자료 출처 : KOCW 운영체제 - 반효경 교수님
0. 간략하게 알아보는 컴퓨터 구조
저장장치 계층 구조
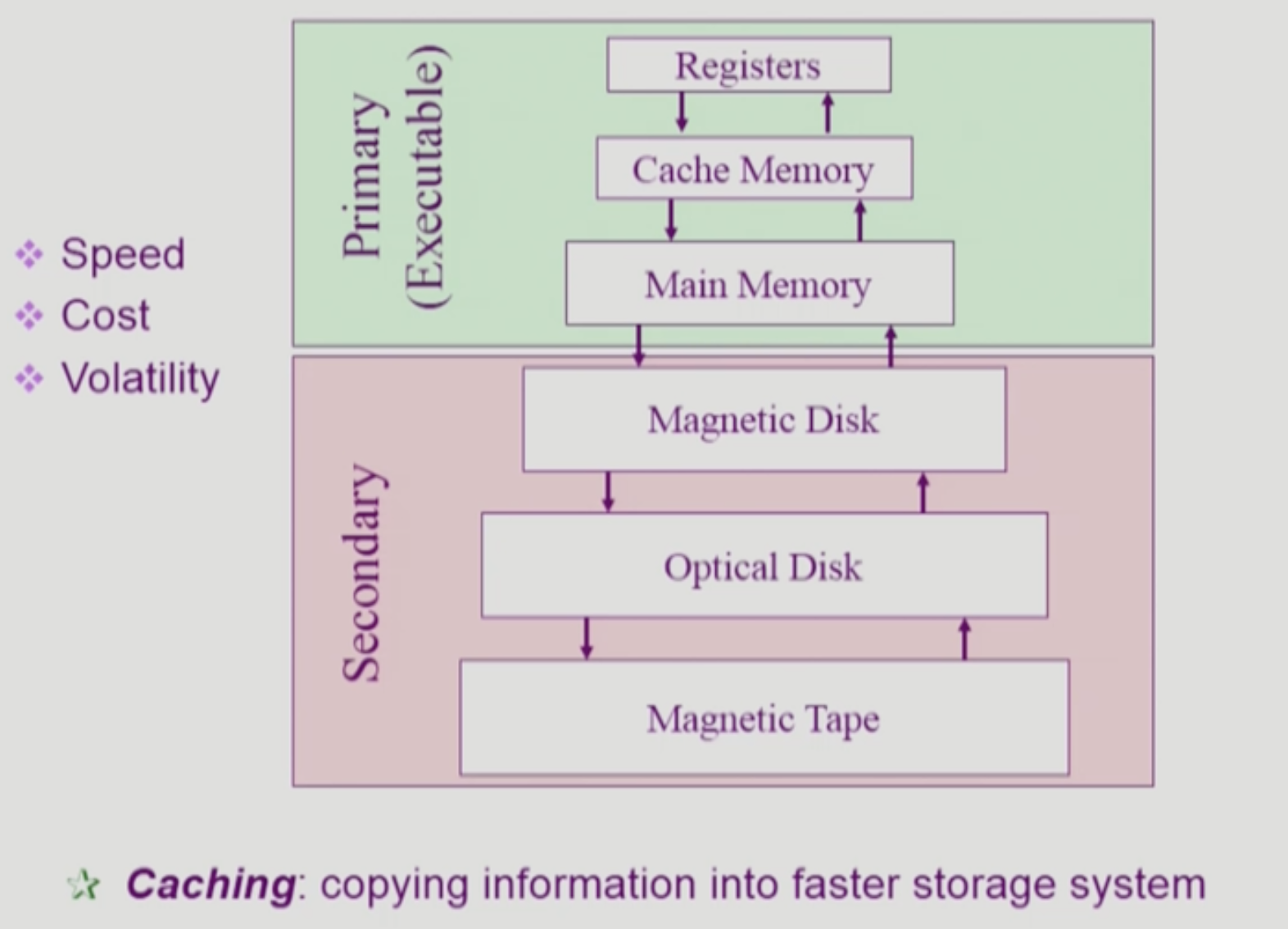
- 위로 갈 수록 접근, 처리 속도가 빠르다. 위로 갈 수록 휘발성이며, 단위 크기당 값이 비싸 보통 용량이 더 작다.
- cpu에 register가 막 여러개 들어있다. 하드웨어마다 다르지만 register는 32bit, 64bit 크기를 갖는다. 여기에 데이터나 instr 등등이 임시로 저장되고, cpu는 얘들을 가지고 논다.
- cache는 접근, 처리 효율을 높이기 위해 사용하는 것 정도로만 알아두자
- 재사용을 위한 것이다.
- main memory접근에 10~100 clock cycle까지 걸린다고 한다. 오래 걸리다보니, 이런 속도 차이를 완충하기 위해 cache를 두는 것. 얘도 용량이 main memory보다 작아서 데이터를 어떻게 넣고, 뭘 빼고 등등에 관한 정책도 존재한다.
- main memory는 ram이다. 아래 secondary 메모리들은 접근 속도가 너무 느려서 여기다가 필요한 것들을 가져와서 가지고 논다. 프로그램이 실행되면 ram에 올라가게 된다.
- primary는 cpu가 접근 가능하고, secondary는 cpu가 직접 접근할 수 없는 메모리이다.
- 접근 가능한 친구들은 byte단위로 주소를 매길 수 있는 친구들이다.
