
< seq2seq with attention 모델 및 이를 통한 자연어 이해 및 생성 >
1. RNN
: Recurrent Neural Networks
-> sequence data 에 특화된 neural network, 재귀호출하는 알고리즘
-> 전단계의 출력 결과와 현재 단계의 새로운 입력값에 각각 fully connected layer를 거치고 합산해서 sequence를 유지한다.
마지막 단계에서 선형 변환을 통해 벡터로 만들어 softmax layer를 거쳐 확률분포로 만들거나, 회귀에 이용한다면 오차를 계산한다.
2. RNN-based sequence modeling
(1) one to one
: 일반적인 경우
(2) one to many
: for Image Captioning (image -> sequence of words)
Input : 최초1회 이미지 1장 (1)
Output : 단어의 sequence (문장, many)
-> 이때는 전단계의 출력 결과만을 이용하고 현재 단계에서는 새로운 입력값을 0으로 세팅한다.
(3) many to one
: for sentiment classification (문장 분류. Sequence of words -> sentiment)
Input : 문장 (ex. I love this movie를 1 time step에서는 I, 2 time step에서는 love 이런 식으로 순차적으로 입력한다)
Output : 마지막에 (입력이 다 들어오고 난 다음) hidden state vector를 최종적인 output layer의 입력으로 넣어 판단 수행
(4) many to many
: for machine translation (번역기. Sequence of words -> sequence of words)
Input : 문장
Output : 문장
-> Input에서 문장의 각 단어별로 하나씩 차례로 입력이 들어오고, 입력이 전부 들어오고 난 시점으로부터 다시 한 단계씩 output문장 구성 요소를 하나씩 출력하게 된다.
(5) many to many를 실시간으로 수행하는 방법
-> 입력이 다 들어오지 않아도 들어온대로 바로 판단을 수행해서 출력하는 (4)의 변형 버전. delay를 허용하지 않는다. Realtime!
3. Character-level Language model
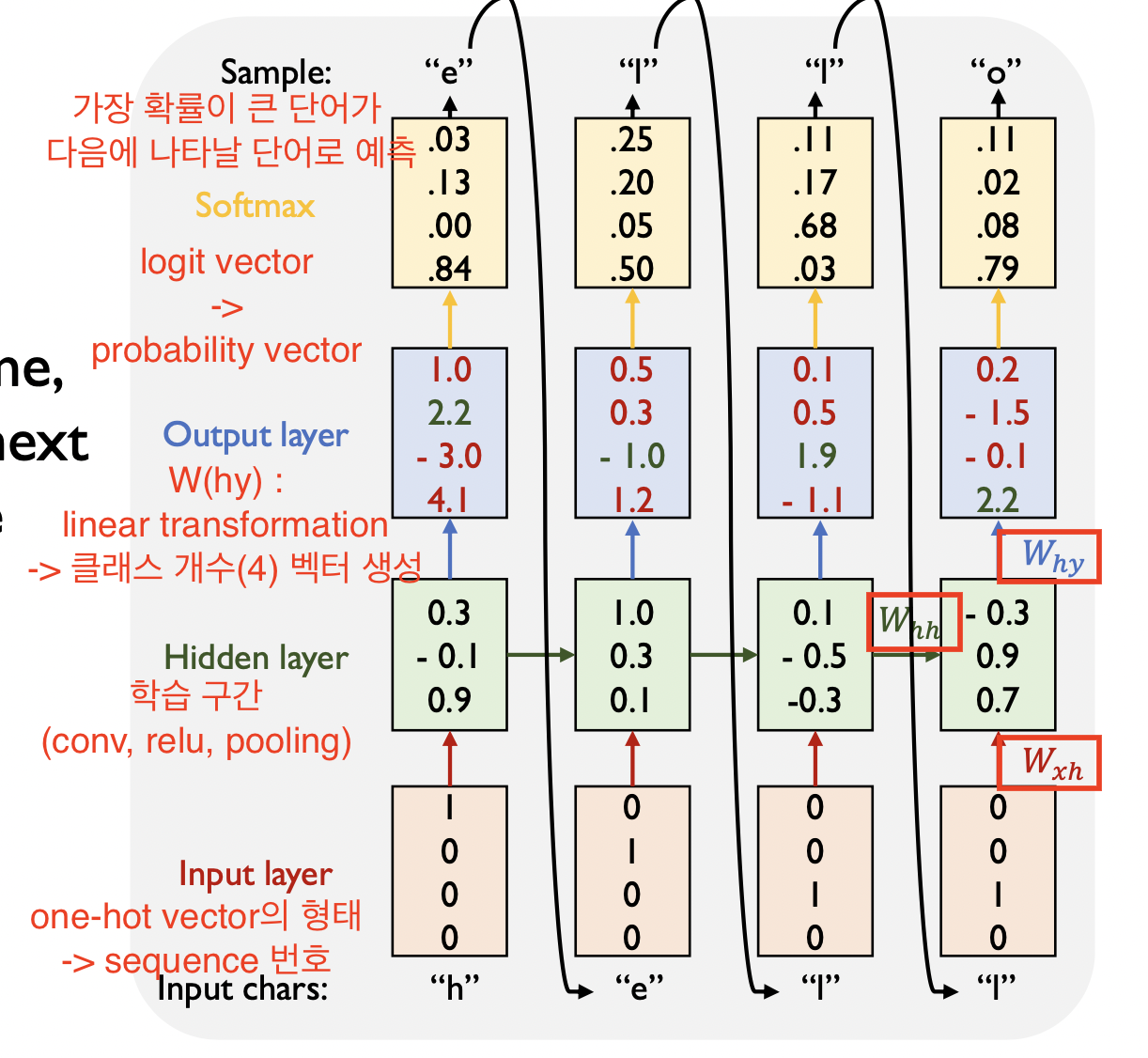
h, e, l, o 로 이루어진 단어 “hello”를 예측할 수 있도록 학습하는 과정을 살펴보자.
