1. 통계함수
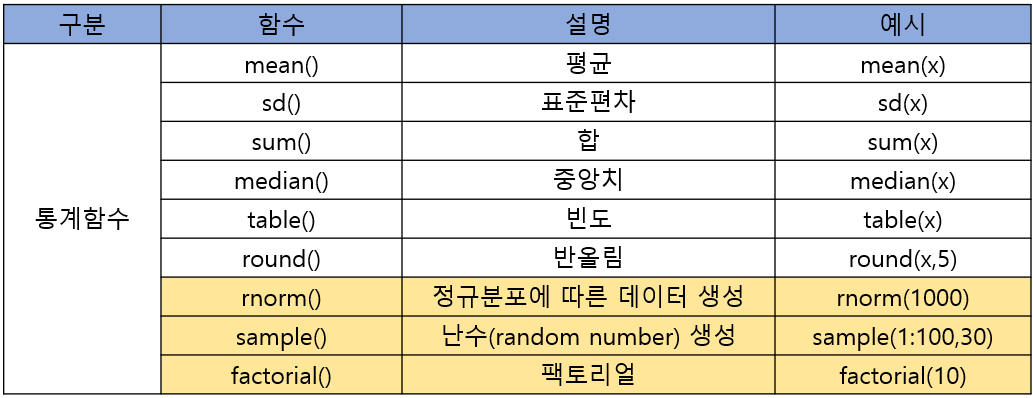
1-1. rnorm() 난수함수
- 난수함수는 정규분포함수의 변수에 해당하는 값을 임의로 생성해 주는 함수이다.
- 디폴트(기본셋팅)는 '표준정규분포'이고 평균과 표준편차를 설정해줄 수 있다.
- 값을 임의로 5개 생성
rnorm(5) [1] -0.0061575 1.1271573 0.9708612 0.6268076 0.7936966
- 평균을 100, 표준편차를 5로 바꿔서 생성
rnorm(5,mean=100,sd=5) [1] 95.388 96.722 100.674 95.939 96.589
1-2. sample() 함수
- 벡터(vector) 혹은 데이터 프레임(data frame)에서 지정된 크기만큼의 데이터를 랜덤으로 추출할 때 사용하는 함수이다.
✔︎ 비복원 추출 -> replace = FALSE (replace = F)
- 데이터를 중복되지 않게 랜덤으로 추출할 때
- 1부터 100사이 값에서 무작위로 30개 추출
sample(1:100,30) [1] 71 12 15 81 6 40 2 37 76 64 16 67 13 54 98 62 77 95 100 10 78 5 [23] 72 32 41 56 48 49 91 11
- 1부터 10사이 값에서 무작위로 20개를 복원(중복가능) 추출
sample(1:10,20,replace = T) [1] 3 9 3 4 7 2 1 9 10 5 8 4 10 7 9 6 6 4 7 10
1-3. factorial() 팩토리얼
- 팩토리얼은 1부터 n까지의 정수를 곱하는 연산입니다.
- 1부터 100까지의 정수 곱하기 (=100!)
factorial(10) [1] 3628800
- 1! 부터 5!까지를 원소로 갖는 벡터를 생성할 수도 있다.
factorial(1:5) [1] 1 2 6 24 120
2. 수학함수
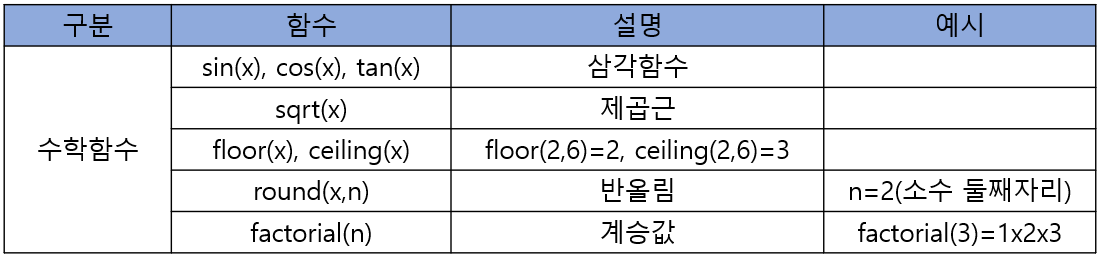
2-1. round(x,n)
- 소수점 자리를 반올림 하여 결과를 정수만 나타내고 싶을 때 아무런 추가 명령없이 round(x)만 입력해주면 된다.
