
Java Collections API에 존재하는 HashMap은 HashTable 자료구조로서, O(1)에 해당하는 get연산과 put연산을 지원합니다.
상수 시간의 연산은 매력적이라 많이 사용되곤 하죠.
오늘은 Java 11 (Bellsoft의 liberica JDK)에서의 HashMap 구현에 대해서 살펴보겠습니다.
Java에서의 HashMap?
Java에서 해시테이블의 자료구조로 HashTable, HashMap이 있습니다.
그 둘의 가장 큰 차이점은 동기화의 여부입니다. 멀티스레드 환경에서 HashTable은 동기화를 자체적으로 지원하지만 HashMap을 지원하지 않습니다. 구조적인 변경이 이루어지는 경우, HashMap은 동기화 객체를 따로두어 관리해야만 합니다.
여기서 말하는 구조적인 변경이란, 새로운 키매핑을 생성하거나 제거하는 행위를 말하며 단순히 존재하는 키에 매핑된 값을 변경하는 행위는 해당하지 않습니다.
그 외에도 HashTable과 달리 null을 허용한다는 차이가 있습니다.
HashMap의 상속구조와 인터페이스구조
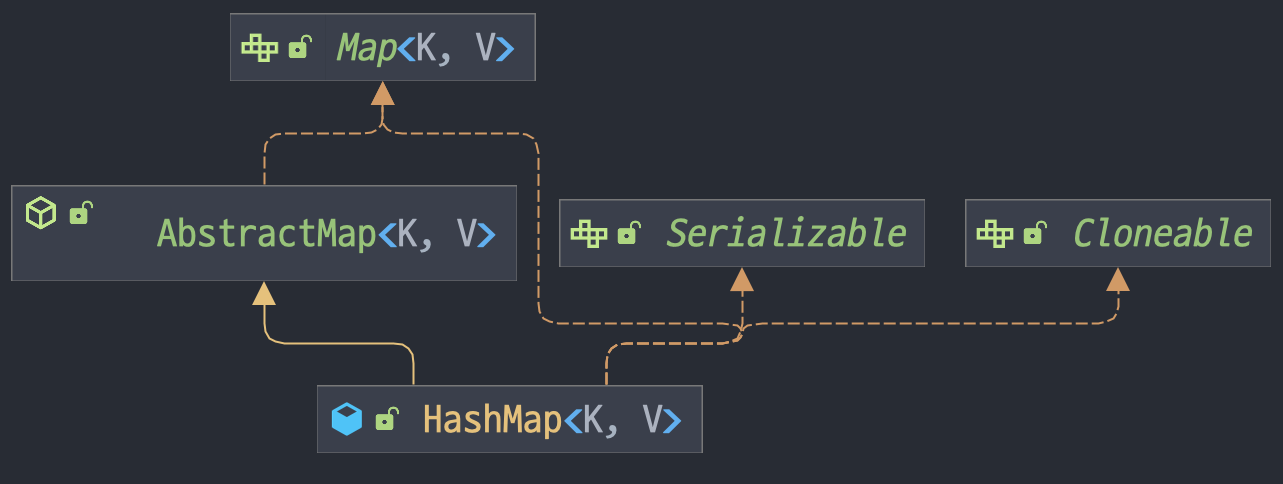
HashMap은 AbstractMap 클래스를 상속받으면서 Serializable,Cloneable 인터페이스를 구현하고 있습니다.
AbstractMap은 Map 인터페이스를 구현하는 추상클래스로 스켈레톤을 제공하여, Map 인터페이스를 구현하기 쉽게 해줍니다.
Serializable 인터페이스는 자바에서 직렬화와 역직렬화와 관련된 인터페이스입니다. ObjectStream을 통해 write하거나 read할 때 사용됩니다.
Cloneable 인터페이스는 Object.clone() 과 관련된 인터페이스로, Clonable 인터페이스를 구현하지 않으면 Object.clone()이 호출되었을 때 CloneNotSupportedException 예외가 발생합니다.
HashMap의 구현
해시테이블에서 가장 중요한 것은 역시 "해시 충돌을 어떻게 해결할 것인가" 아닐까요?
해시 충돌을 해결하는 방법은 크게 체이닝, 개방 주소 방법이 있습니다.
HashMap은 체이닝 방법을 이용하며, 체이닝 된 값들의 개수에 따라 그 방법을 달리하고 있습니다.
일반적으로 체이닝은 같은 해시값을 연결리스트로 관리하는 방법을 말합니다. 하지만 해시 불균등으로 인해서 연결리스트의 크기가 커진다면 해시테이블의 장점이 사라질 겁니다.
그렇다면 HashMap은 어떻게 이 문제를 해결할까요?
HashMap의 Node, TreeNode
일반적으로 HashMap은 중복되는 해시코드를 갖는 Key들에 대해서 연결리스트로 관리하게 됩니다.
