1. 개념 정리
1) 동의어, 다의어의 처리
- 임베딩의 문제
학습을 시킬 땐 문맥을 고려하기 때문에 동의어, 다의어 등이 구분됨. 하지만 테스트를 할 땐 문맥을 고려하지 않고 고정된 하나의 벡터로 표현하게 됨. - 해결
문맥을 고려하는 임베딩 모델 이용
2) Transfer Learning
특정 환경에서 학습을 마친 신경망(일부 혹은 전부)을 유사하거나 다른 환경에서 사용하는 것
1. 자연어 처리에서의 전이학습: language model
- 언어모델: 주어진 sequence가 얼마나 자연스러운지 학습 (ex - 밥을 먹다 / 밥을 마셨다 구분)
- downstream task(전반적인 학습을 이미 진행한 신경망에 관련된 문제를 해결하게 할 때, 관련된 문제를 칭함)를 잘 풀기 위해 pretrained model을 재학습시키는 것을 fine-tuning이라고 함
3) ELMO(Embedding from Language Models)
- character-level CNN
입력된 문자들 간의 관계 파악, 임베딩 벡터로 변환
- character level로 해당 character의 유니코드 id를 입력 받음
- 스페셜 토큰 (<\BOW>, <\EOW>)에 해당하는 유니코드를 앞뒤로 붙여줌
- look-up table
- feature map, max-pooling
- bidirectional LSTM
주어진 입력 다음에 올 단어들을 예측
- 양방향 학습: 학습 시간이 늘어나는 대신 성능은 좋음
- ELMo는 순방향과 역방향의 벡터를 합치거나 더하지 않고 독립된 모델처럼 행동
- ELMO 임베딩 레이어
구하고자 하는 토큰에 대한 각 층의 출력값을 가중합한 것
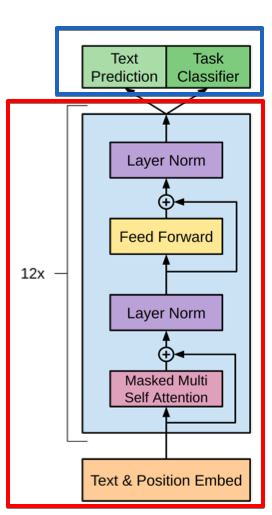
4) GPT(Generative Pre-Training Transformer)
트랜스포머의 decoder 구조만을 이용해 만든 네트워크
출처
1. Embedding - 빨간색 박스
BPE(Byte-pair Encoding): 모든 단어를 문자들의 집합으로 취급, 자주 등장하는 문자 쌍을 합치는 subword tokenization, oov 문제 해결 가능
- Masked Multi-Head Attention
트랜스포머에게 자기회귀적(Autoregressive)인 특성을 부여하기 위해 만든 장치
언어 모델과 같은 구조
Text Prediction & Text classification: finetuning downstream task (Supervised Learning)
파란색 부분
Input Transformation
classification, entailment 등 다양한 문제를 풀기 위해 input을 변형시키는 것
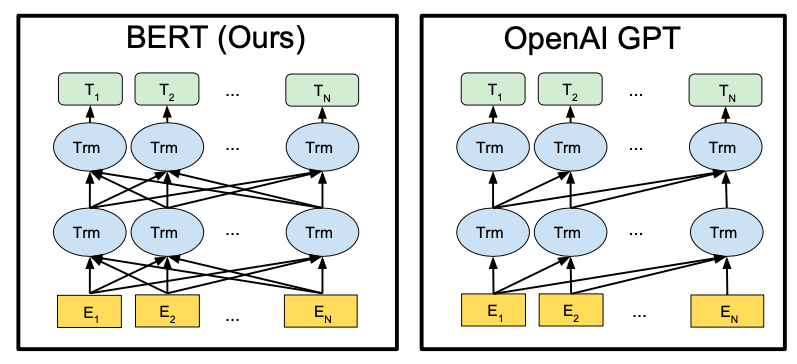
5) BERT(Bidirectional Encoder Representations from Transformers)
출처
트랜스포머의 encoder만을 이용한 모델
구조
- Transformer Encoder Block
- embedding
- token embedding
- segment embedding
- position embedding
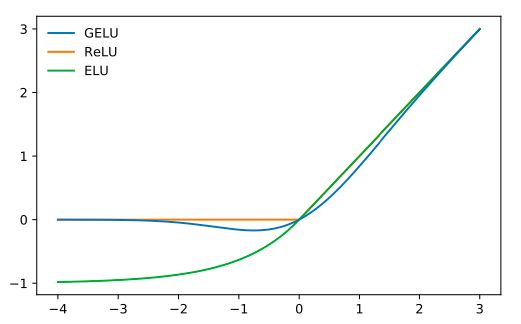
- Activation Function(활성화 함수) : GELU
출처
BERT의 학습
- Masked LM (MLM)
input sequence의 순서와 관계없이 문장의 전체를 볼 수 있음 (word2vec의 CBOW와 비슷) - Next Sentence Prediction (NSP)
다음 문장 확인하기, 문장과 문장 간의 관계 확인 - Fine-tuning Task
2. 회고
Going deeper 마지막 노드가 시작됐다. 아직 거기까지 가려면 멀었지만.. 아마 주말까지 15번 노드까진 할 수 있을 거 같다. NLP를 선택하긴 했는데 진짜 아는 게 없는 것 같아서 큰일이다.

🐬 파이썬 / 인공지능 / 머신러닝