
Lecture 1 | Introduction to Convolutional Neural Networks for Visual Recognition
CS231n은 스탠포드 대학교에서 제공하는 컴퓨터 비전(Computer Vision)에 대한 강의다.
강의와 슬라이드를 토대로 CS231n 강의에 대해서 정리하고자 한다. 사용하는 그림들은 대부분 강의 슬라이드에 있는 자료이다.
- 강의: Video
- 슬라이드: Slides
강의 목표
- Computer Vision의 간단한 역사
- CS231n 개요
Computer Vision의 간단한 역사
컴퓨터 비전의 역사는 1960년대 초반으로 거슬러 올라간다. 여기에서는 컴퓨터 비전의 발전에 있어 역사적으로 굵직한 연구들을 소개하고자 한다.
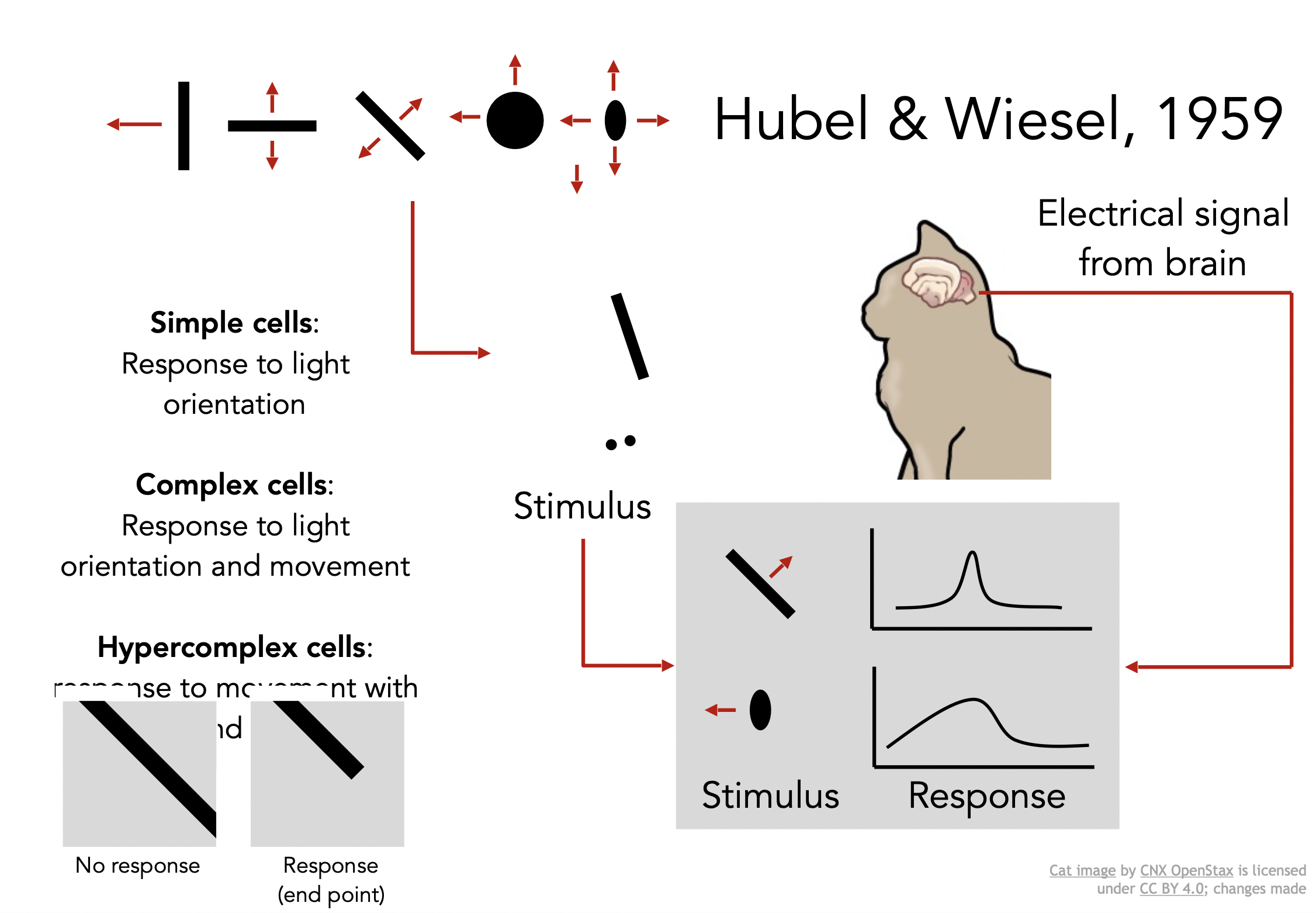
먼저, 인간과 동물의 비전 연구에 가장 영향력 있었던 연구이고 컴퓨터 비전에 큰 영감을 준 연구에 대해서 소개하고자 한다. 1950/60년대 전기생리학을 이용한 Hubel과 Wiesel의 연구이다. 그들은 "포유류의 시각적 처리 매커니즘"을 연구를 하기 위해 고양이의 뇌를 연구했다. 그 결과 고양이의 시각 처리 매커니즘이 인간과 유사하다는 사실을 알게 되었다. 시각 처리를 하기 위해 많은 복잡한 세포들이 있지만 중요한 세포는 경계(edges)가 움직임에 따라 반응하는 세포이다. 이 연구의 주된 발견은 시각 처리가 처음에는 단순한 구조로 시작하고(edges) 점차 실제 세상을 인지할 수 있을 때까지 복잡해진다는 점이다.
