
*해당 포스팅은 <딥 러닝을 이용한 자연어 처리 입문>을 참고하여 정리했습니다. 항상 원문이 더 뛰어납니다.
앞서 RNN 모델에는 기울기 소실의 문제가 있다고 했습니다. 기울기 소실 문제를 해결하기 위해 LSTM, GRU 등 이전 셀의 정보를 보존해주는 방식의 모델이 등장했지만 여전히 하나의 셀에 은닉 상태를 담는 모델이다 보니 시퀀스가 길어질 수록 정확도가 낮아지는 문제가 발생합니다.
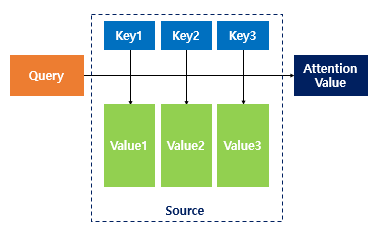
이와 같은 문제를 해결하기 위해 Attention 모델은 Time-step마다 생성되는 은닉 상태 벡터를 활용합니다. Attention 모델은 각각 인코더, 디코더라고 부르는 RNN 두 개로 구성된 모델입니다. 인코더와 디코더는 query, key, value 역할을 하는 벡터를 생성합니다. query, key, value가 무엇을 의미하는지부터 자세히 살펴보도록 하겠습니다.
Attention 모델 연산 과정
Attention 함수는 디코더의 임베딩 벡터를 Query로 하여 인코딩에서 넘어온 은닉 상태 벡터(key)와 유사도를 각각 구합니다. 그리고 이 유사도를 키와 짝을 이루는 value와 더해서 리턴합니다. 예를 들어보겠습니다.
I am a student
위 문장을 한국어로 번역하면 '나는 학생입니다' 입니다. 두 문장이 짝을 이루는 학습 데이터를 Attention 모델에 넣으면 다음과 같은 과정으로 처리됩니다. 영어가 출발어, 한국어가 도착어입니다.
- 위와 같은 시퀀스가 있을 때 인코더에서는 각 단어 토큰에 대해 Time-step 별로 Hidden-state 벡터를 리턴합니다. 이 벡터는 쿼리로 사용됩니다.
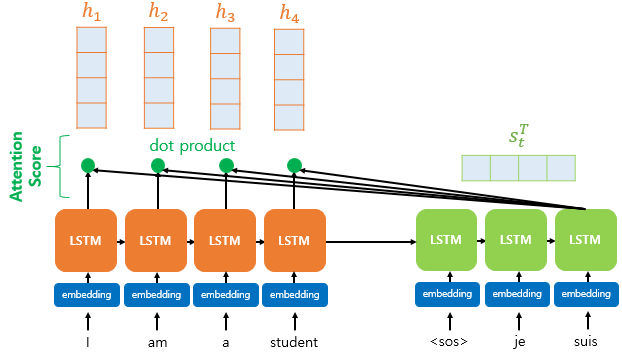
- 인코더에서 넘어온 4개의 Hidden-state 벡터는 디코더에서 key의 임베딩 벡터와 내적됩니다. 이때 key는 '나', '는', '학생', '입니다' 이렇게 4가지 입니다. 내적의 결과를 attetion score라고 부릅니다.
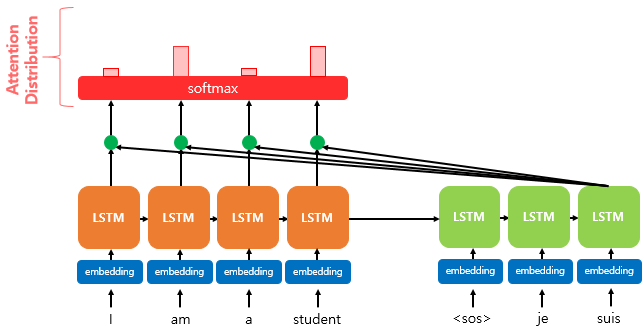
- 내적된 결과에 소프트맥스 함수를 취합니다. 소프트맥스 함수를 통해 나온 결과값은 'I', 'am', 'a', 'studendt' 단어 각각이 출력 단어('나','는', '학생','입니다')를 예측할 때 얼마나 도움이 되는지를 수치화한 값입니다. 값이 클 수록 서로 관련이 높다는 의미입니다. 소프트맥스로 출력된 0~1 사이의 값을 'attention distribution'이라고 부릅니다.
- attention distribution이 [0.1, 0.4, 0.1, 0.4]라면 각각의 값을 attention weight라고 부릅니다.
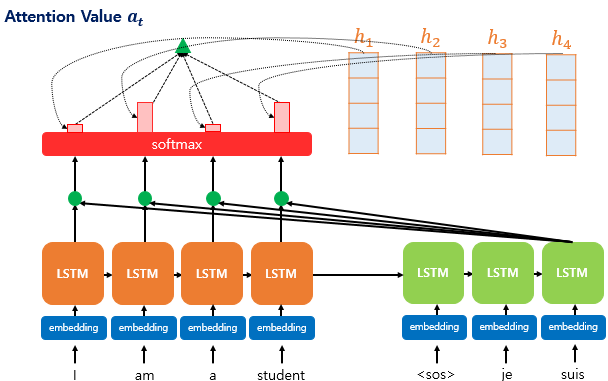
- 지금까지 준비해온 정보들을 하나로 합치는 단계입니다. 각 인코더의 은닉 상태(value)와 attention weight를 가중합합니다. 이를 attention 함수의 최종값인 attention value라고 합니다. 소프트맥스 함수를 거친 attention weight가 가중합되기 때문에 쿼리-키 연관성이 높은 인코더의 은닉 상태가 더 많이 들어있게 됩니다.
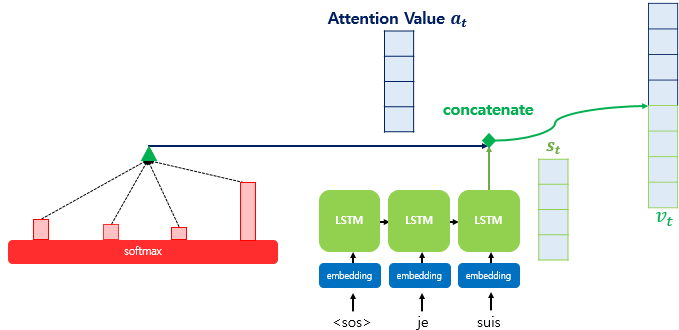
- attention value과 디코더의 t 시점의 은닉 상태를 Concatenate 합니다. 이 벡터를 v라고 부르겠습니다. 이 v를 예측 연산의 입력으로 사용하여 y를 예측하는데 인코더로부터 얻은 정보를 활용할 수 있게 됩니다.
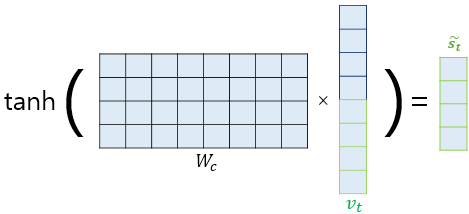
- 마지막으로, v를 출력층으로 보내기 전에 신경망 연산을 한 번 더 거칩니다. 가중치 행렬을 곱한 뒤에 하이퍼볼릭탄젠트 함수를 지납니다. 이 값을 최종 출력층 연산에 사용합니다.

-