1. 컴퓨터 구조와 함께 알아보는 운영체제
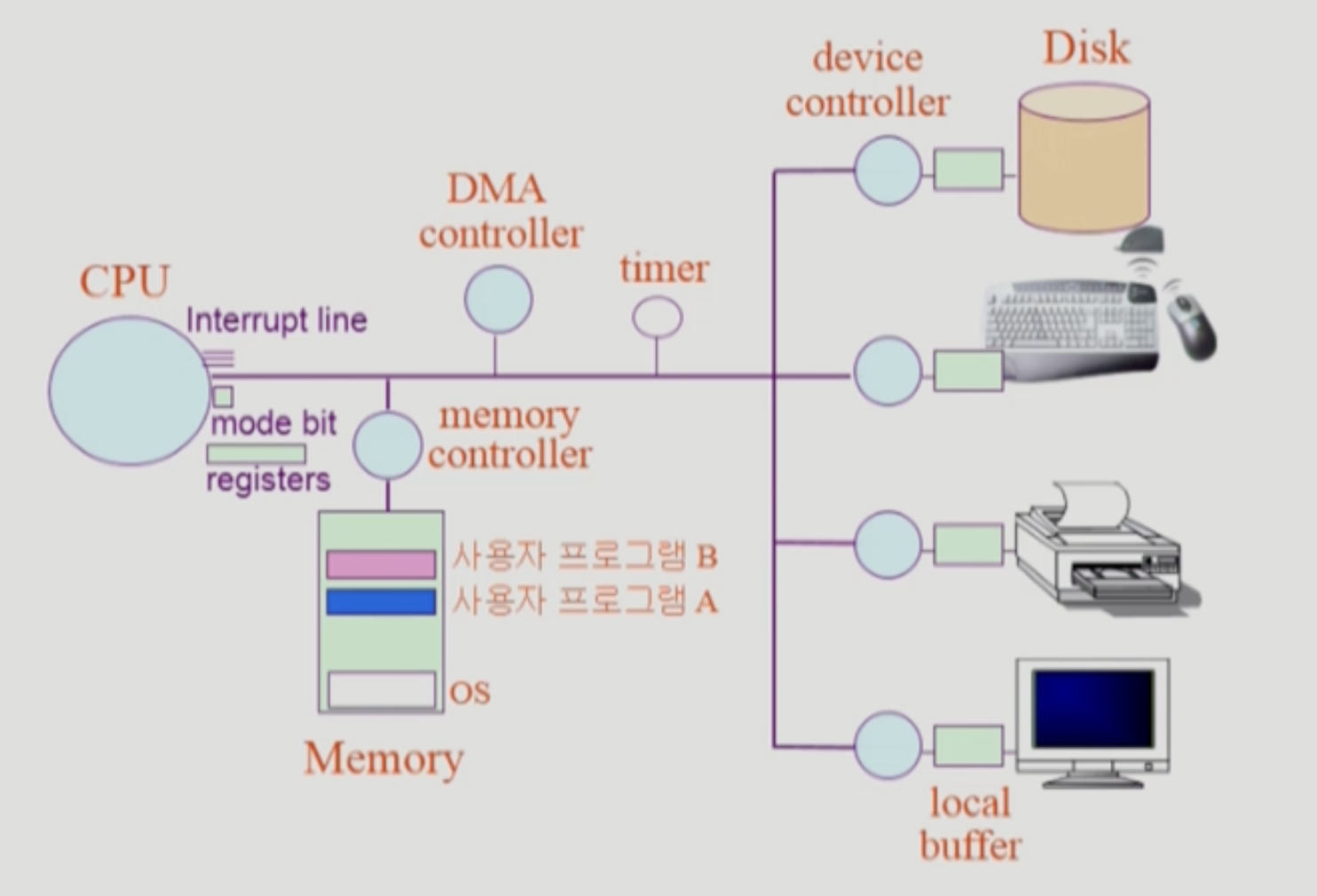
크게 좌측의 cpu와 memory 그리고 우측의 I/O 장치로 나눈다.
cpu, memory, disk가 위에서 알아본 친구들이고, 나머지는 컴퓨터에 연결되는 input, output 장치들이다.
1) CPU
cpu는 매 clock cycle마다 instr을 읽어서 실행. 그냥 이거밖에 안한다. 그 다음에는 다음 instr를 실행한다. 진짜다. 받아들여라!! 그냥 덧셈뺄셈논리연산 기타 등등 기본 연산만 주구장창 하는 친구이다!
- memory보다 접근 속도가 더 빠른, 정보 저장공간 register가 있다.
- mode bit이라는게 있는데, 실행하는게 운영체제인지 사용자 프로그램인지 구분
- interrupt line이라는 것도 있다.
mode bit
- mode bit : 0이면 운영체제가 cpu돌리는 중(커널 모드/모니터 모드). 1이면 사용자 프로그램(사용자 모드)이 cpu돌리는 중임을 나타낸다.
- 0일때는 io에 접근하고, 운영체제의 메모리 공간에 접근하고 뭐 그런 instr도 다 돌아간다. 1이면 제한된 instr만 실행할 수 있게 돼있다. 이런식으로
사용자 프로그램이 중요한 부분에 접근하는걸 방지한다.
interrupt line
- 키보드에서 어떤 입력이 들어왔다던가, disk에서 뭘 읽어와야한다던가, 아니면 읽어오는 일을 다 끝낸 경우 interrupt라는게 발생한다.
interrupt가 발생했는지를 interrupt line에 표기한다.cpu는 instr를 실행할 때마다 얘를 확인하고, interrupt가 발생했는지 확인한다.
💡
- instr = instruction
- 그냥 cpu에게 명령가능한 최소 실행 단위 정도로 이해해도 무방하다. 컴퓨터 구조를 공부해보면 알게된다
- interrupt에 대한 조금 더 자세한 것은 아래서 더 설명한다! 그냥 cpu 사용을 잠깐 멈춰야할 때 발생시키는 것 정도로 이해하고 있으면 된다. 급한 처리가 있다던가, 아니면 필요한게 완료돼서 이제 써먹을 수 있기 때문에 그걸 알린다던가, cpu쓸만큼 썼으니 다른 프로그램한테 cpu를 넘겨줘야한다던가~ 하는 경우들이다.
2) Timer
특정 프로그램이 cpu를 독점하는 것을 막기 위한 것
- while(true)같은거 돌리면 하나의 프로그램이 계속 돌 것 아닌가? 알다시피 cpu는 그냥 들어온 instr을 실행하는 것만 하는 친구이다.
- 그래서 cpu에 프로그램을 넘겨줄 때 timer에 특정 값(수십ms)을 세팅하고 넘겨준다. 그 후, 여기에 할당된 시간만큼 실행되면 timer가 cpu에 interrupt를 건다.
- timer 값은 매 clock cycle마다 1씩 감소한다.
- 운영체제가 아무리 잘 짜여져있어도, 다른 프로그램에 cpu를 넘겨주면 뺏어오는 것은 불가능하다. 당연하다. 뺏어오는 과정마저도 instr인데 cpu를 넘겨줬으니 이 instr은 실행 불가능한 것이다.
3) Device Controller / Local Buffer
i/o(input/output) device(이하 io라고 칭하겠다)는 키보드, 마우스, 프린터, 모니터같은게 있다.
각 io의 cpu, memory 역할을 하는게 controller, buffer이다.
Device Controller
- 헤드가 어떻게 움직이고 그런건 cpu가 조작하는게 아니라 controller가 하는 것이다. cpu는 얘한테 부탁만 한다.
- io 처리가 필요할 경우 cpu에 interrupt가 걸리고, cpu는 controller한테 특정 업무를 요청한다.
- 또, io 처리가 완료되면, controller가 cpu에게 interrupt를 건다.
Local Buffer
- io 친구들도 memory같은 작업 공간이 필요하다. buffer가 그 역할을 한다.
- 화면에 뭘 출력하고 싶다고 하자. 출력하고 싶은 데이터는 memory에 저장되어 있을 것이다.
