검색기능
검색을 만들어보자
순서를 정하자면
1. 검색 UI를 하나 만들고 검색어를 입력한 걸 서버로 전송
2. 서버는 검색어가 포함된 제목을 가진 게시물을 DB에서 찾기
3. 해당 데이터를 ejs 파일에 넣어서 유저에게 보내주기
UI 만들기
list.ejs
<input class="search"/>
<button class="search-send">검색</button>
<script>
document.querySelector('.search-send').addEventListener('click', ()=>{
let inputVal = document.querySelector('.search').value
location.href = '/search?val=' + inputVal
})
</script>우선 검색 UI를 만들었고, 버튼을 클릭 시 input 값의 데이터를 쿼리스트링 url로 get 요청을 해달라고 했다.
서버에서 검색어가 포함된 게시물 찾아오기
서버에서 누가 /search로 GET 요청을 하면 검색어가 들어있는 제목을 찾아오면 된다고 위에서 정리를 했다.
app.get('/search', async (req, resp) => {
let result = await db.collection('post').find( {title : req.query.val} ).toArray()
}).find(조건).toArray()를 하면 조건에 맞는 document를 다 가져오게 된다.
하지만 여기서 문제가 있다.
정확한 제목을 입력해야한다.
예를 들어, "첫번째 글" 이라는 제목을 가진 게시물을 찾으려면 "첫번", "첫번째" 이렇게만 쳐도 나왔으면 좋겠으나, find는 정확히 일치하는 걸 가져오기 "첫번째 글" 이렇게 전부 다 검색어에 입력을 해야한다.
그러면 정규식을 쓰면 되지않는가?
app.get('/search', async (req, resp) => {
let result = await db.collection('post').find( {title : {$regex : req.query.val} } ).toArray()
})regex를 통해서 정규식을 쓰면 정확히 일치하지 않아도 해당 게시물을 가져올 수 있다.
하지만 매우 느리다는 것이 단점이다.
document가 많을 수록 그 document를 하나하나 살펴보는 시간이 오래 걸리기에 느리다고 볼 수 있다.
그렇다면 더 빠르게 찾을 수 있는 방법 index를 써보자
index
1 ~ 100 까지의 카드가 존재할 때, 한 숫자를 빠르게 찾아내려면
카드를 정렬해서 숫자의 반을 잘라가면서 원하는 특정 숫자를 찾아낼 수 있다.
이렇게 반으로 잘라내면서 찾는 것을 binary search라고 한다.
binary search는 미리 정렬이 되어있어야 하고, 정렬된 컬렉션 복사본을 index라고 한다.
몽고디비에서 index를 만들어보자!
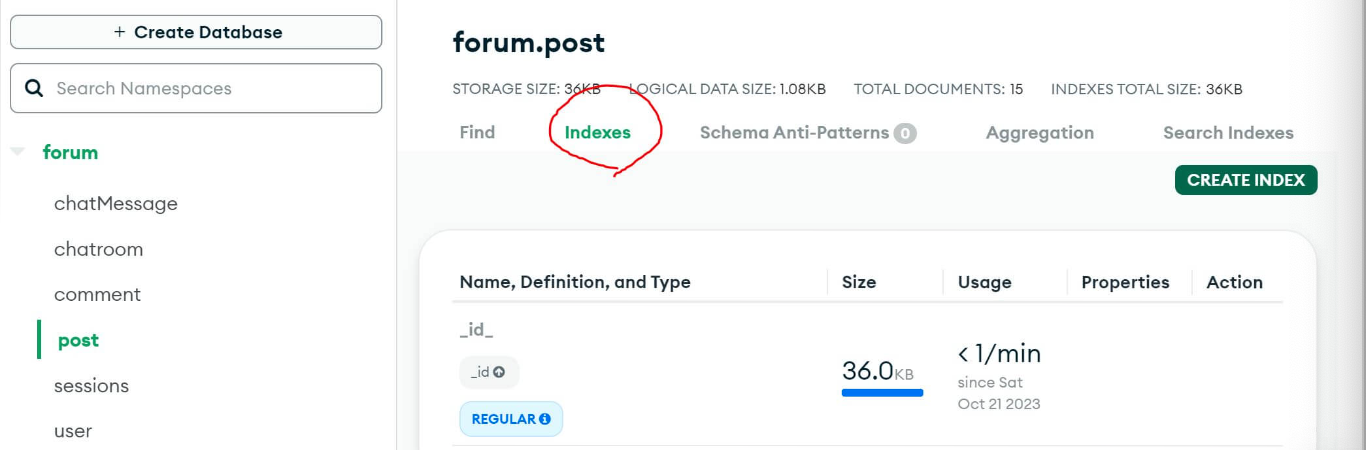
- 원하는 컬렉션에서 indexes를 누르고 create 해주기

- index 만들 필드명 : 데이터 타입 기재
문자인 경우 "text", 숫자는 1
방금 만든 index를 사용해서 검색하려면 문법이 좀 달라져야한다.
