1. 개념 정리
1) Bag of Words
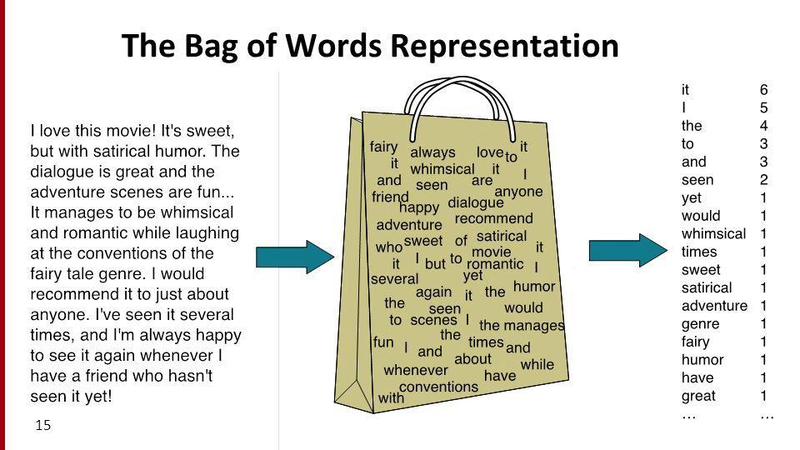
1. 한 문서의 텍스트를 단어 단위로 토큰화
2. 단어를 무작위로 섞어 순서를 무시하지만 단어의 등장 빈도수를 저장
3. 한계
BoW = {"too":1, "Mary":1, "movies":2, "John":1, "watch":1, "likes":2, "to":1}
BoW1 = {"John":1, "likes":2, "to":1, "watch":1, "movies":2, "Mary":1, "too":1}순서를 무시하기 때문에 위와 같은 두 사례를 같은 경우라고 판단.
어순에 따라 달라지는 의미를 반영하지 못함.
2) DTM (Document-Term Matrix)
- Bag of Words를 하나의 행렬로 구현한 것 = 여러 문서를 이용하며, 각 문서에 등장한 단어의 빈도수를 하나의 행렬로 통합함.
- 행 = 문서 / 열 = 단어 (반대의 경우는 TDM이라고 칭함.)
- 한계
- 저장 공간 낭비(+차원의 저주): 이용하는 문서, 단어의 수가 늘어날 수록 행, 열의 대부분 값이 0을 가지게 됨.
- 단어 빈도에 집중하는 자체의 문제: 두 문서를 비교할 때 관사가 같은 수만큼 나왔다고 해서 유사한 문서라고 보긴 어려울 것. 즉, 중요하지 않은 단어의 빈도수가 유사하게 나올 경우에도 두 문서가 유사하다는 판단을 내릴 수 있다.
3) TF-IDF (Term Frequency-Inverse Document Frequency)

출처
log항이 IDF에 해당함
- 단어 빈도-역문서빈도(문서 상 빈도의 역수)
- 불용어처럼 중요도가 낮지만 등장 빈도수가 높은 단어들이 노이즈가 되는 현상을 완화
- DTM을 만든 뒤에 TF-IDF 가중치를 여기에 적용
- 한계
- DTM보다 성능이 떨어짐
4) LSA (Latent Semantic Analysis)
- 특정 단어(의 의미)와 연관된 문서 집합을 찾고 싶을 때
- 단어의 의미, 주제를 알고 싶을 때 사용 가능
- 잠재 의미 분석: 전체 코퍼스에서 문서 속 단어 사이 관계를 찾아내는 Nlp 정보 검색 기술
- 단어와 단어, 문서와 문서, 단어와 문서 사이 의미적 유사성 점수 계산 가능
- 필요 개념:
✔✔✔🤔 특잇값 분해
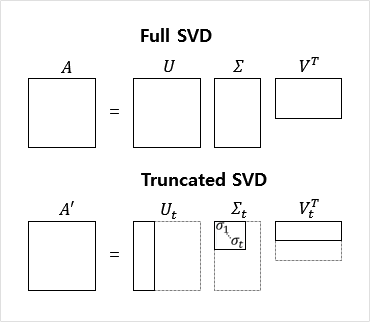
- LSA는 DTM이나 TF-IDF 행렬 등에 Truncated SVD를 수행함
- 분해를 통해 얻은 행렬 3개는 다음과 같음
- 문서들과 관련한 의미를 표현한 행렬
- 단어와 관련한 의미를 표현한 행렬
- 각 의미의 중요도를 표현한 행렬
행렬의 k열은 전체 코퍼스에서 얻은 k개의 주요 topic라고 간주 가능
- 분해를 통해 얻은 행렬 3개는 다음과 같음
5) LDA (Latent Dirichlet Allocation)
- 잠재 디리클레 할당
- 문서에서 여러 토픽을 담고 있으며, 이 토픽은 확률 분포에 기반해 단어를 생성한다고 가정.
- 2의 과정을 역추적하는 것.
- 특정 주제에서 특정 단어가 나타날 확률을 추정
✔✔✔🤔 LSA와 LDA
LSA는 DTM을 차원 축소한 후, 축소 차원에서 거리가 가까운 단어들을 토픽으로 묶는 반면에, LDA는 특정 토픽에 단어가 존재할 확률과 문서에 특정 토픽이 존재할 확률을 결합 확률로 추정하여 토픽을 추출
6) 형태소 분석기
- 필요성
- 한국어와 같은 교착어를 토큰화하기 위함
- 한계
- 등록된 단어를 기준으로 형태소를 분류하기 때문에, 신생어를 인식하기 어려움
- soynlp
- 품사 태깅, 형태소 분석 등 지원하는 한국어 형태소 분석기
- 비지도학습 형태소 분석기
- 응집 확률

- 문자열을 문자 단위로 분리해 내부 문자열을 만드는 과정 속에서 왼쪽부터 순서대로 문자를 추가해 각 문자열이 주어졌을 때 다음 문자가 나올 확률을 계산해 누적 곱을 한 값
- 해당 값이 높을 수록 전체 코퍼스 상에서 해당 문자열 시퀀스가 하나의 단어로 등장할 가능성이 높음
- 문자열을 문자 단위로 분리해 내부 문자열을 만드는 과정 속에서 왼쪽부터 순서대로 문자를 추가해 각 문자열이 주어졌을 때 다음 문자가 나올 확률을 계산해 누적 곱을 한 값
2. 회고
텍스트 벡터화에 대해서 배웠다. 수학적 개념이 많이 들어갔는데 그래도 행렬 기본을 했다고 어느 정도 알아들을 순 있었다. 아직 갈 길이 멀지만.. 어느 부분이 부족한지 확실하게 정리하지 않으니가 너무 모호하게 놓치고 있는게 많은 기분이어서 정리할 건 정리하고 어떤 식으로 채울 수 있을지 생각해봐야겠다.

🐬 파이썬 / 인공지능 / 머신러닝