- 컴퓨터는 이 데이터를 memory에서 buffer로 데이터를 카피해두고, controller한테 ‘너 그거 출력좀해라 나 그동안 다른 일좀 할게!’하고 명령해둔다.
💡
- 하드 disk는 보조 기억장치이지만, i/o로 볼 수도 있다. 여기서 메모리를 input으로 읽어오고, 처리 결과를 output으로 저장하기도 해서. 그냥 관점의 차이이다.
device driver
- device controller은 일종의 작은 cpu. 하드웨어이다.
- 그러나 이 친구는 소프트웨어이다. 각 장치를 다루기 위한 interface가 있는데, 이에 맞게 장치에 접근할 수 있게 해주는 소프트웨어 모듈인 것. 하드웨어 하나 붙이면, 그에 맞는 디바이스 드라이버 설치해야한다.
- io 장치에 접근해야하는 상황이 되면 드라이버를 통해 데이터 읽어오라고 명령을 하게된다. 근데 드라이버가 실제로 뭐 디스크에서 헤드를 움직이게하는 코드나 그런건 아니다.
- 펌웨어라고, 디스크를 동작하기 위해서 필요한 instr는 따로 있다. 디바이스 드라이버는 cpu가 실행하기 위한 코드를 담고 있다고 한다.
- 펌웨어에 대한 더 자세한 설명
소프트웨어를 통해 전달된 정보를 받아들인 하드웨어는 내부의 논리 회로를 거쳐 사용자가 원하는 형태의 결과물로 표현한다. 여기서 말하는 결과물이란 계산 결과의 출력이나 특정 기기의 동작 등을 의미한다. 그런데 컴퓨터 시스템의 활용 범위가 넓어지고, 소프트웨어에서 전달되는 정보 역시 방대해지다 보니 하드웨어 내 제한된 종류의 논리 회로만으로는 이러한 다양한 상황에 모두 대응하기가 어렵게 되었다.
물론, 새로운 소프트웨어가 등장할 때마다 그에 해당하는 기능을 갖춘 논리 회로를 추가한 하드웨어를 새로 만들 수도 있겠지만, 이렇게 하면 비용이나 시간 면에서 큰 낭비가 아닐 수 없다. 그래서 컴퓨터 개발자들은 하드웨어 내부의 제어 부분에 저장공간을 만들어, 그곳에 논리 회로의 기능을 보강하거나 대신할 수 있는 프로그램을 넣을 수 있게 하였다. 이것이 바로 펌웨어 이다.
따라서, 같은 종류의 하드웨어라고 해도 내부의 펌웨어가 달라지면 기능이나 성능, 혹은 사용하는 소프트웨어의 종류가 달라질 수 있다. 펌웨어는 프로그램의 형태를 갖추고 있으므로 기능적으로는 소프트웨어에 가깝지만 하드웨어 내부에 위치하며, 사용자가 쉽게 그 내용을 바꿀 수 없으므로 하드웨어적인 특성도 함께 가지고 있다고 할 수 있다.
출처[https://m.blog.naver.com/PostView.naver?isHttpsRedirect=true&blogId=kenjedai&logNo=220339611520]
4) DMA Controller / Memory Controller
local buffer와 memory에 접근하는 controller / dma controller와 cpu를 중재하는 controller이다.
DMA Controll
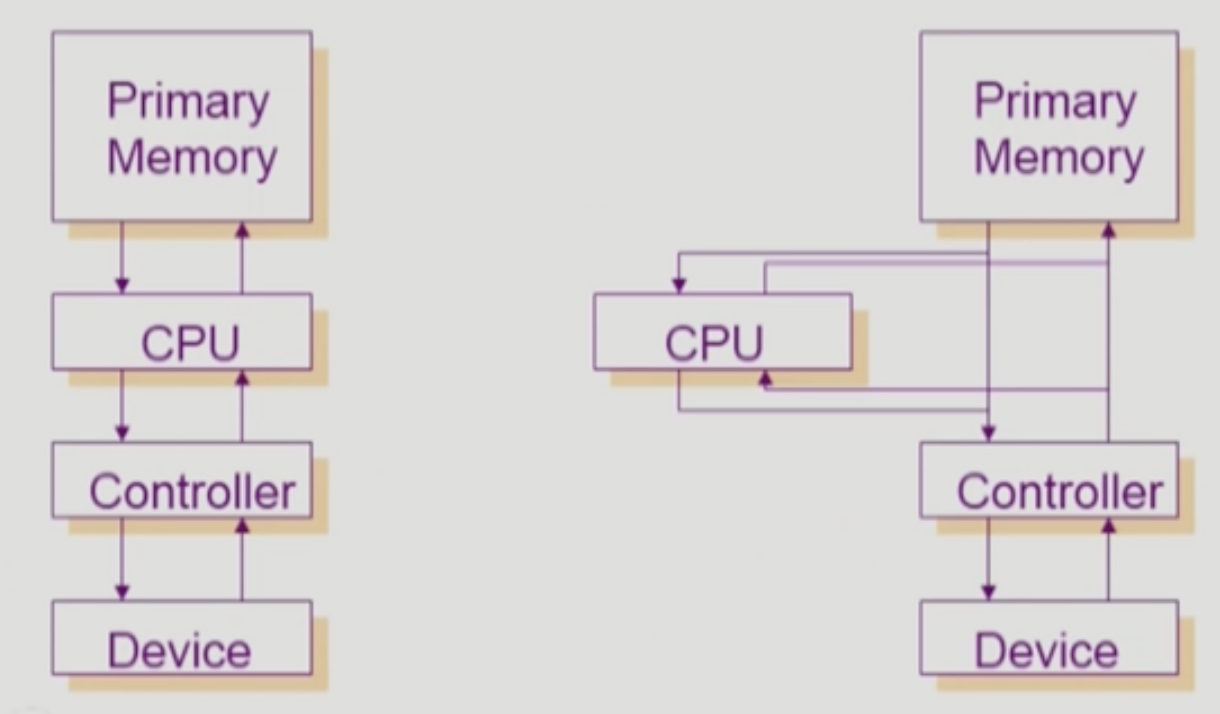
‘3)’에서 말한 것 처럼 io요청같은거 필요할 때마다 interrupt가 두번씩이나 걸린다. 키보드 자판 하나 두드리면 그 때마다 interrupt하게 되는 것이다. 그러다보니 cpu는 안그래도 일도 잘하고 빠른 친구인데 interrupt를 너무 자주 받아 효율이 떨어질 수 있다.
- 그래서 dma를 달아놨다. 얘가 local buffer의 내용을 메모리로 복사하게 하고, 그런 작업이 다 끝났으면 interrupt하고.