-> h, e, l, o 4개의 클래스 중 다음에 올 단어가 뭔지를 예측해야 하므로 multi-class classification 문제이다.
input layer (입력 순서, 즉 시퀀스 번호를 나타내는 one-hot vector) -> hidden layer -> output layer -> softmax layer
-> W(hy, hh, xh)가 파라미터로써 gradient descent를 통해 학습이 진행된다.
-> 우리는 hello라는 단어를 알고 있기 때문에 h뒤에 e가 온다는 ground truth class에 대한 정보를 가지고 있다. 그래서 학습을 반복하는 과정에서 softmax loss를 적용해 오차를 줄여나가는 방법으로 학습을 진행한다.
-> 학습이 완료되면 연쇄적인 데이터 모델이므로 h만 입력으로 들어와도 hello가 출력이 되도록 만들 수 있다.
(Auto regressive model : 이전 time step에서 예측한 결과가 다음 time step에 입력으로 주어지는 방식의 예측 모델)
4. LSTM
-> 그냥 일반적인 vanilla language model을 사용하게 되면 gradient vanishing/exploding 문제와 같이 학습이 안정적이지 않게 진행될 수 있다는 단점이 있다. 그래서 RNN의 보강된 버전인 LSTM이나 GRU와 같은 방법을 사용한다.
-> 일반적인 경우와 다 동일하고, hidden layer에서 추가적인 연산 과정을 통해 두가지 버전의 벡터를 만들고 다음 step으로 넘긴다.
5. Seq2seq
-> many to many에 해당.
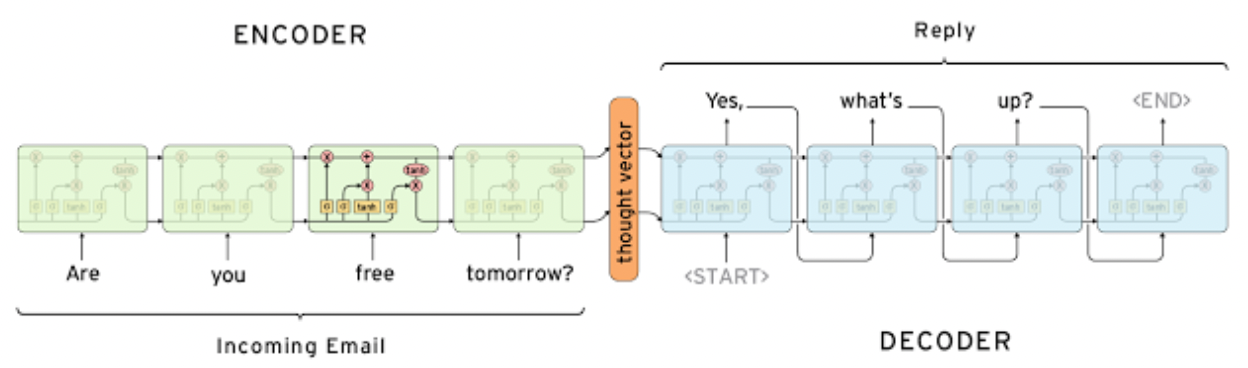
인코더와 디코더에 해당하는 부분은 파라미터를 공유하지 않는다.
인코더 부분에서 하나하나의 단어마다 레이어들을 거치게 되고, 각각은 같은 차원(dimension)을 가져야 한다.
문장 길이가 길어질수록, 같은 차원에다가 데이터들을 축적시켜야 하기 때문에 병목 현상이 일어날 수 있다는 단점이 있다.
-> 정보가 유실되어 output sequence가 잘 생성되지 않을 수 있다.
6. Seq2seq with attention
-> seq2seq 오리지널 모델은 인코더의 마지막 부분에서 도출되는 하나의 벡터만이 디코더의 input이 된다.
그러나 attention기법은 인코딩하는 과정의 각 단계마다 도출되는 값들 중에서 선택적으로 디코더에 사용이 된다.
-> 우선은 기본적인 동작 방식은 같다. Seq2seq 인코더의 마지막 벡터를 디코더의 입력으로 주는데, 이때 추가적인 자료로 인코더의 각 단계마다 도출된 값을 사용한다. Softmax 함수를 통과시켜 유사도를 측정하고 가장 유사도가 높은 데이터를 선택적으로 사용한다.
-> 방식은 기존이랑 똑같은데 어텐션 모듈이 하나 더 추가됐다는 차이점임.
장점으로는 1. 병목현상 제거
2. Gradient vanishing 해결
3. Back propagation시 gradient를 바로잡아야 하는 곳을 조금 더 효율적으로 빠르게 찾아갈 수 있다
등이 있다. -> 자연어 처리 문제 중 가장 대표적인 seq2seq에서 큰 발전을 주었다.