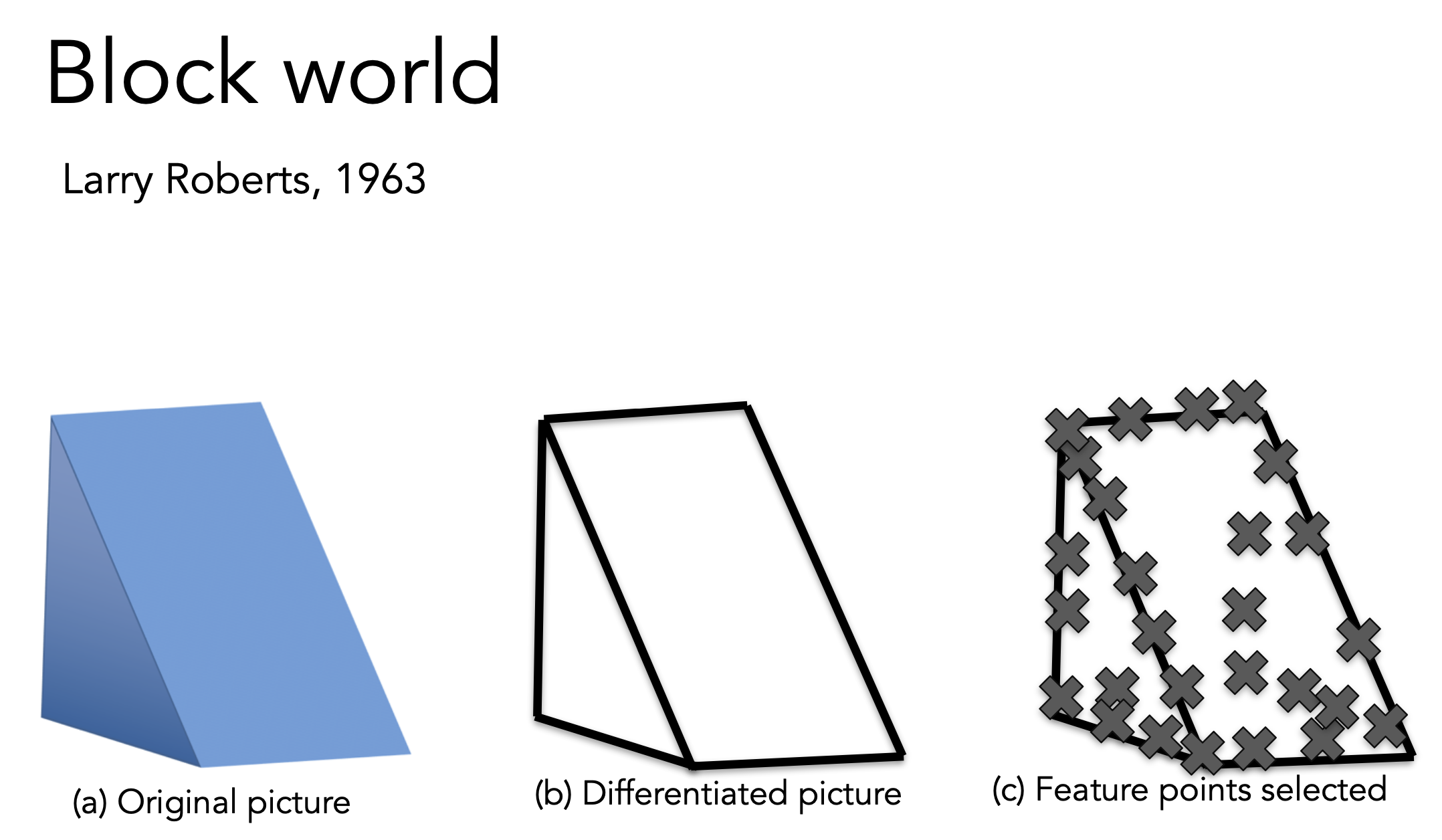
다음으로는 1963년 Larry Roberts의 'Block World'라는 연구이다. 그는 우리 눈에 보이는 세상을 인식하고 모양을 재구성한다는 목표를 가지고 있었다. 이 연구에서는 우리 눈에 보이는 사물들을 기하학적 모양으로 단순화시켰다.