round(31) [1] 30round(31.4) [1] 31round(31.832) [1] 32
- round(숫자, 소수점 자리수)
round(2.12351,3) [1] 2.124
✔︎ 소수점 자리의 반올림
round(2.1235,3) ## 소수점 5가 반올림이 안됨 [1] 2.123round(2.12351,3) ## 소수점 5 뒤에 숫자를 더 있으니 반올림이 됨 [1] 2.124round(2.1236,3) ## 소수점 6이상인 숫자는 뒤에 숫자가 없어도 반올림이 됨 [1] 2.124
2-2. ceiling() 올림
- ceiling(x)는 x보다 큰 수 중에 가장 작은 정수를 나타내주는 함수다.
ceiling(2.234) ##무조건 반올림 [1] 3ceiling(2.235) [1] 3
2-3. floor() 내림
- floor(x)는 x보다 작은 수 중에 가장 큰 정수를 나타내주는 함수다.
floor(3.789) ##무조건 내림 [1] 3floor(3.234) [1] 3
3. 행렬함수

3-1. colMeans()
- 행렬에서 열 별로 평균을 구하는 함수
- 행렬 정의
m=matrix(1:12,3) m [,1] [,2] [,3] [,4] [1,] 1 4 7 10 [2,] 2 5 8 11 [3,] 3 6 9 12✔︎ colMeans 함수를 이용하여 열별로 평균을 구하기
colMeans(m) [1] 2 5 8 11
3-2. colSums()
- 행렬에서 열 별로 합을 구하는 함수
- 행렬 정의
m=matrix(1:12,3) m [,1] [,2] [,3] [,4] [1,] 1 4 7 10 [2,] 2 5 8 11 [3,] 3 6 9 12✔︎ colSums 함수를 이용하여 열 별로 합을 구하기
colSums(m) [1] 6 15 24 33
✔︎ colSums 함수를 이용하여 column(변수)별 사례수 구하기
colSums(!is.na(x))
-is.na(x): 변수에 NA가 있는지 확인colSums(is.na(m)) ## 변수에 NA의 개수의 합 [1] 0 0 0 0 ## NA가 없어서 0이 나옴colSums(!is.na(m)) ## 변수에 NA가 없는(!) 개수의 합 [1] 3 3 3 3 ## NA가 없으니 개수의 합이 3 나옴
3-3. apply()
- 행(Row) 또는 열(Column) 단위의 연산을 쉽게 할 수 있도록 지원하는 함수이다.
- 1이 행 단위 연산이고 2가 열 단위 연산이다.
library(openxlsx) df = read.xlsx("regress.xlsx") df✔︎ 행(row) 단위로 mean 연산
apply(df, 1, mean)✔︎ 열(column) 단위로 mean 연산
apply(df, 2, mean) 근무만족도 대인관계 자아개념 근무평정 SES점수 63.400 48.533 54.333 76.267 57.133✔︎ 열(column) 단위로 표준편차(sd) 연산
apply(df, 2, sd) 근무만족도 대인관계 자아개념 근무평정 SES점수 18.548 20.134 22.166 12.086 15.167
3-4. cbind(), rbind()
- cbind()열끼리, rbind()행끼리 묶기
x <- c(1, 2, 3, 4, 5) y <- c(6, 7, 8, 9, 10)✔︎ rbind() - 행으로 합치기
rbind(x, y) # x와 y를 행으로 합침 [,1] [,2] [,3] [,4] [,5] x 1 2 3 4 5 y 6 7 8 9 10✔︎ cbind() - 열로 합치기
cbind(x, y) # x와 y를 열로 합침 x y [1,] 1 6 [2,] 2 7 [3,] 3 8 [4,] 4 9 [5,] 5 10