- 위 그림에서 controller라고 표기된게 dma controller이다.
- 이 친구는 buffer에서 block(그냥 공간을 나누는 단위이다.)단위의 io 작업에 대한 데이터를 가져온다.
- 키보드 자판 하나 두드리면 1byte인데, 이걸 한번 한번 계속 가져오면 너무 비효율적
Memory Controller
- 근데 그럼 cpu랑 dma controller가 같이 메모리에 접근하는 경우가 발생할수있고 그럼 큰일난다.
- 그래서 memory controller라는 애를 또 달아서 이걸 중재한다.
5) System Call
io 작업이 필요하면, interrupt가 발생하는건 위에서 잠깐 언급했다. 하지만 더 정확히는, io 작업이 필요하면 해당 프로그램은 알아서 cpu를 운영체제에 넘긴다. 여러 이유(보안 등등)로 io에 접근하는 것은 운영체제만 할 수 있도록 막아놨기 때문이라고 한다.
간략하게만 말하자면 꼭 io 작업이 아니더라도, 해당 프로그램이 운영체제에게 뭘 부탁하는걸 system call이라고 한다고 생각하면 편하다.
사용자 프로그램이 운영체제의 커널을 호출하는 것. 운영체제의 함수를 호출하기 위한 요청- 일반 함수 호출이랑은 다르다. 그냥 특정 메모리 주소로 점프해서 해당 instr을 실행하는게 아니다.
- 생각해보자. 일반 사용자 프로그램이 cpu에서 돌아가는 중일 때는 mode bit이 1이라 운영체제 메모리 공간에 접근이 안된다.
- 그래서 프로그램이 직접 interrupt line을 세팅하는 instr을 수행한다.
- 프로그램이 소프트웨어적으로 직접 interrupt를 걸엇기에, 운영체제는 mode bit을 0으로 바꾸고, cpu는 운영체제에게 넘어간다.
6) Interrupt
위에서 주구장창 이야기했던 interrupt!!
CPU는 매 순간 하나의 instr만 실행 가능하고(파이프라인같은 이야기는 배제하고 단순히 말해서), 이 때 이 instr들은 하나의 프로그램에서 연속적으로 읽어오는 것들이다.
이 때 위에서 본 여러 상황과 이유로, 하나의 프로그램에 대한 instr만 주구장창 수행하고 있으면 비효율적인 경우가 발생한다. 따라서 잠시 해당 프로그램의 instr 실행을 멈추고 다른 작업을 진행할 수 있도록 해야하고, 그 것이 interrupt이다.
- 더 정확히 말하자면,
레지스터와 program counter를 save한 후, cpu의 제어를 interrupt service routine에 넘기는 행동이다.
💡 ~~를 save하는 것은, 그냥 넘어가두자. 컴퓨터 구조를 공부했다면 무슨 말인지 이해할 것이지만, 지금 당장 매우 중요한 것은 아니다. interrupt service routine은 바로 아래서 설명할 것!
Hardware Interrupt / Software Interrupt
software interrupt
- 5)에서 봤듯이, 프로그램이 스스로 interrupt를 걸어 운영체제를 호출하는 것이다.
- trap이라고도 한다. 얘도 두 종류가 있다.
- system call : 사용자 프로그램이 필요에 의해 커널 함수를 호출하는 경우
- excepction : 프로그램이 오류를 범한 경우. 0으로 나누는 연산이라던가
- 이렇게 trap을 걸면 os는 올바른 io요청인지, 권한은 있는지 등등을 체크하고, io요청을 컨트롤러에게 부탁한다.
hardware interrupt
- 하나의 프로그램의 독점을 막기 위해 timer가 거는 interrupt, io 작업이 끝나 device controller가 거는 interrupt 등이 있다.
- 일반적으로 interrupt라고 하면 이 친구를 가리킨다고 한다.
Interrupt Service Routine / Interrupt Vector
Interrupt 종류마다 운영체제가 해야할게 다를 것이다.
키보드 컨트롤러한테서 들어온거면 로컬 버퍼에서 데이터를 메모리로 카피할거고, io를 요청했던 프로세스한테는 너 이제 cpu쓸 수 있어!! 하고 알려줘야할 것이고, 타이머면 cpu뺏어서 다른애한테 줘야할것이다.
Interrupt Service Routine
- 무엇을 해야할지는 운영체제 코드에 정의가 되어있다. 이런 실제 코드를 인터럽트 처리 루틴(interrupt service routine, 혹은 interrupt handler)이라고 한다.
Interrupt Vector
- 어떤 interrupt가 왔을 때 어디로 가야할지, 어디있는 함수를 실행해야하는지, 그 함수들의 주소들을 정의해놓은 테이블을 interrupt vector 라고 한다.
Interrupt가 일어나고 나서는 어떤 일이 일어날까?
cpu를 빼앗긴 프로그램은 다음과 같은 과정에 의해 다시 cpu사용권을 얻게 된다.
io에서 발생시킨 interrupt
- i/o 장치에서 특정 업무가 처리되면, device controller가 cpu에 interrupt를 건다.
- 어떤 프로그램이 cpu에서 돌고 있었겠지만, interrupt가 걸렸기에 cpu가 운영체제에 넘어가게 된다.
- 운영체제는 입력된 값을 이 전에 입력을 요청한 프로그램의 메모리 공간에 카피를 해주고, 보통은 방금까지 cpu쓰던 친구한테 cpu를 넘어준다.
- 그 후 언젠가는 키보드 입력을 요청햇떤 애한테 cpu가 넘어가게 될 것
디스크에서 뭐 읽어오는 것도 마찬가지로, 디스크 컨트롤러에게 시켜놓고, 읽는 동안 cpu는 다른 프로그램이랑 놀다가, 디스크에서 다 읽으면 컨트롤러가 interrupt를 걸고. 운영체제에게 cpu가 넘어가고. 운영체제는 해당 작업을 요청한 내용, 즉 로컬 버퍼에 있는 내용을 해당 프로그램의 메모리 영역에 카피한다.