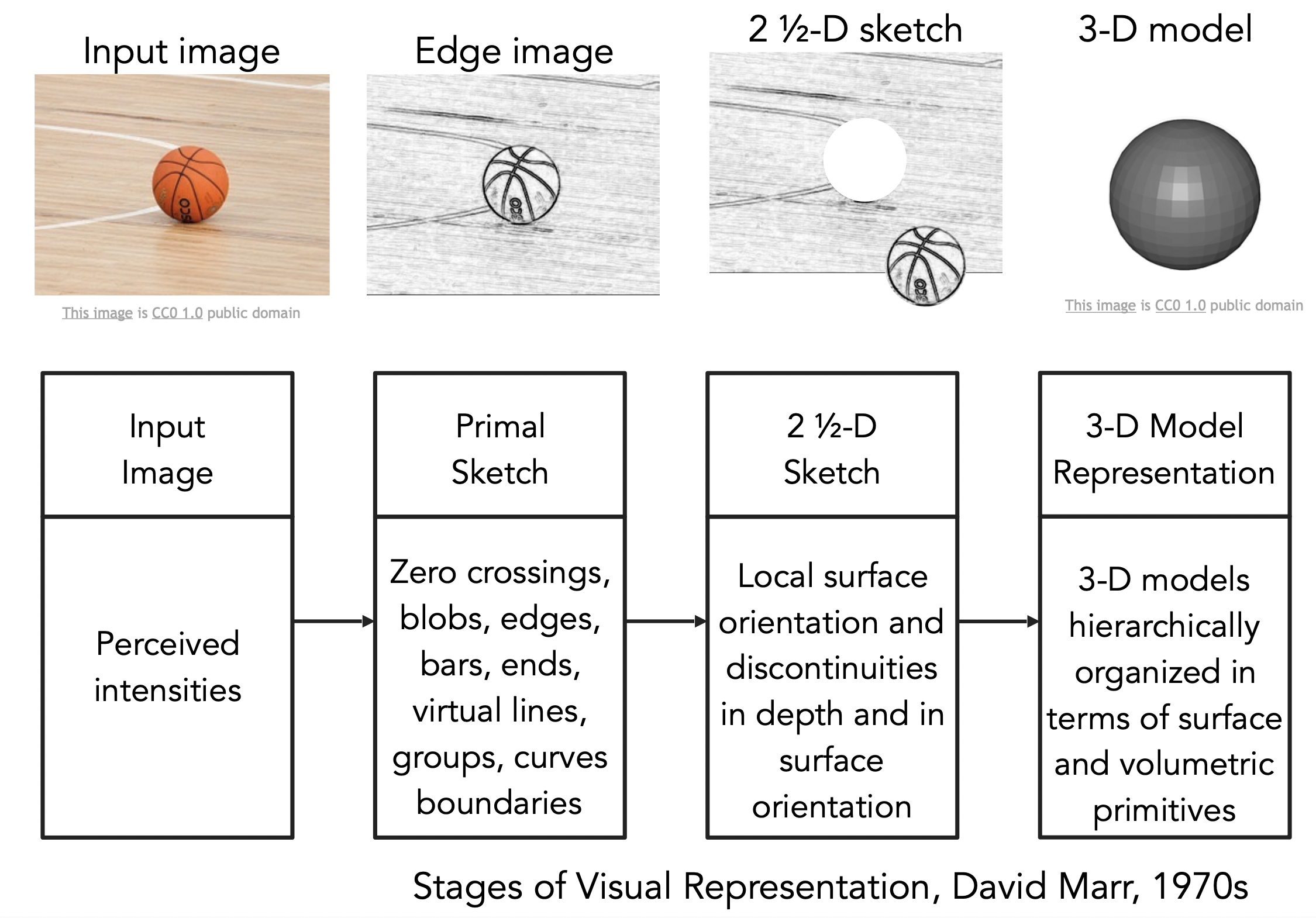
1970년대에 David Marr는 그의 저서 'Vision'에서 컴퓨터 비전이 나아가야 하는 방향에 대해서 다뤘다.
