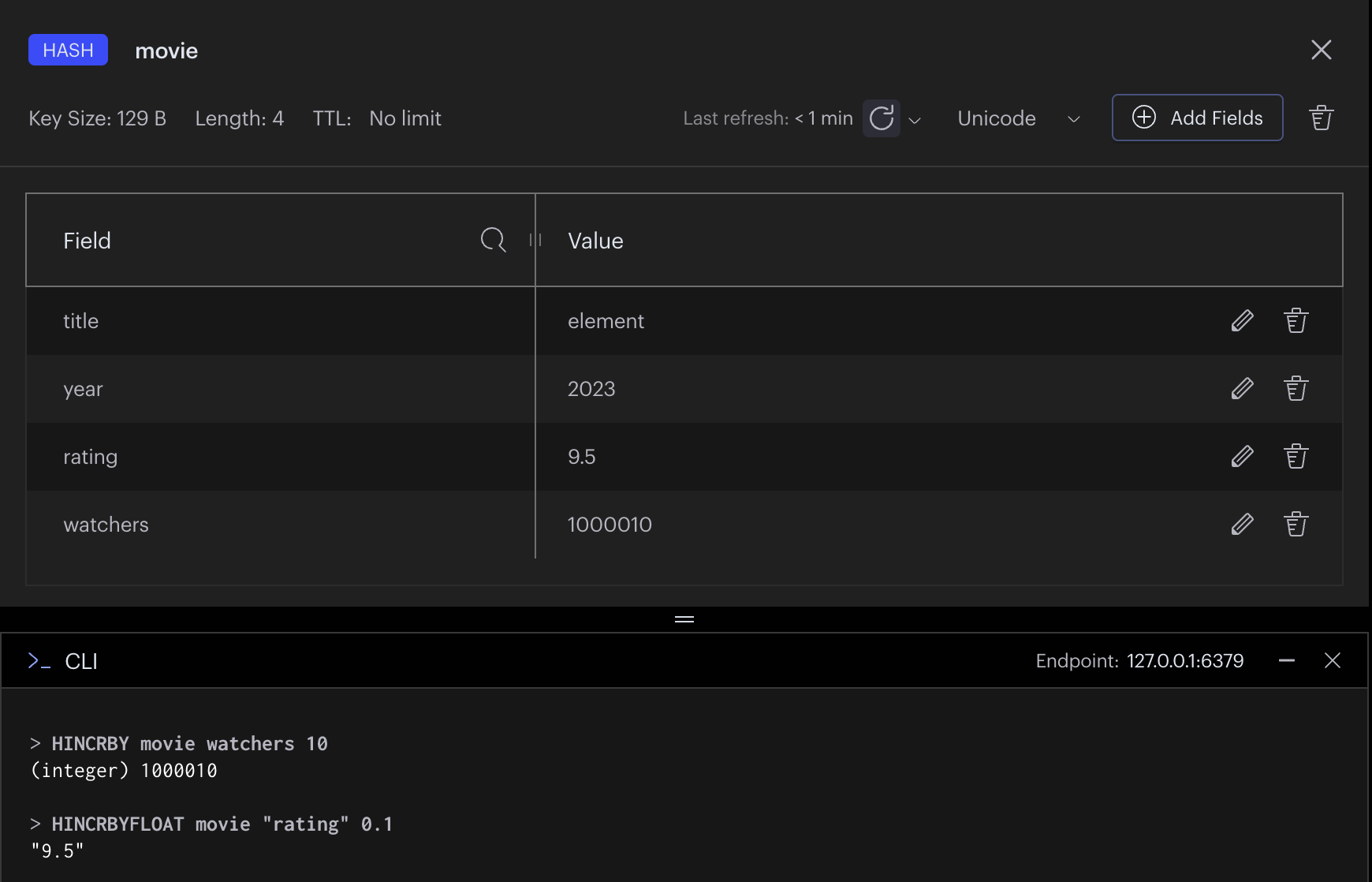
Command
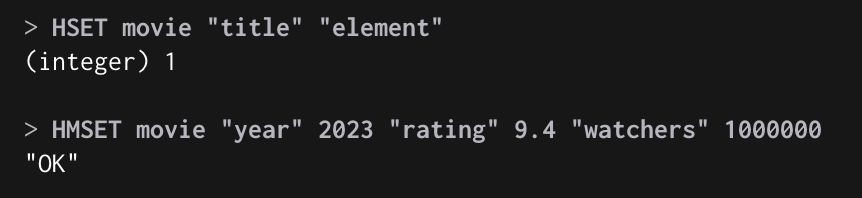
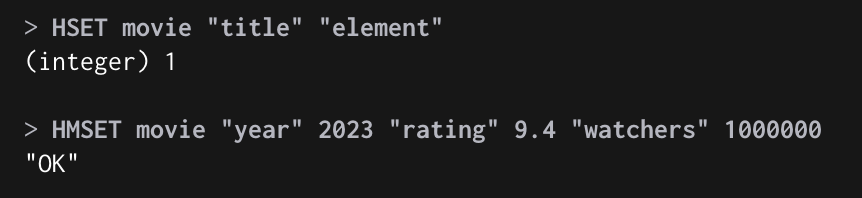
HSET, HMSET : Key “Field name” Value 형식으로 등록
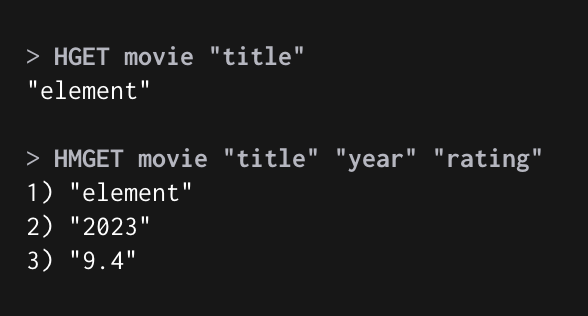
HGET, HMGET : Key “Field name” 으로 조회
HINCR : +1
HINCRBY : 주어진 정수 값 증가
HDECR : -1
HDECRBY : 주어진 정수 값 감소
HINCRBYFLOAT, HDECRBYFLOAT : 주어진 정수 혹은 부동소수점 만큼 필드를 증가 감소 시킴.
Example
HSET, HMSET
HGET, HMGET
HINCRBY, HINCRBYFLOAT