2. 조금 더 자세한 컴퓨터 동작 방식
1) IO - 동기식 입출력과 비동기식 입출력
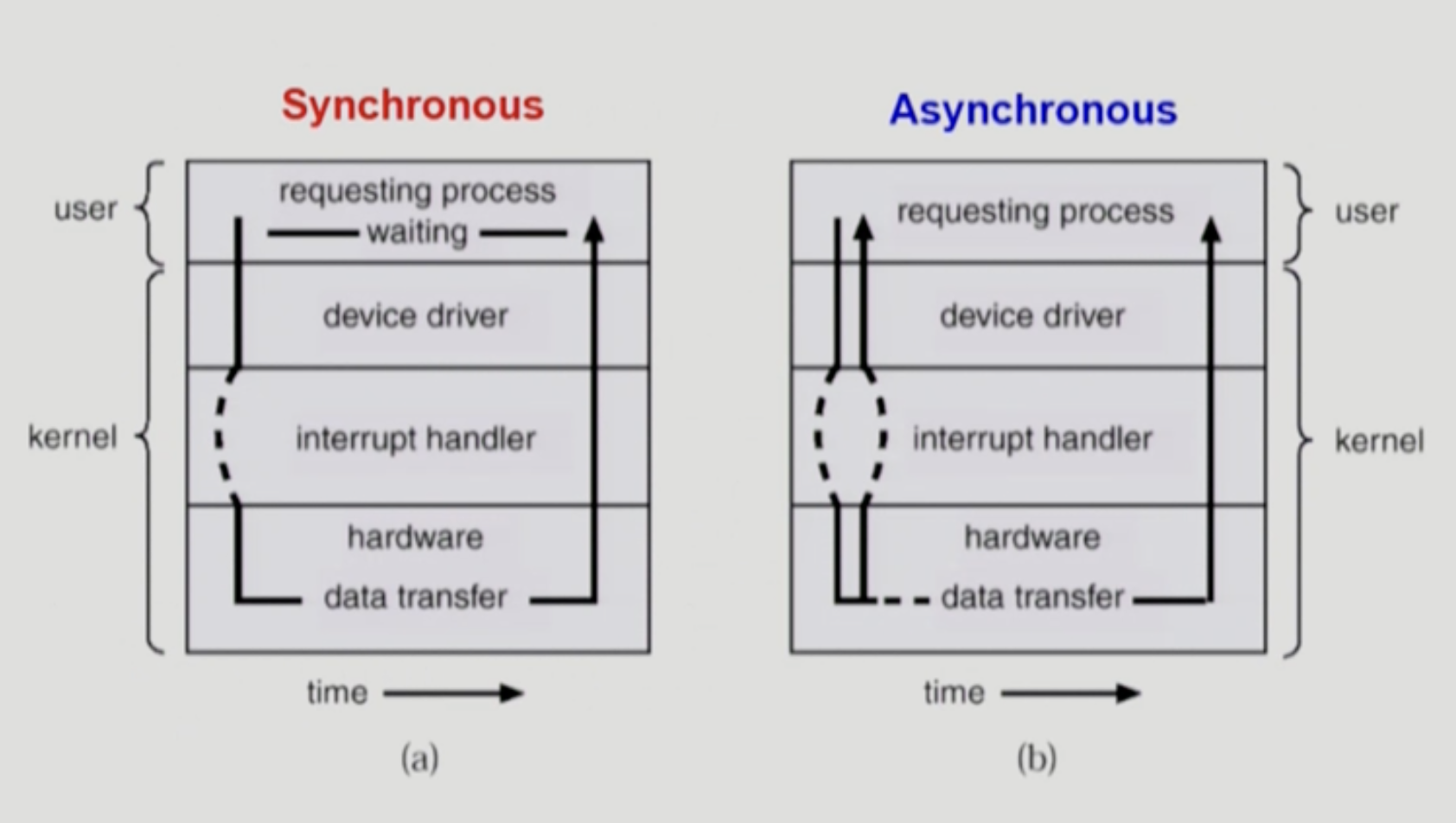
synchronous io
단어가 와닿지 않을 수 있다. 립싱크를 떠올려보자. 소리랑 입이랑 맞아야한다. 이런게 싱크이다. 서로 시간적으로 맞추는 것!
synchonous io는
- io 장치까지 직접가서 결과를 보고 오는 것이다.
io를 요청한 후, io 작업이 끝난 후에야 사용자 프로그램에 제어권이 넘어가는 것- 사용자 프로그램이 io요청을 보내면 kernel에서 device driver를 거치고 io 작업을 하고, 끝이 난다. 이걸 waiting 하면 sync
구현 방법이 2개이다.
- io 끝날때까지 그냥 cpu 낭비. 매 시점 하나의 io만 일어날 것이다.
- io 요청한다음에, io처리가 완료될 때 까지 io 처리를 기다리는 줄에 프로그램을 세워둔다. 그 후, 다른 프로그램한테 cpu넘기는 것이다.
- 보통 이런 방법으로 구현한다고 한다.
- io device controller가 interrupt 걸면 그 때 다시 cpu 제어권을 넘겨준다.
asynchronous io
- io가 시작된 후 io 작업이 끝나는 것을 기다리지 않고, 제어가 사용자 프로그램에게 즉시 넘어가는 것
- write은 aync하게 하는게 자연스러울 것이다. 뭘 읽어오는 경우는 그 결과를 가지고서 특정 로직을 수행하기도 하지만, 보통 출력하거나 저장하는 것은 그 결과를 기다릴 필요까지는 없기 때문이다. 물론 아닌 경우도 당연히 존재하겠지만. 어쨋든 이건 구현하기 나름
💡 두 경우 모두 io controller가 interrupt를 걸어서 끝난걸 알려준다.