또한 우리가 눈으로 받아들인 이미지를 3D로 표현하기 위해서는 위의 그림에서 보이는 것과 같은 단계를 거쳐야 한다고 주장했다.
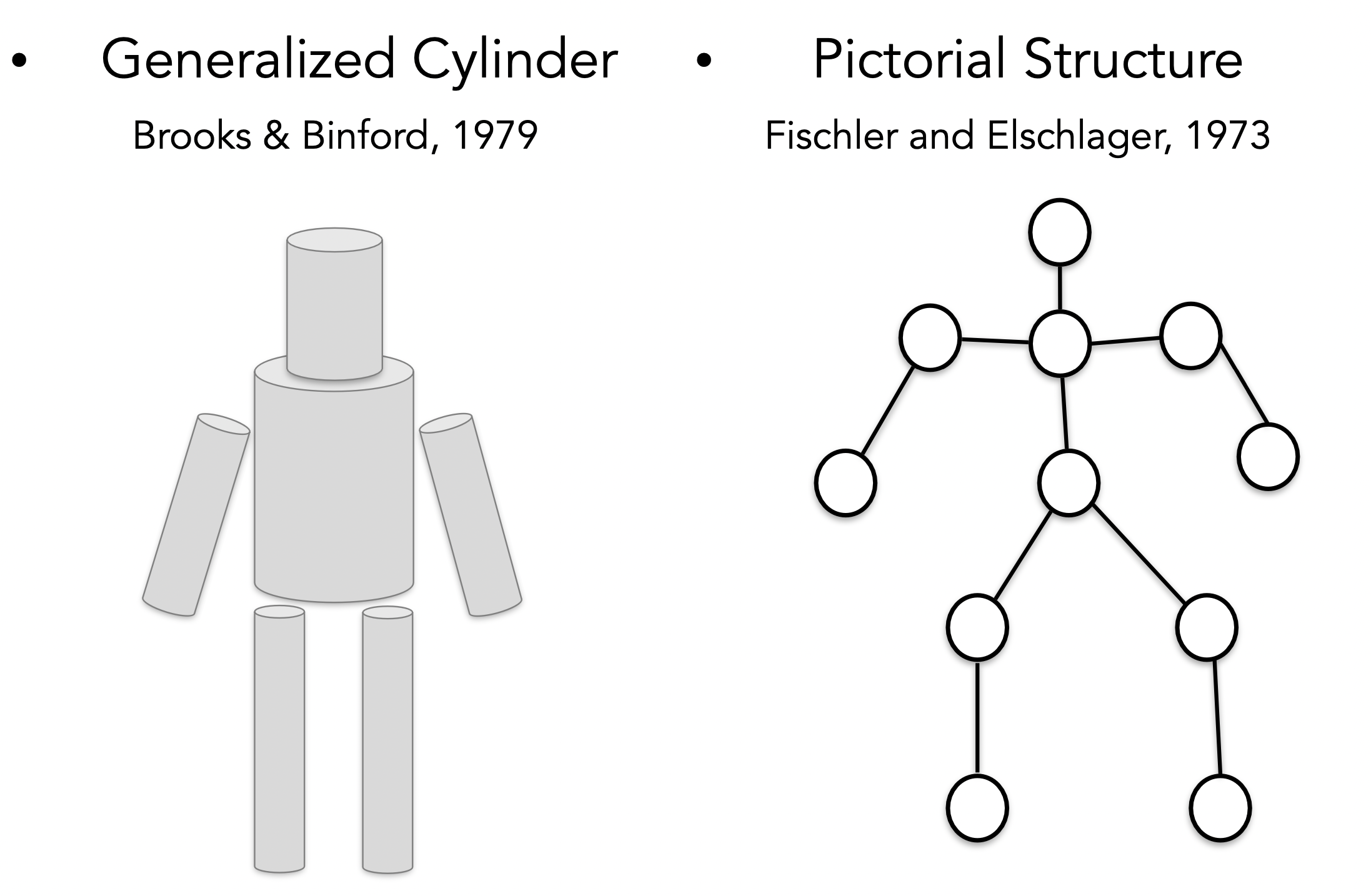
위의 사진에서 보는 연구도 70년대의 중요한 연구이다. "모든 객체는 단순한 기하학적 형태로 표현할 수 있다."라는 기본 개념을 가지고 왼쪽은 사람을 원통 모양을 조합해서, 오른쪽은 '주요 부위'와 '관절'로 표현했다. 두 방법 모두 단순한 모양과 기하학적인 구성을 이용해서 복잡한 객체를 단순화시켰다.

