index는 어디에 거냐에 따라 select의 성능이 크게 달라진다.
예를 들기 위해 member테이블을 생성하고 약 100만개의 데이터를 집어넣은 상태이다.
현재 테이블 상황
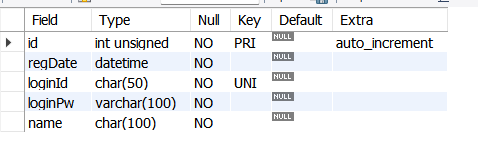
아래는 현재 index 상황이다.
인덱스

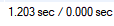
select * from member where name = '유저1';위 와 같은 쿼리를 날릴경우 약 1.2초가 걸리는 것을 확인 할 수 있었다.
쿼리 실행시간 짧아짐
그럼 이번에는 name에 index를 걸고 다시 돌려보면 (이때 index를 생성하기 위해 시간이 걸립니다.)
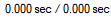
그냥 압도적으로 짧아진것을 볼 수 있다.
🤔그러면 모든 칼럼에 인덱스를 걸면 되는거 아닌가?
인덱스를 관리하기 위해 또 다른 테이블이 있다고 생각하면 되는데 그만큼 공간을 차지한다고 생각하면 됩니다.
그리고 인덱스의 경우 정렬 상태를 유지하기 위해 값이 들어오거나 나갈때 정렬을 수행하게 되는데 값이 많이 변하는 데이터의 경우는 그 비용이 만만치 않습니다.
실제로 인덱스를 이용하여select를 하여도 옵티마이저가 비용을 계산해서 풀스캔하는게 더 좋다고 판단하면 풀스캔을 하기도 합니다.

greenTea입니다.