Optimization & Gradient Descent
Optimization
Optimization(최적화)는 Loss function(손실 함수)의 값을 최소화하는 파라미터를 구하는 과정입니다. 손실 함수는 모델의 예측값과 실제 정답의 차이를 비교하는 함수입니다. 따라서 손실 함수의 값을 최소화하는 최적화란 모델의 예측값과 실제 값의 오차를 줄이는 과정입니다. 머신러닝/딥러닝에서는 이 Loss function을 최적화시킴으로 학습을 진행합니다. 그렇기에 최적화 지점을 찾는 것은 굉장히 중요한 작업입니다.
Gradient Descent
Gradient Descent란?
Gradient Descent(경사 하강법)이란 딥러닝 알고리즘을 학습시킬 때 사용되는 최적화 방법 중 하나입니다. 딥러닝 알고리즘을 학습할 경우, Train Data(학습 데이터)의 입력을 변경할 수 없기에 Loss function 값의 변화에 따라 Weight(가중치) 혹은 bias(편향)를 업데이트해야 합니다.
Gradient Descent는 미분 개념을 적용하여 Loss function의 minimum을 찾기 위해 반복적으로 Weight와 bias를 업데이트해서 최적화 지점을 찾는 알고리즘입니다. Gradient의 반대 방향으로 이동하여 최적화 지점을 찾습니다. 아래의 그림은 Gradient Descent가 어떻게 Loss function의 minimum을 찾아 경사를 타고 하강하는지 보여줍니다.
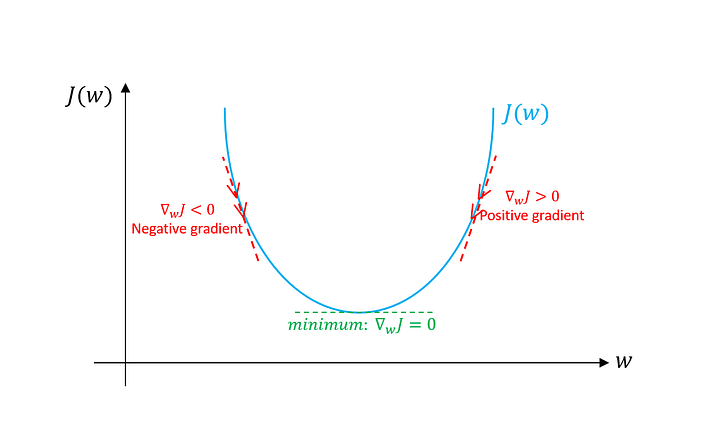
[그림 1] 출처 : https://towardsdatascience.com/gradient-descent-algorithm-and-its-variants-10f652806a3
앞서 Gradient Descent는 미분 개념을 적용했다고 언급했습니다. [그림 1]을 보면 좌우 어디든 임의의 gradient를 선정합니다. 이후 최적의 가중치를 찾기 위해 손실 함수를 에 대해 편미분하고, Learning rate(학습률)과 곱합니다. 이후 곱한 값을 에서 빼줍니다. 수식은 다음과 같습니다.
수식을 확인해보면, gradient 값을 빼주는 것을 볼 수 있습니다. Gradient Descent는 Loss function을 최소화시켜 모델의 예측값과 정답의 차이를 줄여 나갑니다. Gradient가 양의 값이라면 현재 파라미터를 변수로 하는 loss function의 값을 줄여야 하고, 음의 값이라면 반대로 움직여야 합니다. 그렇기에 현재 지점에서 Learning rate와 gradient를 곱하여 빼주는 형태로 업데이트를 합니다. Gradient Descent는 이러한 과정을 의 값이 변하지 않을 때까지 반복해서 진행합니다.

[그림 2] 출처: https://towardsdatascience.com/understanding-gradient-descent-and-adam-optimization-472ae8a78c10
따라서 Learning rate(학습률)의 설정이 중요하다는 것을 알 수 있습니다. 학습률이 너무 크면 최소점으로 수렴하는 것이 아니라 발산할 가능성이 있습니다. 학습률이 너무 작다면 수렴이 너무 늦어집니다. 그렇기 때문에 적절한 학습률을 선택하는 것은 매우 중요합니다.

