
공부 과정을 기록하는 페이지입니다. 다음 원칙을 지켰는지 확인합니다.
1. 레퍼런스에서 어떤 부분을 더 발전시켰는지
2. DA에서 사용하는 언어와 개념을 나의 언어로 설명할 수 있는지
레퍼런스를 더 발전시킨 내용
행렬 분해 추천 서비스 사용
오늘은 추천 서비스를 구현했다. Collaborative Filtering 방법 중 행렬 분해 방식을 사용했다. 행렬 분해 방식 중에서도 truncated SVD는 특이값으로 분해한 행렬 중에서도 상위 N개의 값만 골라내어 그 행렬의 특징을 표현할 수 있도록 하는 기법이다. 데이터의 차원을 모두 사용하지 않고, 일부만 추출하여 사용하기 때문에 차원 수가 많은 데이터에 매우 효과적이다. 또한 데이터의 주된 특징을 추출하기 때문에 희소 문제가 많은 데이터라도 일정 이상의 성능을 보인다.
분석 중인 데이터에 대해 어떤 추천 서비스를 적용하면 좋을지 고민을 많이 했다. 분석할 데이터의 차원이 4000개 이상이고, 대부분 0인 희소 테이블이기 때문에 행렬 분해 추천 서비스를 적용했다.
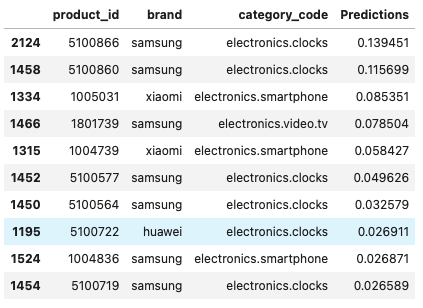
사용자의 아이디를 입력하면 이미 구매한 상품은 제외하고 Prdeiction이 높은 아이템을 출력하도록 함수를 짰다. 여기서 Prediction은 사용자와 구매 패턴이 유사한 사람을 통해 산출된 값이다. A라는 사람과 B라는 사람이 유사한 구매 패턴을 갖고 있을 때, A라는 사람이 물건 a를 아직 구매하지 않았다면 A가 물건 a를 몇 개정도 구매할 것인지 B를 통해 예측한다. 즉, 아직 구매하지 않은 상품에 대해 구매 확률(좀 더 정확히는 예상 구매갯수)을 예측한 값이다.
베이스라인 적용
베이스라인을 어떻게 적용할지가 관건이었다. 위에서 산출된 값이 적정한 값인지 비교할 기준이 필요하기 때문이다. 회귀 문제에서 주로 평균을 베이스라인으로 사용하기 때문에 이 문제에서도 평균을 베이스라인으로 사용하고 싶었는데, 전체 평균 구매 횟수와 SVD의 MSE을 비교할지 아니면 예측값을 평균 구매 횟수로 채워넣은 테이블과 raw 테이블의 MSE를 베이스라인으로 적용할지 고민했다.
SVD의 MSE가 raw 테이블과 예측값 간의 차이를 통해 계산되기 때문에 베이스라인이 되는 MSE도 raw 테이블과 예측값을 평균으로 채운 테이블 간의 차이를 통해 계산하는 게 맞다고 판단했고 하이퍼파라미터를 조정하여 베이스라인 이상의 결과를 산출했다.

정리하자면 위의 테이블을 평균 구매 횟수로 채워서 raw 데이터와의 MSE를 산출한 것을 베이스라인으로 정했고, 위의 테이블을 행렬 분해하여 특이값으로 변환한 뒤 raw 데이터와의 MSE를 산출한 것을 추천 시스템의 성능 지표로 사용했다.
Memory-Out 문제
연산량이 많아지다보니 세션 데드 현상이 계속 나타났다. 일단 전체 row를 줄이는 것부터 시작했다. Cherry Picker로 예상되는 데이터를 제외했고, 한 물건을 5개 이상 구매한 데이터를 제외했다. 같은 전자 제품을 같은 달에 5개 이상 사는 경우는 일반적이지 않다고 판단했기 때문이다. 이렇게 데이터의 raw를 줄이고, SVD 방식의 추천 시스템을 적용하니 Memory-Out 문제가 발생하지 않았다.
