
1. 다중공산성 해결
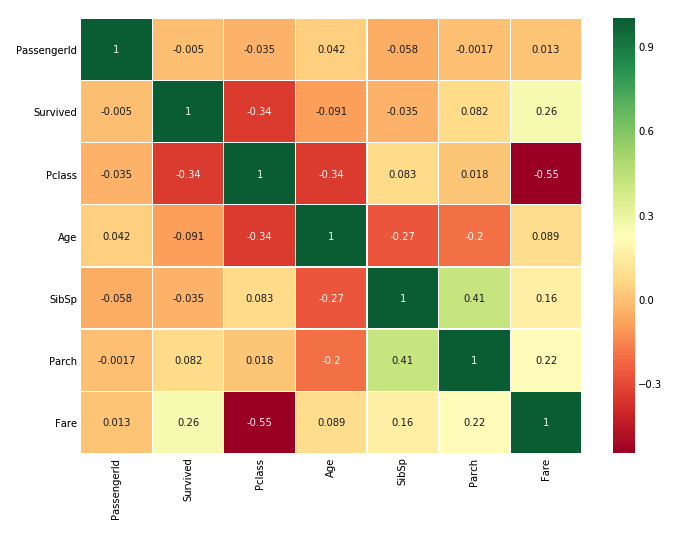
- 머신러닝에서 feature 간의 상관관계가 높은 것을 다중공산성이라 부른다. 이 경우 두 변수는 같은 정보를 담고 있다고 볼 수 있다. 다중공산성이 확인되면 중복되는 데이터를 제거하는 것이 좋다.
2. 연속형 변수 -> 범주형 변수 or 순서형 변수
data['Age_band']=0
data.loc[data['Age']<=16,'Age_band']=0
data.loc[(data['Age']>16)&(data['Age']<=32),'Age_band']=1
data.loc[(data['Age']>32)&(data['Age']<=48),'Age_band']=2
data.loc[(data['Age']>48)&(data['Age']<=64),'Age_band']=3
data.loc[data['Age']>64,'Age_band']=4
data.head(2)- 나이와 같은 연속형 변수는 머신 러닝의 학습에 불리하다. 만약 30명의 사람이 있는 경우 30개의 연령 값이 있을 수 있다. binning을 하지 않으면 모델은 30개의 관측치를 모두 고려해야 한다(high cardinality).
data['Fare_Range']=pd.qcut(data['Fare'],4)
data.groupby(['Fare_Range'])['Survived'].mean().to_frame().style.background_gradient(cmap='summer_r')- pandas.qcut을 이용해서 연속형 변수를 나누는 방법도 있다. 나누려는 feature와 bin 인자를 입력하면 입력한 인자만큼 관측치를 나눈다.
3. str into int/float
data['Sex'].replace(['male','female'],[0,1],inplace=True)
data['Embarked'].replace(['S','C','Q'],[0,1,2],inplace=True)
data['Initial'].replace(['Mr','Mrs','Miss','Master','Other'],[0,1,2,3,4],inplace=True)- 원핫인코딩으로 object feature를 전환하면 feature가 늘어나서 모델의 복잡도가 올라간다. 원핫인코딩을 적용하기 전에 object tpye을 int/float로 바꿔준다.
4. 새로운 정보를 담는 feature 생성
data['Family_Size']=0
data['Family_Size']=data['Parch']+data['SibSp']#family size
data['Alone']=0
data.loc[data.Family_Size==0,'Alone']=1#Alone
f,ax=plt.subplots(1,2,figsize=(18,6))
sns.factorplot('Family_Size','Survived',data=data,ax=ax[0])
ax[0].set_title('Family_Size vs Survived')
sns.factorplot('Alone','Survived',data=data,ax=ax[1])
ax[1].set_title('Alone vs Survived')
plt.close(2)
plt.close(3)
plt.show()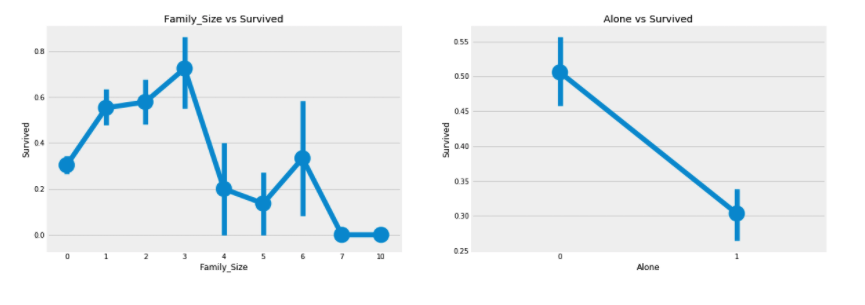
- '자녀의 수'와 '함께 온 부모의 수' feature를 합쳐서 '가족의 수'로 새로운 변수를 생성하고, '0'인 관측치는 Alone 변수로 만든다.

-