[그림 3] 출처: https://www.jeremyjordan.me/nn-learning-rate/
Gradient Descent를 사용하면 위의 그림과 같은 볼록 함수(Convex function)에서는 어디서 시작하더라도 최적의 가중치에 도달할 수 있습니다.
Gradient Descent의 한계
Gradient Descent는 크게 두 가지의 한계가 있습니다.
- Local Minimum 문제
- Saddle Point 문제
Local Minimum
Gradient Descent는 비볼록 함수(Non-Convex function)에서는 최적의 가중치에 도달하지 못할 수 있습니다.
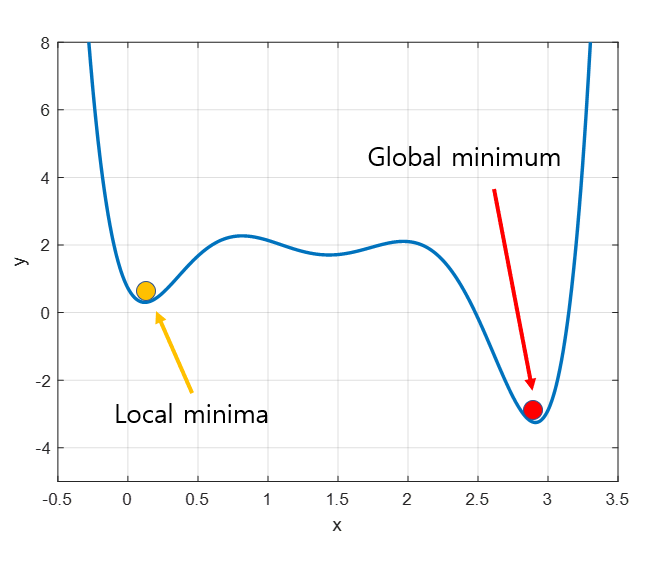
[그림 4] 출처: https://angeloyeo.github.io/2020/08/16/gradient_descent.html
위의 그림에서 볼 수 있듯이 Gradient Descent는 Local minimum에 빠질 가능성이 있습니다. 앞서 언급한 대로 Gradient Descent는 임의의 위치에서 시작하기 때문에 시작 위치에 따라 최적의 가중치가 달라질 수 있습니다. 그림 4를 기준으로 생각한다면 좌측일 경우에는 Local Minima에 수렴하고, 우측의 경우에는 Global minimum으로 수렴할 것입니다. 이렇듯 Gradient Descent는 Local minima에 빠질 우려가 있습니다.
Saddle Point
다음으로 Gradient Descent의 두 번째 한계점은 Saddle Point(안장점)을 벗어나지 못한다는 것입니다.

[그림 5] 출처: https://heytech.tistory.com/380
위의 그림에서 검은점이 안장점입니다. 안장점은 기울기는 0이지만, 극값은 아닌 지점입니다. 위의 경우 A - B 사이에서 검은점은 최솟값(minimum)이지만, C - D 사이에서는 검은점이 최댓값(maximum)입니다. 따라서 검은점은 기울기는 0이지만 극값이 아니게 됩니다. Gradient Descent는 기울기가 0 이 될 때까지 파라미터를 업데이트 하기에 위와 같은 안장점에 도달한다면 벗어나지 못합니다.
Conclusion
Gradient Descent
미분 개념을 적용하여 Loss function의 minimum을 찾기 위해 반복적으로 Weight와 bias를 업데이트해서 최적화 지점을 찾는 알고리즘한계 :
1. Local Minima
2. Saddle Point
참고 자료
[Deep Learning] 최적화 개념과 경사 하강법(Gradient Descent)
경사감소법(경사하강법)이란?
[ML/DL] 최적화(Optimization), 경사하강법 (Gradient Descent Algorithms)
목적함수와 경사하강법
쉽게 배우는 경사하강 학습법
경사하강법(gradient descent)
Understanding Gradient Descent and Adam Optimization
Gradient Descent Algorithm and Its Variants
Setting the learning rate of your neural network.