db.collection().find( { $text : { $search: req.query.val } } ).toArray()원래는 find({title : req.query.val}) 이렇게 찾았는데 $text 연산자를 이용해서 index를 활용해서 빠르게 찾아왔다.
index 단점
- index는 컬렉션을 통째로 복사해서 정렬해두는 거라 용량을 그만큼 더 많이 차지한다.
그래서 꼭 검색작업이 있는 필드만 index를 만들어두는 것이 비용적으로 이득이다.
-
document 추가/수정/삭제를 할때 index도 똑같이 수정해줘야하기에, 꼭 필요한 필드만 index를 만들어두는 것이 좋다.
-
index를 만들면 빠르긴 하지만.. 또 정확한 단어를 입력해야한다.
인덱스를 만들 때는 띄어쓰기로 단어를 구분하기에 "하이" 라고 검색하면 "하이" 게시물은 정확하게 검색하지만
"하이요", "하이하세요", "하이윙" 은 검색할 수 없다.
그래서 한국어 같이 조사가 많이 붙는 경우 text index가 소용이 없다.
그래서 마지막으로 search index라고 불리는 것을 만들어보자.
search index(full text index)
- search index는 index를 만들 때 document에 있는 문장들을 가져와서 조사나 불용어들을 제거 한다.
- 그래서 모든 단어들을 뽑아서 정렬하고
- 어떤 document에 등장했는지 id를 적어둔다.
- 특정 단어를 검색했을 때 index에서 해당 단어를 찾아서 그 아이디가 속한 id를 통해 빠르게 document를 찾아올 수 있다.
search index 만들기

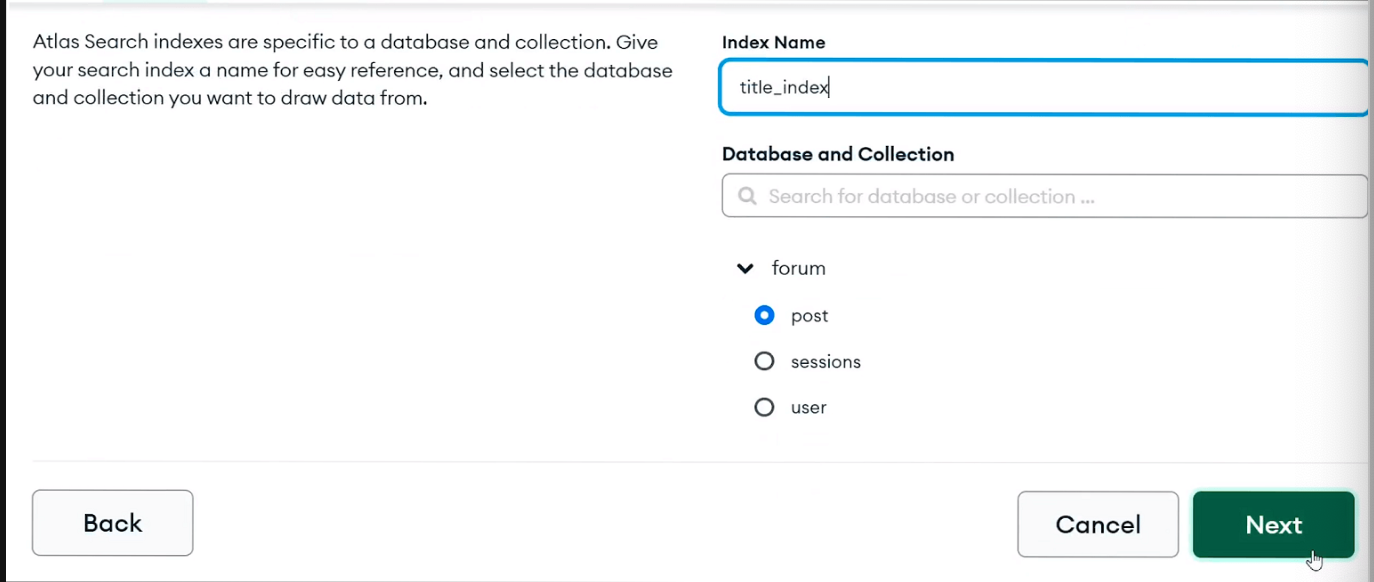
index name을 써주고 어떤 컬렉션에서 index를 만들지 선택해준다.
