
SQL의 내장 함수에 대해 더 알아보겠습니다.
1. GROUP BY
- 데이터를 묶어서 조회하는 기능입니다.
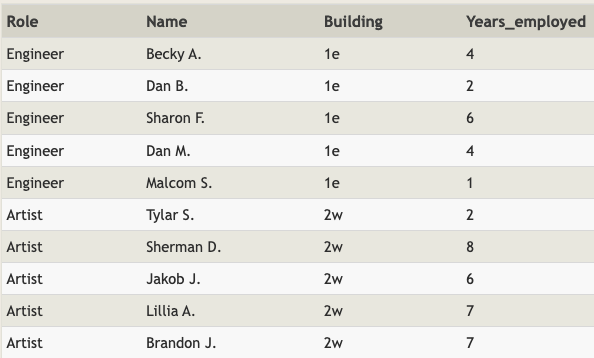
- 위와 같은 데이터가 있을 때, GROUP BY를 사용해서 직군 별로 몇명의 사람이 있는지 count할 수 있습니다.
SELECT ROle, count(*) As count_Role
FROM employees
GROUP BY role;
2. HAVING
- HAVING은 GROUP BY로 조회된 결과에 대한 필터입니다.
SELECT ROle, count(*) As count_Role
FROM employees
GROUP BY role
HAVING Role = Artist;- 위 커리를 실행하면 Artist 직군의 데이터만 출력됩니다.
3. Expression
- SQL은 다양한 연산을 할 수 있습니다.
- count 외에도 SUM/MIN/MAX/AVG 등의 결과를 출력할 수 있습니다.
- 아래 쿼리로 직군별 평균 근속연수를 출력합니다.
SELECT Role, AVG(years_employed) AS AVG
FROM employees
GROUP BY Role;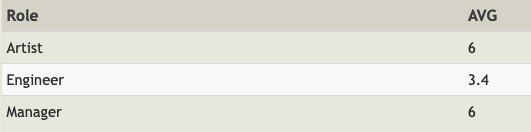
4. CASE
- python의 if문과 같은 기능입니다.
- CASE를 사용하면 정해진 조건에 따라 결과를 받을 수 있습니다.
SELECT Name, CASE
WHEN Years_employed >= 5 THEN 'senior'
ELSE 'junior'
END A
FROM employees;- 근속연수 5년을 기준으로 senior와 junior를 나누었습니다.

5. SUBQUERY
- 쿼리문을 작성할 때 다른 쿼리문을 포함하는 방법입니다.
- 실행되는 쿼리에 중첩으로 위치합니다. 서브쿼리는 소괄호 안에 위치합니다.
- 서브쿼리는 개별값들이나 레코드 리스트, 하나의 열을 결과로 돌려줄 수 있습니다.
- 테이블이 여러개일 때 사용합니다. 이번에는 예시 데이터를 바꿔보겠습니다.
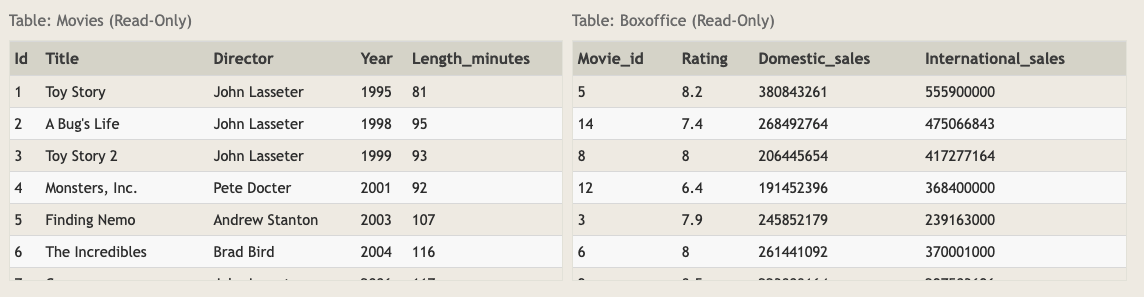
- 테이블이 두 개입니다. 영화 별로 총 판매량을 구해보겠습니다.
SELECT Title,
(SELECT SUM((Domestic_sales + International_sales) / 100000)
FROM Boxoffice b WHERE m.Id = b.Movie_id) AS Total
FROM Movies m;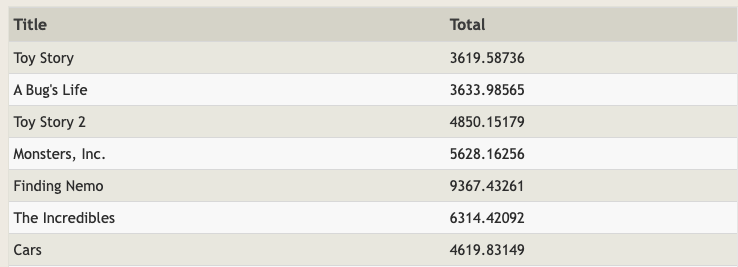
- 쿼리 결과입니다. 서브쿼리의 결과를 JOIN으로도 낼 수 있습니다.
- 주의해야할 건 서브쿼리의 작동방식입니다.
- 서브쿼리는 메인 쿼리의 개별 로우(키) 값과 하나씩 비교하는 방식으로 진행됩니다.
- 메인 쿼리와 서브 쿼리를 연결하는 id를 카운트한다고 했을 때,
- 서브 쿼리에서 id가 복수(ex. 7개)라면,
- 메인 쿼리의 id에 서브쿼리의 id가 7번 붙고 7개의 True를 반환합니다. 이걸 COUNT(id)한다면 메인 쿼리 id 하나에 7개의 Count가 반환됩니다.
- 서브쿼리에서 출력했던 결과를 JOIN 방식으로도 내려면 GROUP BY id로 COUNT를 분리해주어야 하지만, 서브쿼리는 내부의 작동방식으로 따로 COUNT하지 않아도 되는 것입니다.
- 서브쿼리에 IN/NOT IN을 사용할 수도 있습니다.
SELECT Title
FROM Movies m
WHERE id IN (SELECT b.Movie_id FROM Boxoffice b WHERE b.Rating > 8);- 평점이 8 이상인 영화만 출력할 수 있도록 쿼리를 날렸습니다.
- 서브쿼리는 평점이 8 이상인 영화의 id를 출력하라는 내용입니다.
- 서브쿼리의 결과를 WHERE이 받습니다. 서브쿼리의 Movie_id와 동일한 id를 필터해서 영화 타이틀을 Title을 출력합니다.
- FROM에도 서브쿼리를 사용할 수 있습니다.
SELECT *
FROM (
SELECT Movie_id
FROM Boxoffice
WHERE Rating > 8
)- 이때 서브쿼리와 메인쿼리는 같은 테이블입니다.

-