무려 2개의 포스팅 동안 random forest에 대해 소개를 못했는데요, random forest는 ensemble(앙상블)에 속하는 머신 러닝 모델이면서 decision tree에 대한 지식이 있어야 하기에 이제서야 소개를 해드리게 되었습니다.
Random Forest
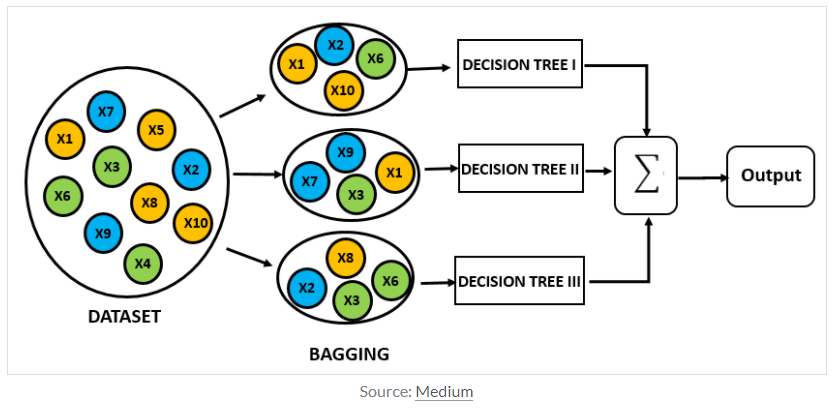
Random forest는 ensemble(앙상블)에 속합니다. 여러개의 decision tree를 형성하고 새로운 데이터 포인트를 각 트리에 동시에 통과시키며, 각 트리가 분류한 결과에서 투표를 실시하여 가장 많이 득표한 결과를 최종 분류 결과로 선택합니다.
기존 decision tree는 overfitting될 가능성이 높습니다. 그렇기에 random forest 과정에서 생성된 decision tree들 중 overfitting된 tree가 분명 존재할 것입니다. 그러나 그만큼 많은 수의 트리를 생성하기에 overfitting이 결과 큰 영향은 못 끼치도록 예방한답니다.
random forest의 생성은 데이터의 중복조합(chosen random with replacement)에 의해 선택되고 이 과정은 bagging에 속합니다.
또 random forest는 데이터셋뿐만이 아니라 feature 또한 random하게 선택해서 tree를 만듭니다. m개의 feature가 존재할 때, 보통 root m개 만큼 선택을하고 그 중에서도 information gain이 가장 높은 feature를 선택하여 데이터를 분류합니다. 이 과정을 트리가 만들어질 때까지 반복합니다.
tree를 만든 이후 classify 과정을 통해 random tree에서 출력한 값을 test 단계에서 정답과 비교하며 accuracy를 측정하게 됩니다.
출처