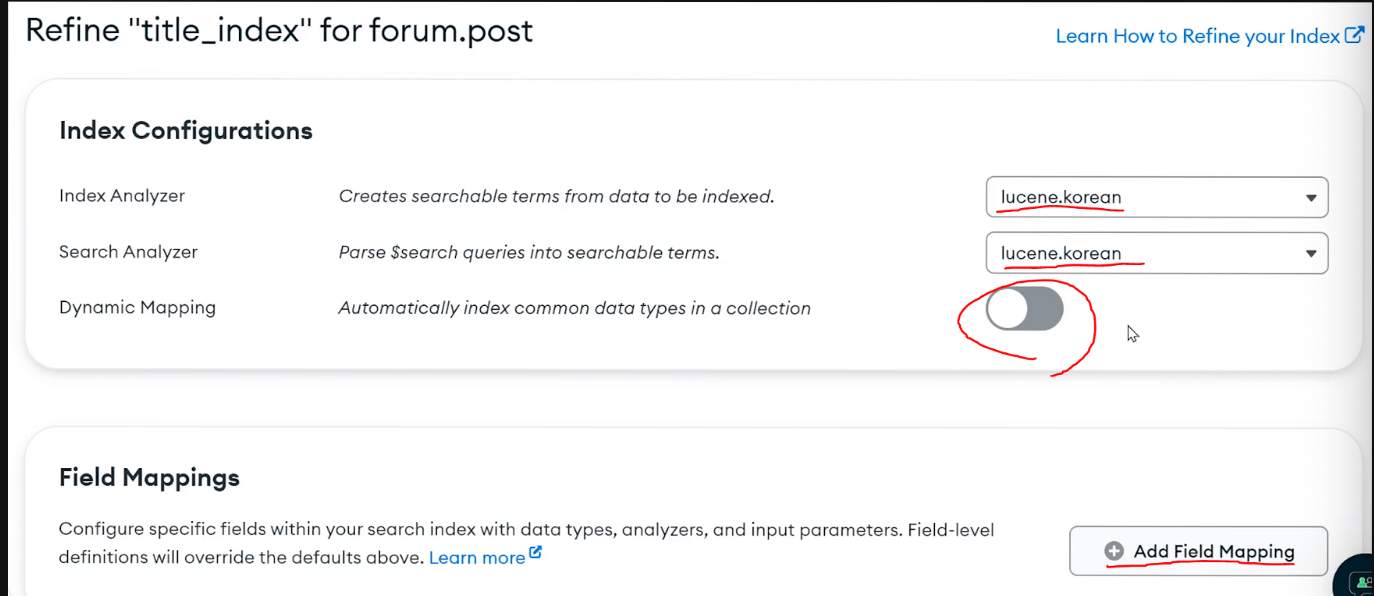
index를 커스터마이징 해주는 부분에서 lucene.korean을 선택해주고 dynamic mapping을 꺼준다.
그리고 필드 매핑을 만들어주자
dunamic mapping은 해당 document에 있는 모든 필드들을 인덱싱할 것인지 선택하는 것이다.
필드를 직접 설정하기에 해당 기능을 껏다.
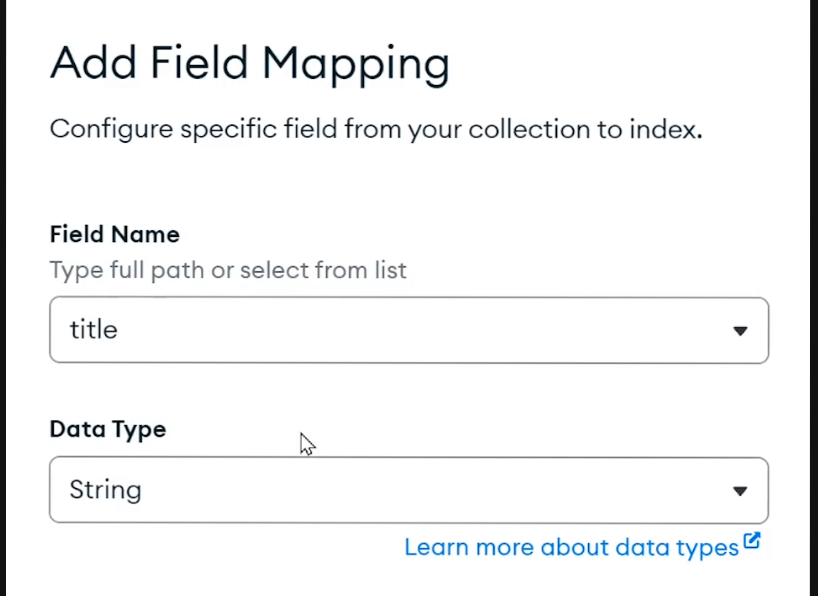
필드 매핑에서 어떤 필드에 index를 만들것인지 설정하고 나 같은 경우에 title을 선택했다.