연결리스트 안의 Node들은 다음과 같이 정의되어 있습니다.
static class Node<K,V> implements Map.Entry<K,V> {
final int hash;
final K key;
V value;
Node<K,V> next;
...
}HashMap에서는 연결리스트의 크기가 8이 될 때, 이 연결리스트를 레드블랙트리로 바꾸어서 관리하게 됩니다.
static final class TreeNode<K,V> extends LinkedHashMap.Entry<K,V> {
TreeNode<K,V> parent; // red-black tree links
TreeNode<K,V> left;
TreeNode<K,V> right;
TreeNode<K,V> prev; // needed to unlink next upon deletion
boolean red;
...
}그렇게 되면 같은 해시코드를 갖는 Key사이에서 탐색하는 시간이 연결리스트에 비해 줄어들게 되겠지요.
하지만 같은 해시코드를 갖는 Key들이 다시 적어질 경우, Key 탐색시간보다 이를 유지하는 오버헤드가 커져서 트리형태가 불리해지게 됩니다.
그래서 HashMap에서는 트리 원소의 개수가 6보다 적어지면 다시 연결리스트로 바꾸어서 관리합니다.
이를 관련 변수 TREEIFY_THRESHOLD, UNTREEIFY_THRESHOLD로 관리하고 있습니다. static final로 선언되어 프로그래머 입장에서 바꿀수 없는 변수입니다.
Tie Break
동일 해시코드를 갖는 노드들이 많아지면 트리형태로 바뀐다는 것을 알겠는데,
그렇다면 트리 안에서 어떻게 원하는 값을 찾을 수 있을까요?
이는 HashMap의 Key가 어떤 형태를 가지고 있는 지에 따라 다릅니다.
만약 Key가 Comparable 인터페이스를 구현하는 경우, compareTo() 메소드를 활용하게 됩니다.
Key가 Comparable 인터페이스를 구현하지 않는 경우에도 다음 함수로 자체적으로 순서를 매기게 됩니다.
static int tieBreakOrder(Object a, Object b) {
int d;
if (a == null || b == null ||
(d = a.getClass().getName().
compareTo(b.getClass().getName())) == 0)
d = (System.identityHashCode(a) <= System.identityHashCode(b) ?
-1 : 1);
return d;
}
재밌게도 클래스 이름으로 순서를 정하게 되고, 클래스 이름이 똑같은 경우 기본 해시코드로 비교하게 됩니다.
그럼 전환 오버헤드는요?
동일 해시코드를 갖는 Key들이 많아져서 트리형태로 전환하는 경우의 오버헤드에 대해서 생각 안해볼 수가 없겠죠.
일반적으로 해시코드가 균등하게 분포한 경우, 각 해시코드의 빈도수는 포아송 분포를 따릅니다. (포아송 분포란?)
그래서 체이닝 방법을 사용할 때, 연결리스트의 크기 k에 따른 확률은 로 계산할 수 있습니다. (load factor가 0.75인 경우, 람다를 0.5 정도로 잡을 수 있습니다.)
가장 작은 k부터 확률값을 살펴보면,
| 연결리스트 크기 | 확률 |
|---|---|
| 0 | 0.60653066 |
| 1 | 0.30326533 |
| 2 | 0.07581633 |
| 3 | 0.01263606 |
| 4 | 0.00157952 |
| 5 | 0.00015795 |
| 6 | 0.00001316 |
| 7 | 0.00000094 |
| 8 | 0.00000006 |
| 8 < | 1000만분의 1보다 작음 |
따라서, 적절한(균등한) 해시코드를 사용하게 되면 체이닝된 연결리스트의 크기가 8이 넘는 경우는 굉장히 드물게 됩니다.
한마디로 말해서, 해시코드를 잘 구성한다면 전환 오버헤드를 신경쓸 필요는 없습니다.
또, 해시테이블의 크기가 작을 때는 트리 형태로 전환되지 않습니다.
테이블의 크기가 작으면 상대적으로 resizing이 일어날 확률이 크기 때문입니다. Resizing이 이루어지면 모든 Key-Value 쌍들이 다시 해시가 이루어지기 때문에 큰 오버헤드가 발생하게 됩니다.
따라서 HashMap에서는 테이블 크기가 작을 때 트리 형태로 전환되는 것을 막으며, 이를 MIN_TREEIFY_CAPACITY 변수를 두어서 관리하고 있습니다.
마무리
HashMap이 Java 11에서 어떻게 구현되어있는 지 대략적으로 살펴보았습니다.
이로써, 저희는 HashMap이 가지는 장점을 잘 활용하려면 해시코드를 균등하게 분배할 수 있어야 합니다.
균등한 해시코드 외에도 HashMap 성능과 직결된 요소들이 있습니다.
Resizing과 관련해서 capacity, load factor가 중요한 역할을 합니다.
해당 부분은 본문에서 다루지는 않지만, 꼭 살펴보시길 바랍니다.
