1. 개념 정리
1) 신경망 기계 번역 이전
- 규칙 기반 기계 번역(RBMT, Rule-Based Machine Translation)
- 경우의 수를 직접 정의해주는 방식
- 한계: 규칙에 없는 문장은 번역 불가, 규칙을 정하는 과정에서 드는 비용이 큼
- 통계적 기계 번역(SMT Statistical Machine Translation)
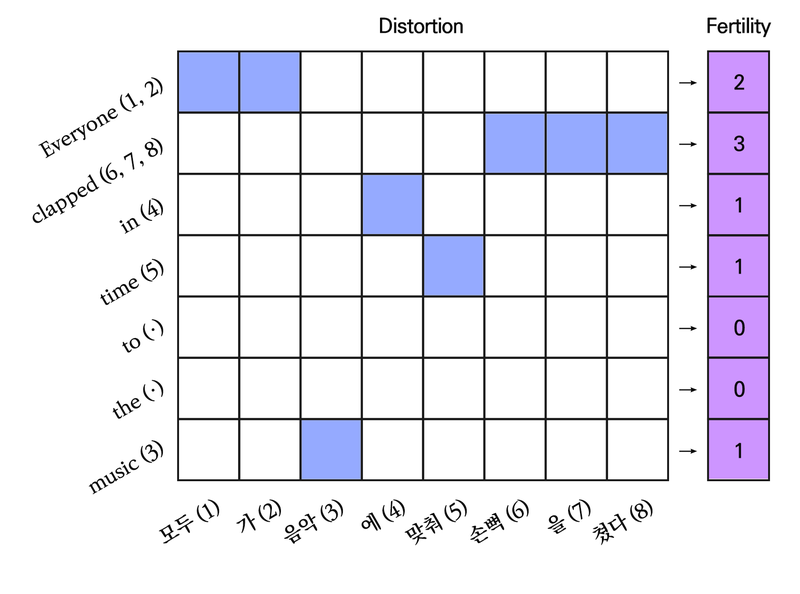
- 정렬: 원문-번역문 간의 매핑 관계를 추가로 고려해야함
- Fertility, Distortion
- 장점: 규칙 기반 모델에 비해 비용이 적게 든다. 많은 데이터가 확보될 수록 유연한 문장 생성이 가능하다.
- 한계
- 한 번도 본 적 없는 문장을 생성할 수 없다.
- 문장의 어순에 대한 고려가 없어 어색한 문장이 생성될 수 있다.
- 희소문제: 훈련 데이터에 목표하는 문장이 없을 경우 올바른 문장이라도 확률이 0으로 정의되는 문제
2) 문장 생성 방법
- Greedy Decoding
- Beam Search: 지금 상황에서 가장 높은 확률을 갖는 Top-k 문장만 남기는 것
- Beam size: 클 수록 좋음
- Sampling: 자연어 처리 + 강화학습, 역번역
3) 자연어 처리에서의 Data Augmentation
- Lexical Substitution
어휘 대체
- 동의어 기반 대체
- embedding 활용 대체
- TF-IDF
4) Back Translation
-
Dummy Source Sentence: encoder에 null 토큰을 넣지만 parameter는 freeze, dummy 값에 대한 학습은 하지 않음. decoder 에만 새 문장을 추가해 학습을 시키는 것.
-
Synthetic Source Sentence (Back Translation)
target sentence를 보고 인공적인 source sentence를 만드는 방법
5) Random Noise Injection
- 오타 노이즈 추가
- 공백 노이즈 추가
- 랜덤 유의어 추가
6) BLEU(Bilingual Evaluation Understudy) Score
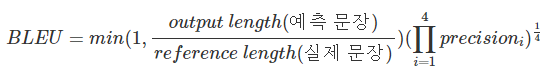
번역 평가 지표
7) 챗봇
- 고려해야할 사항
- 0.2초 이내 답변
- 특정 시공간에 의해 결정되는 질문
- 페르소나
2. 회고
처음 내용은 잘 이해가 안되다가 뒤에 나온 내용은 실제 비즈니스 환경에서 어떤 식으로 활용해야하는지에 관해 조금 연관이 되어 있어서 좀 더 와닿는 느낌이었다. 다음 실습은 챗봇 만들기일텐데 벌써 두렵다.

🐬 파이썬 / 인공지능 / 머신러닝