2) IO - 서로 다른 입출력 명령어
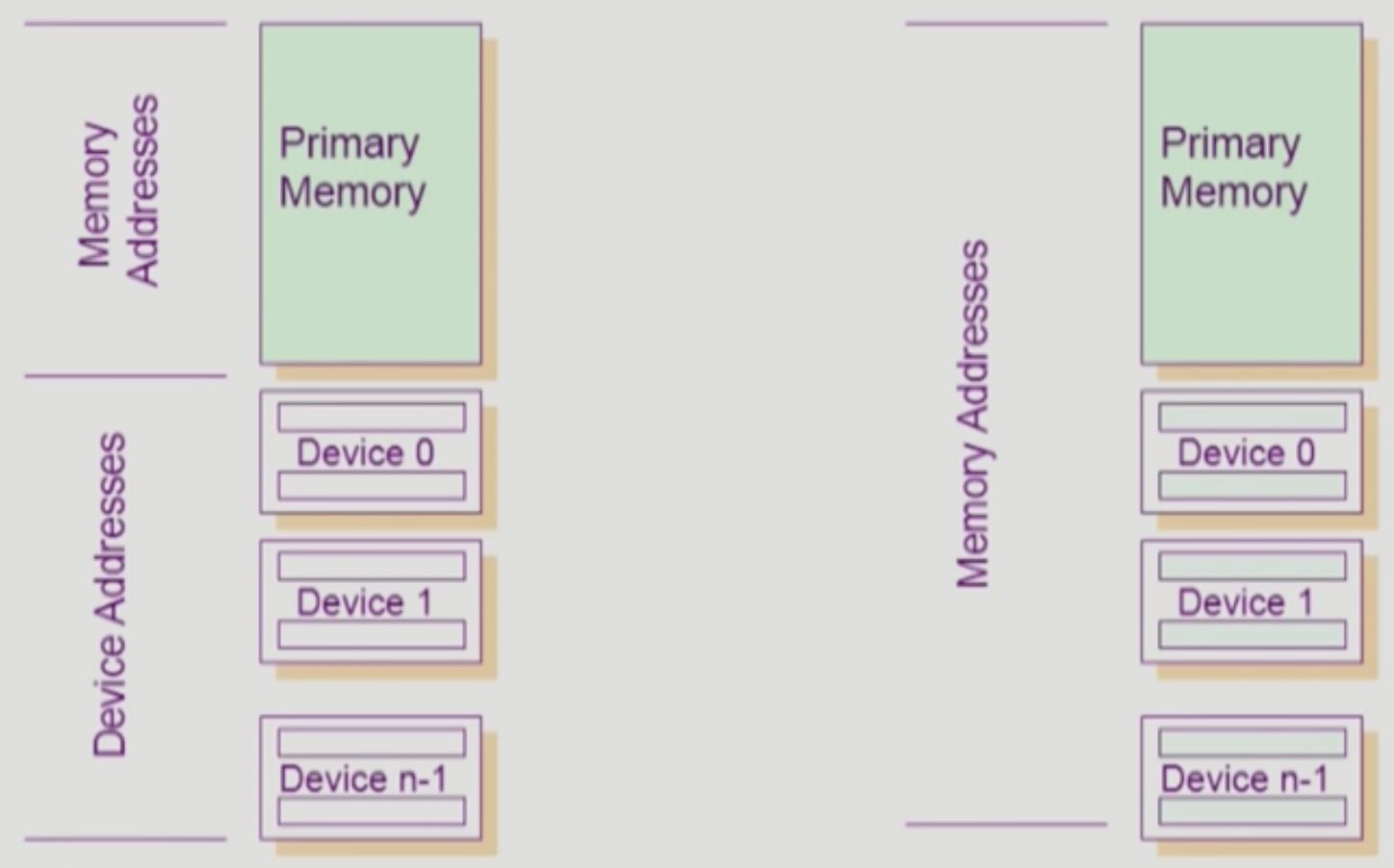
io에 접근하는 방법은 두가지가 있다.
io를 수행하는 특별한 instr사용
- 얘는 memory addr이랑 device addr를 별개로 둔다. memory에는 load/store 같은 명령어에 memory addr를 줘서 접근하고 io는 다른 명령어, 다른 addr를 쓰는 것이다.
memory mapped io 사용
- 각 device들을 memory addr에 매핑해서, 그냥 load/store같은 명령어 써서 memory접근하듯이 접근한다.
💡
- addr = addres
- cpu가 memory에 접근해야할 경우가 있다. 무언가를 저장해야할 수도 있고, 무언가를 가져와야할 수도 있다. 그 무언가가 저장되어있는 위치가 address이고, 그런 동작을 수행하게하는 명령어가 load, store이다. 이 두개에 다른 것들을 조금 더 합치면 instr이 된다!
3) 프로그램의 실행(메모리 load)
먼저 memory는 stack, heap, data, code 정도로 구역이 나뉜다.
- code는 실제 실행해야할 프로그램이 들어가는 곳이다. 가위바위보 게임, 자판기 프로그램 등등을 한번쯤 만들어봤을 것이다. 당신이 써내려간 그 코드들이 요렇게 저렇게 처리돼서 여기에 저장된다.
- data는 프로그램의 전역 변수, 정적 변수가 저장된다. 그냥 필요한 데이터들 저장되는 곳 정도로 생각하면 된다.
- stack은 함수의 호출가 관계되는 지역 변수, 매개 변수 등이 저장되는 곳이다. ‘함수의 호출과 관계되는’이 포인트. 함수가 다른 함수를 부르면 stack에 계속해서 그런게 쌓여나간다. 그정도만 알아두자
- heap은 사용자가 직접 관리하는 메모리 영역이다. 메모리 공간이 동적으로 할당, 해제된다. 이해안가면 일단 무시해도 된다.
프로그램의 실행과 virtual memory
이제 프로그램이 실행되는 과정을 알아보자. 프로그램은 코드 덩어리이고, 그런 코드 덩어리는 code에 저장되고, 그 과정에서 가지고 놀아야할 데이터는 data에 저장되고, 프로그램 내 함수가 호출되고 어쩌고 하는건 stack에 저장된다는 것을 염두하고 보면 된다.
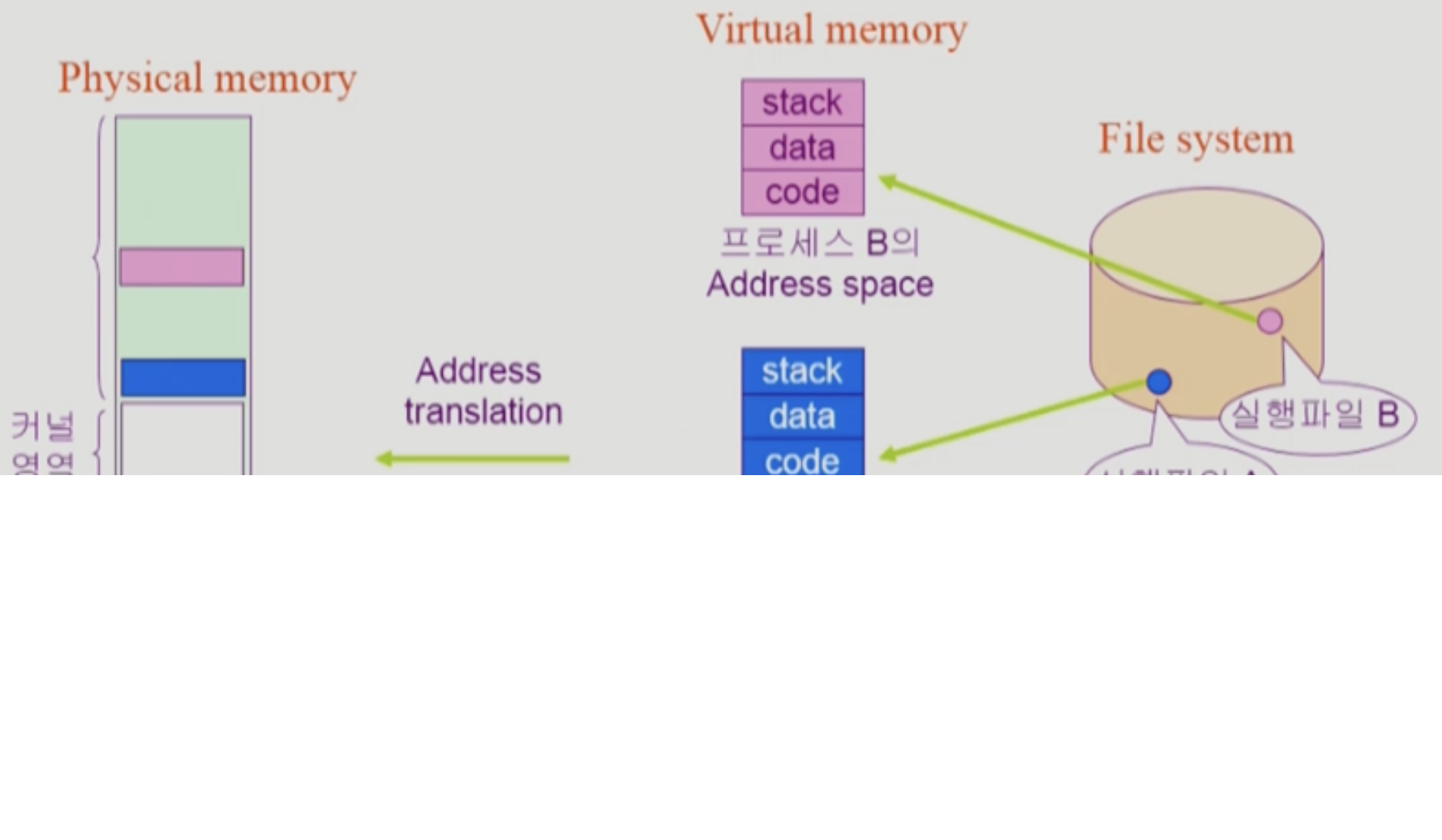
- 프로그램은 실행파일 형태로 하드디스크에 저장이 된다.
