1. 개념 정리
노드 4번
1) F1-score
- classification report에서 특정값만 출력하고 싶은 경우
- output_dict=True를 설정한 뒤 키를 이용해 찾으면 됨
노드 5번
1) DTM
- BoW 전처리: 불필요한 단어 제거, 표현은 다르지만 같은 단어 통합
- 희소벡터: 대부분의 값이 0인 벡터
- 문서 or 단어의 수 증가 = 희소문제 증가
- 단어장: 중복 카운트 배제한 단어들의 집합
2) TF-IDF
- 불용어를 처리하기 위한 방법
- ex) 자주 사용되지만 의미가 없는 the와 같은 단어를 처리하기 위해 단어마다 가중치를 다르게 주는 방법이 등장함
DTM, TF-IDF 공통점, 차이점
1. 공통점
- 문서 벡터 크기 = 단어장의 크기
- 희소벡터
- 차이점
- 가중치 부여 여부
3) 원-핫 인코딩
from tensorflow.keras.preprocessing.text import Tokenizer
from tensorflow.keras.utils import to_categorical4) 희소벡터의 문제점
-
차원의 저주
출처
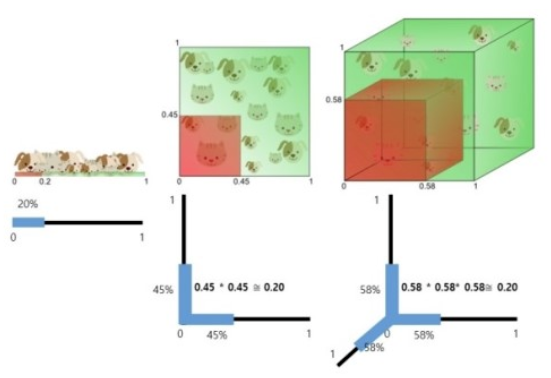
정보의 밀도가 작아짐 -
단어 벡터 간 유사도 구할 수 없음
-
대안: 워드 임베딩
5) 워드 임베딩
- 방식
벡터의 길이를 일정하게 정해 한 단어를 벡터로 변환함✔✔✔🤔 밀집벡터
출처: 아이펠 노드 그런데 그 벡터의 길이를 일정하게 정해줍니다. 더 많은 단어가 있다고 해서 벡터의 길이가 길어지지 않습니다. 여기서 일반적으로 벡터의 길이가 단어장 크기보다 매우 작기 때문에 각 벡터 값에 정보가 축약되어야 하고 결국 밀집 벡터(dense vector) 가 됩니다.
- 벡터 길이가 길어지지 않는다 = embedding을 할 경우가 저차원
- 특징
- 단어 사이의 관계, 문장에서의 단어가 갖는 특징을 수식으로 나타냄
6) Word2Vec
-
핵심 아이디어
분포가설: 주변 단어를 보면 그 단어가 어떤 단어인지 알 수 있다는 생각에서 비롯됨.
= 비슷한 문맥 상에서 함께 등장하는 경향이 뚜렷한 단어들은 비슷한 의미를 가진다. -
CBoW (Continuous Bag of words)
출처
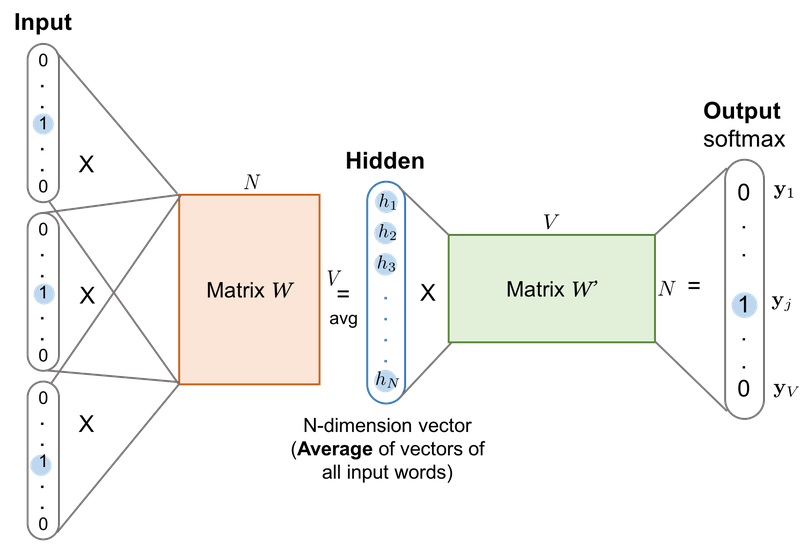
- center word: 예측할 단어
- context word: 주변 단어
- window: center word를 위해 앞, 뒤로 몇 개의 단어를 볼 지 정한 범위
- ex) window 크기가 m일 때 2m 개의 단어 참고
sliding window