객체 분할은 이미지의 각 픽셀을 의미 있는 방향으로 군집화하는 방법이다. 픽셀을 군집화 하더라도 사람이 정확히 인식하지 못할 수도 있지만, 적어도 배경인 픽셀과 사람이 속해 있을지도 모르는 픽셀을 가려낼 수는 있었다. 이를 “영상 분할(Image Segmentation)”이라고 한다.
이 문제를 다룬 중요한 연구가 있었는데 Berkeley 대학의 Jitendra Malik 교수와 그의 제자인 Jianbo Shi의 연구였다. 이 연구는 영상 분할 문제를 해결하기 위해 그래프 이론을 도입했다.

이후 90년대 후반부터 2010년도까지 "특징기반 객체인식 알고리즘"이 시대를 풍미했다. 가장 유명한 알고리즘은 David Lowe의 SIFT feature이다.
카메라의 각도나 빛에 따라 객체의 모양이 변할 수 있지만 위의 그림처럼 변화에 강인하고 불변한 객체의 특징을 발견해서 다른 객체에 매칭시키는 것이 SIFT feature의 main idea이다.
이후 Spatial Pyramid Matching, HOG algorithm 등의 여러 논문이 Computer Vision 분야에 큰 영향을 끼쳤다.
2000년대 초 컴퓨터 비전이 앞으로 풀어야 할 문제에 대해서 정의했다. 해결해야 할 다양한 문제들이 있지만 그 중에서도 집중한 것은 "객체인식"이었다.
Graphical Model, SVM, AdaBoost 같은 머신러닝 알고리즘들이 Training 과정에서 Overfit이 발생했다. 원인은 두 가지였다.
- 시각 데이터가 너무 복잡하다.
- 학습 데이터가 부족하다.
따라서 이를 극복하고 나아가고자 하는 두 가지 motivation이 있었다.
- 세상의 모든 것들을 인식한다.
- 기계학습의 Overfitting을 줄인다.
이러한 동기를 바탕으로 ImageNet 프로젝트가 시작됐다.

ImageNet은 약 15만 장의 이미지와 22만 가지의 카테고리를 가진 방대한 데이터셋이다.
이렇게 방대한 ImageNet 데이터셋으로 ILSVRC(ImageNet Large Scale Visual Recognition Test)라는 Image Classification Challenge를 개최한다. ILSVRC의 목적은 이미지 분류 문제를 푸는 알고리즘들을 테스트하기 위함이었다.

위의 그래프의 x축은 연도, y축은 오류율이다. 시간이 지남에 따라서 오류율이 점차 감소하고 있는 것을 확인할 수 있다. 2015의 오류율(3.57)은 사람(5.1)보다 낮은 것을 알 수 있다.
우리가 주목해야 하는 시점은 2012년이다. 오류율이 전년도(2011년)에 비해 약 10% 감소했다. 그 이유는 2012년 우승 모델인 AlexNet에 있는데, 이는 Convolutional Neural Network를 사용했다. 그 당시 CNN은 다른 알고리즘들을 능가했고 ImageNet Challenge에서 우승했다. 이후 우승한 알고리즘들은 CNN을 기반으로 하여 더 깊은 모델을 만들어 오류율을 줄여나갔다.
CS231n 개요
CS231n
- CNN이 무엇인지
- 어떤 법칙이 있는지
- 어떤 선례가 있는지
- 최근 동향은 어떠한지
나머지 CS231n 강의에서는 위에서 언급한 것들에 대해서 다룰 예정이다.