- 프로그램을 실행한다는 것은, 메모리에 올라가서 프로세스가 되고, 이 프로세스 안에 있는 여러 명령을 수행하는 것이다.
- 정확히는 중간에 virtual memory를 거쳐간다.
- 프로그램을 실행하면, 프로그램만의 독자적인 주소공간이 생성된다.
- 프로그램 전체를 모두 physical memory(실제 memory. ram. 우리가 아는 그 ram)에 올리는 것은 여러 이유로 낭비이다. 따라서 필요한 부분만 그 때 그 때 올라가게 된다.
- 필요 없는 부분은 disk에 올려놓는다. 그 중 특별히 swap area라는 곳에 올려놓는다.
- 필요 없으면 ram에서 쫓아낸다. 나중에 다시 쓰기 위해 알아둬야할 정보 등등을 함께 저장할 것이다.
- 즉, virtual memory라는 어떤 가상의 것을 만들어, 거기에는 프로그램을 실행하기 위한 정보를 쭉 연속적으로 나열 시켜 놓고, 실제로는 얘들을 쪼개서 여기저기(physical memory, swap area)에 흩뿌려놓는 것
- virtual memory상의 데이터들이 “실제"로는 어디에 박혀있는지 알아야하고, 이러한 것들을 잘 수행하기 위해 address translation이라는 과정이 필요하다.
kernel의 memory
💡 kernel?
- 운영체제에서 핵심적인 부분을 모아놓은 것이다.
- 잊지말자! 운영체제도 프로그램이다. kernel도 뭐 프로그램인 것이다.
- 당연히 얘도 memory에 올라가야 실행이 되는 것이고, 프로그램이기 때문에 위에서 본 프로그램 실행 과정과 비슷한 부분이 존재한다.
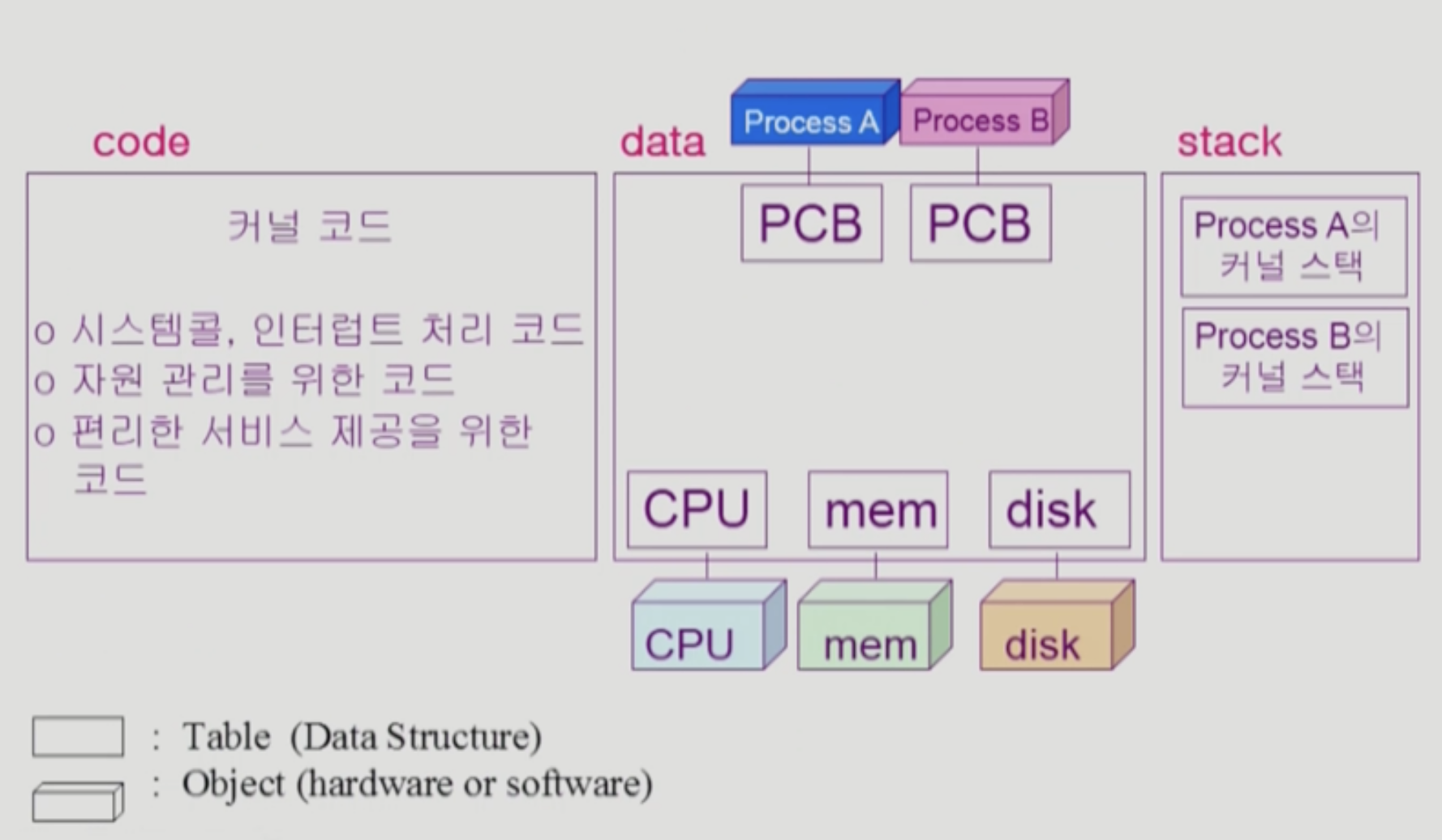
kernel의 memory 또한 code data stack으로 이루어진다. 각 영역에는 다음과 같은 것들이 저장된다.