- ex) window 크기가 m일 때 2m 개의 단어 참고
- 구조: 입력층, 은닉층, 출력층(인공신경망) ⇒ shallow Neural Network
- 은닉층은 투사층이라고도 한다. (활성화 함수 없음, 단순히 가중치 행렬과의 곱셈만 수행하기 때문)
- Skip-gram
출처
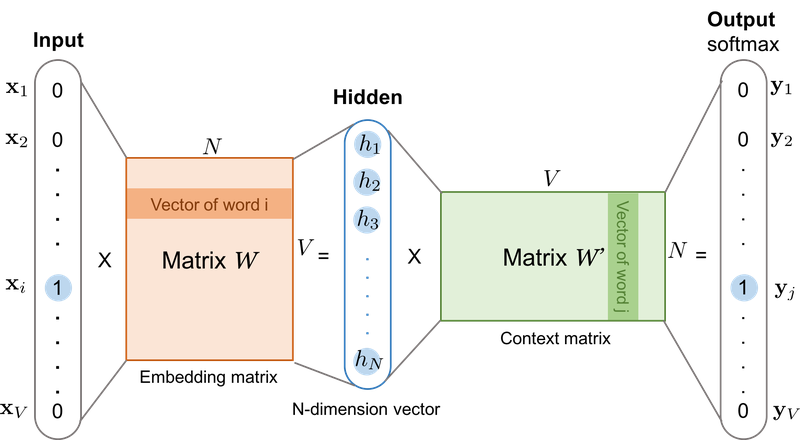
-
은닉층에서 다수의 벡터의 덧셈과 평균을 구하는 과정이 없어짐
-
Negative Sampling
✔✔✔🤔
다중 클래스 분류 문제를 시그모이드 함수를 이용한 이진 분류 문제로 변경함
⇒ 관련있으면 1을 라벨링. 관련 없는 단어를 무작위로 가져와 0을 라벨링함.이전 변경 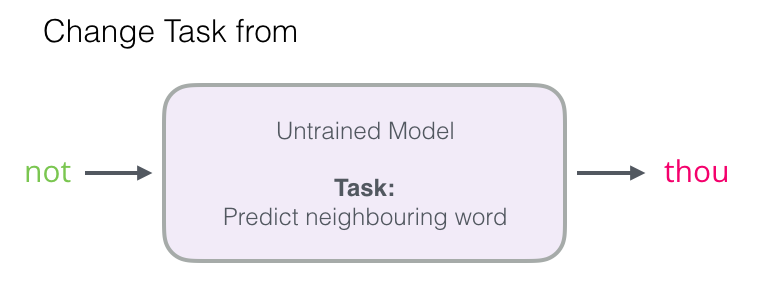

중심단어, 주변 단어를 입력값으로 받음. 해당 쌍이 positive인지 negative인지 확인함
7) FastText
- 방식
- 문자 단위 n-gram(character level n-gram, n만큼 단어를 분리, 범위로 지정 가능)표현을 학습한다.
- 내부 단어(subwords) 학습
ex) partial, n = 3인 경우
<pa, art, rti, tia, ial, al>, <partial>
- 특징
오타에 robust함
8) ✔✔✔🤔 GloVe
스탠포드 대학에서 개발한 워드 임베딩 방법론
카운트 기반의 방법론 + 예측 기반의 방법론(손실 함수를 통해 모델을 학습시키기 때문)
출처
1. 특징
- 카운트 기반, 예측 기반 두 가지 방법 모두 이용
- 한계
OOV
2. 회고
어제 진행하던 노드를 마무리 하고 진행했다. 처음 배우는 개념들이라 다 알고 넘어가자는 생각보다는 단어 자체에 익숙해지는 걸 목표로 하고 있는데 주말을 이용해서 지속적인 복습을 해야할 거 같다. 그리고 마지막에 나온 GloVe는 이해가 안돼서 일단 표시만 해두고 넘어갔다. 중요한 개념이고 다시 활용하게 된다면 나중에라도 나오겠지 하는 생각이다..

🐬 파이썬 / 인공지능 / 머신러닝