그렇다면 index 생성 끝!
search index 사용
server.js
app.get('/search', async (req, resp) =>{
let condtion = [
{$search : {
index : 'title_index', // 내가 사용할 인덱스 이름
text : { query : req.query.val /* 검색어 */ , path : 'title' /* 검색할 필드 이름 */ }
}},
{ $sort : { _id : 1 } }, // 정렬
{ $limit : 10 }, // 갯수
{ $project : { title : 1, _id : 0 } } // 0을 기입하면 필드를 숨기고 1을 기입하면 필드를 보여줌
]
let result = await db.collection('post').aggregate(condtion).toArray()
console.log(result)
resp.render('search.ejs', {posts : result})
})우선 $search 연산자를 통해서 search index를 이용해서 검색해오도록 했다.
find()가 아닌 aggregate()로 수정이된다.
aggregate()는 검색조건을 여러개 집어 넣을 수 있다.
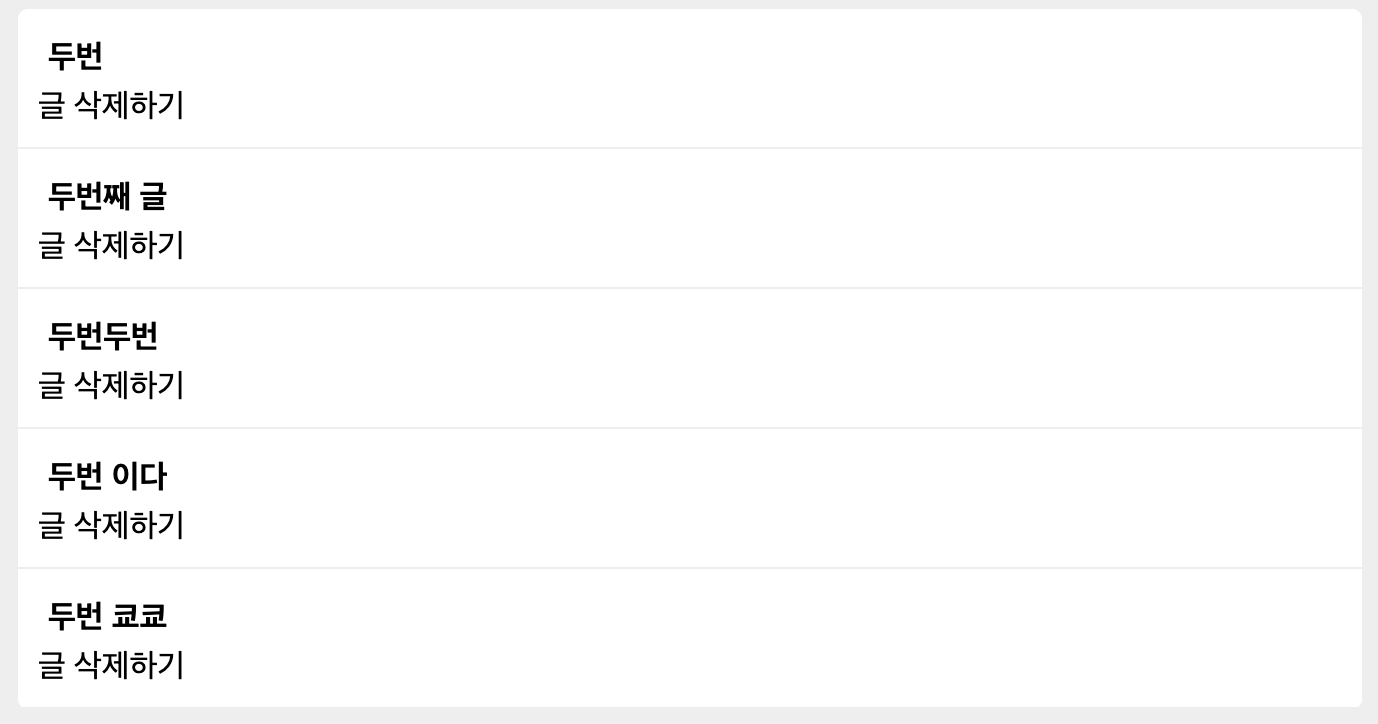
"두번"이라는 검색어를 넣어서 검색을 했을 때, 해당 검색 결과가 나오게 된다.