code
- system call, interrupt 처리 코드
- 자원 관리를 위한 코드
- 편리한 서비스 제공을 위한 코드
data
- 운영체제가 사용하는 여러 자료 구조
- 하드웨어를 관리하므로, 하드웨어들마다 추상적으로 자료 구조를 만들어 사용
- 프로세스도 관리하므로, 얘들을 관리하기 위한 자료구조(PCB)도 저장한다.
stack
- 얘도 프로그램이라 stack이 있다.
- 운영체제의 코드는 여러 사용자 프로그램들이 호출해 사용할 수 있다. 기억안나면 나중에 위부터 다시 읽어보자 ㅎㅎ
- 따라서 사용자 프로그램마다 kernel stack을 따로 두고 있다.
4) 사용자 프로그램이 사용하는 함수
프로세스 code 영역에 저장되는 함수
사용자 정의 함수
- 프로그램에서 정의한 함수
라이브러리 함수
- 자신의 프로그램에서 정의하지 않고, 가져다 쓴 함수
- 컴파일 할 때 자신의 프로그램의 실행 파일에 포함된다.
커널의 code 영역에 저장되는 함수
커널 함수
- 운영체제 프로그램의 함수
- 커널 함수의 호출 = 시스템 콜
- 당연히 프로그램이 얘를 호출하는 상황이 있더라도 프로그램의 실행 파일에 얘가 포함되지 않는다. 또한 언급했듯이 여기로 바로 jump해서 instr를 읽어들일 수 없다. 이 것 또한 위에서 한번 언급했던 적이 있다.
따라서 프로그램의 실행과 종료 과정은 다음과 같이 간략하게 표현할 수 있다.
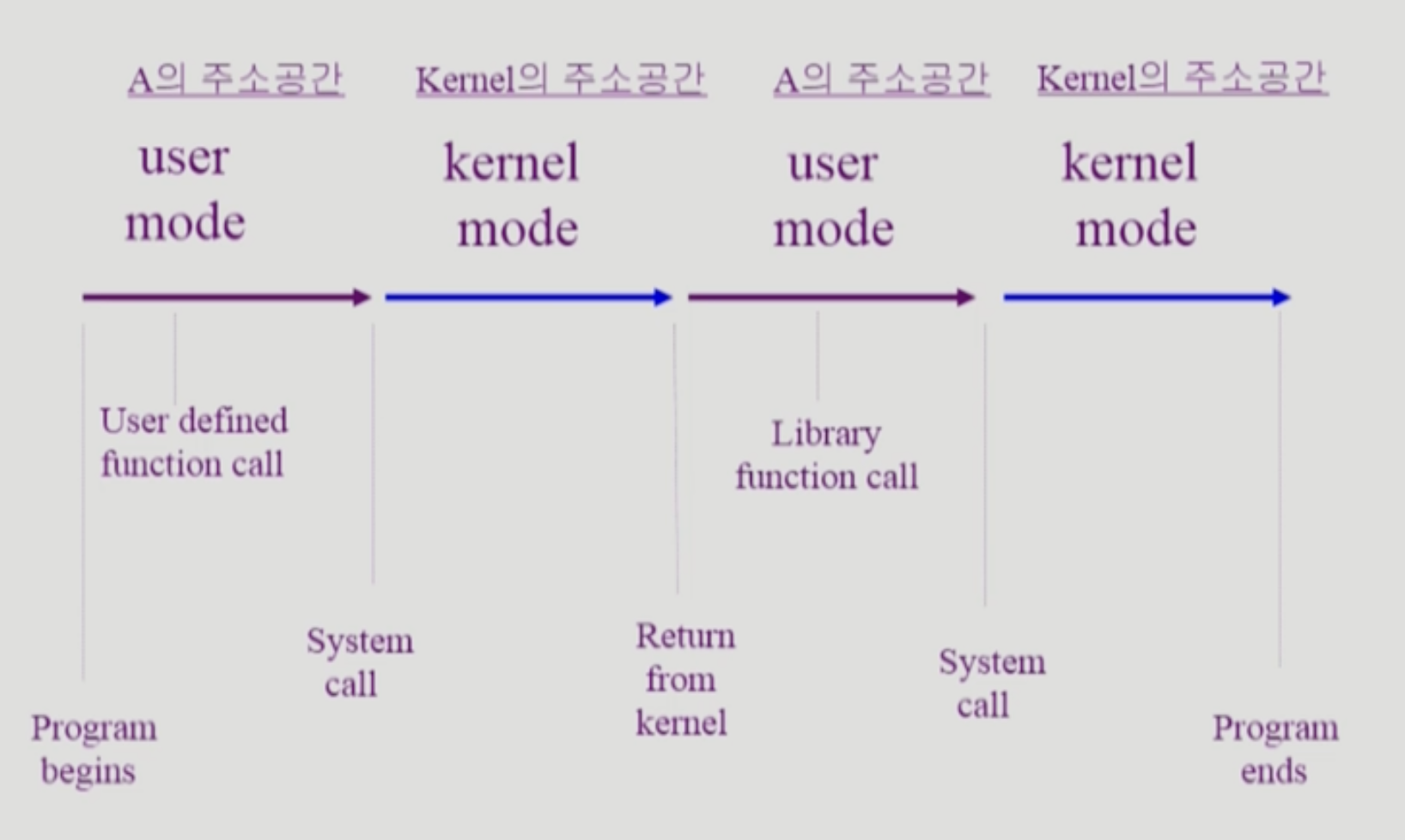
- 프로그램 실행은 위와 같이 실행되는 것
- 보통 프로그램이 cpu를 잡고 있으면 user mode에 있다고 한다.
- cpu를 얻었다 잃었다 하는 과정은 생략되었다.
