1. 추천 시스템 입문
1) 원리
- 범주형 데이터를 다룸
ex) item - 영화의 장르, 드라마의 국적 등 / user - 유사도 계산
- 숫자 벡터로 변환한 뒤 계산함
- 범주형 데이터를 좌표 상에 나타내기 위해 숫자 벡터로 변환하는 과정을 거친다.
- 이때 좌표 상에서의 거리를 계산해 유사도를 표현함
- 유사도가 가까운/높은 제품을 추천한다.
2) 코사인 유사도
- 유사도를 계산하는 방법 중 가장 널리 알려진 방법
- 두 벡터 간의 코사인 값을 이용해 유사도를 판별함
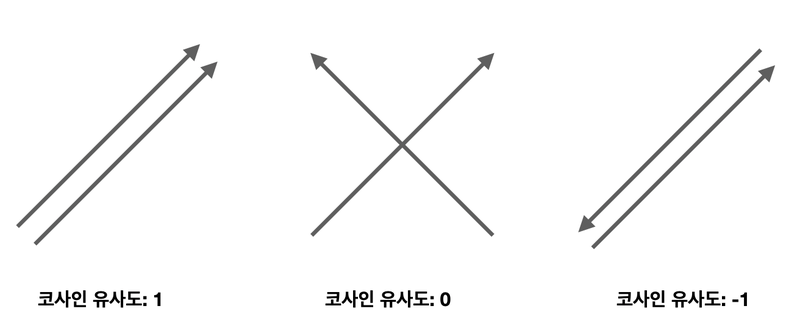
방향이 같을 경우 유사도 1, 90도일 경우 유사도 0, 180도일 경우 유사도 -1을 갖는다.
- 범위: -1~1
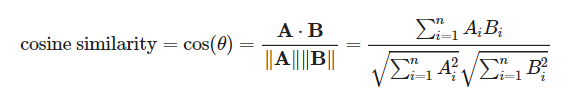
- 사이킷런 활용
from sklearn.metrics.pairwise import cosine_similarity
t1 = np.array([[1, 1, 1]])
t2 = np.array([[2, 0, 1]])
cosine_similarity(t1,t2)
>> array([[0.77459667]])유클리드 거리, 자카드 유사도, 피어슨 상관계수 등 다른 유사도 측정 방법도 존재
3) 추천 시스템의 종류
(1) 콘텐츠 기반 필터링(content based Filtering)
- 오직 콘텐츠의 내용을 기준으로 추천하는 방식
- 장르, 배우, 감독과 같은 영화의 정보를 영화의 특성(feature)로 취급해서 이 특성이 유사할 경우 유사한 콘텐츠라고 판단하는 식임.
(2) 협업 필터링
-
사용자의 과거 행동 양식(User Behavior) 데이터를 기반으로 추천하는 방식
ex)
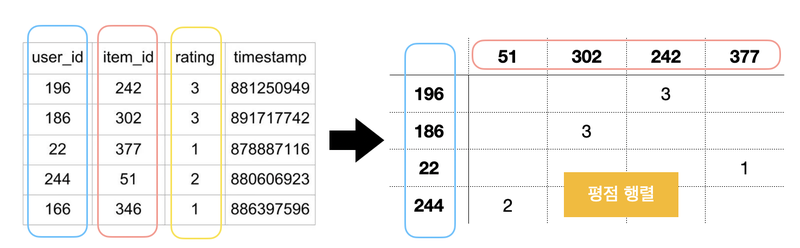
-
평점행렬: 사용자의 아이디, 사용자가 시청한 영화의 아이디, 별점, 평가한 시간을 위와 같은 행렬로 생성, 희소 행렬(sparse matrix)의 형태를 보임
-
유사도 추천 방식: 평점행렬의 유사도를 계산해 추천하는 방식, 사용자 기반과 아이템 기반 방식이 있음
사용자 기반: 비슷한 고객들이 구매한 상품을 기반으로 추천
아이템 기반: 비슷한 아이템을 구매한 다른 사람들이 고른 제품을 추천 -
행렬 인수분해: 잠재요인 분석
(3) 행렬 인수분해(matrix factorization)
- 잠재요인(latent factor) 협업 필터링이 이용하는 방식
- 분해 행렬을 이용할 시 추천될 대상을 쉽게 찾을 수 있음
- 추천 알고리즘에서의 파라미터 수가 줄어듦
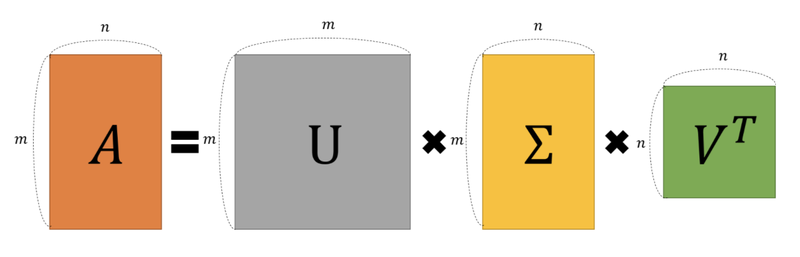
- SVD(Singular Vector Decomposition): 특잇값 분해
임의의 m*n 차원의 행렬 A에 대해 다음과 같이 분해할 수 있음
- A: m*n rectangular matrix
- U: m*m orthogonal matrix
- Σ: m*n diagonal matrix
- V: n*n orthogonal matrix
- Orthogonal Matrix(직교행렬)
- 직교 벡터: 벡터 사이의 각도가 90를 이루는 벡터 = 반드시 한 쌍 이상의 벡터로 정의되어야 함
- 모든 column vector가 자신을 제외한 나머지 column vectors과 직교이면서 크기가 1인 단위 벡터로 구성된 행렬
- orthonormal vector를 행렬에 집어넣은 것과 같음
U가 orthogonal matrix일 때
- Diagonal matrix
행렬의 대각 성분을 제외한 나머지 원소 값이 0
- 기하학적 의미
- 정보복원을 위해 사용: 중요한 정보만 부분 복원해 사용할 경우 용량은 줄이고 보여주고자 하는 내용은 유지시킬 수 있음

- SVD를 평가행렬에 적용해 잠재요인을 분석하는 방식을 도식화한 것
- R: 사용자와 아이템 사이 행렬
- P: 사용자와 잠재요인 사이 행렬
- Q: 아이템과 잠재요인 사이 행렬 ⇒ 전치행렬로 나타냄
잠재요인이란?
사람이 평점을 매기는 요인. 굉장히 주관적이기 때문에 이를 잠재요인으로 취급한 후, SVD 기법을 이용해 분해. 그리고 분해된 결과를 다시 합치는 방식으로 영화 평점의 이유를 벡터화 하고 이 값을 기반으로 해 추천하는 것.
참고
- 추천 시스템에서 사용하는 행렬 인수분해
- LSA(latent semantic analysis)
- SVD와의 차이: 차원 축소 후 행렬을 분해하기 때문에, 분해 뒤 복원 시 SVD처럼 완전 같은 행렬이 반환되지 않음.
2. CS231n Lecture 10 정리
참고
1) Recurrent Neural Networks
- 순환신경망의 의미
- 순서가 있는 데이터(sequence data)를 학습하기 위한 인공신경망
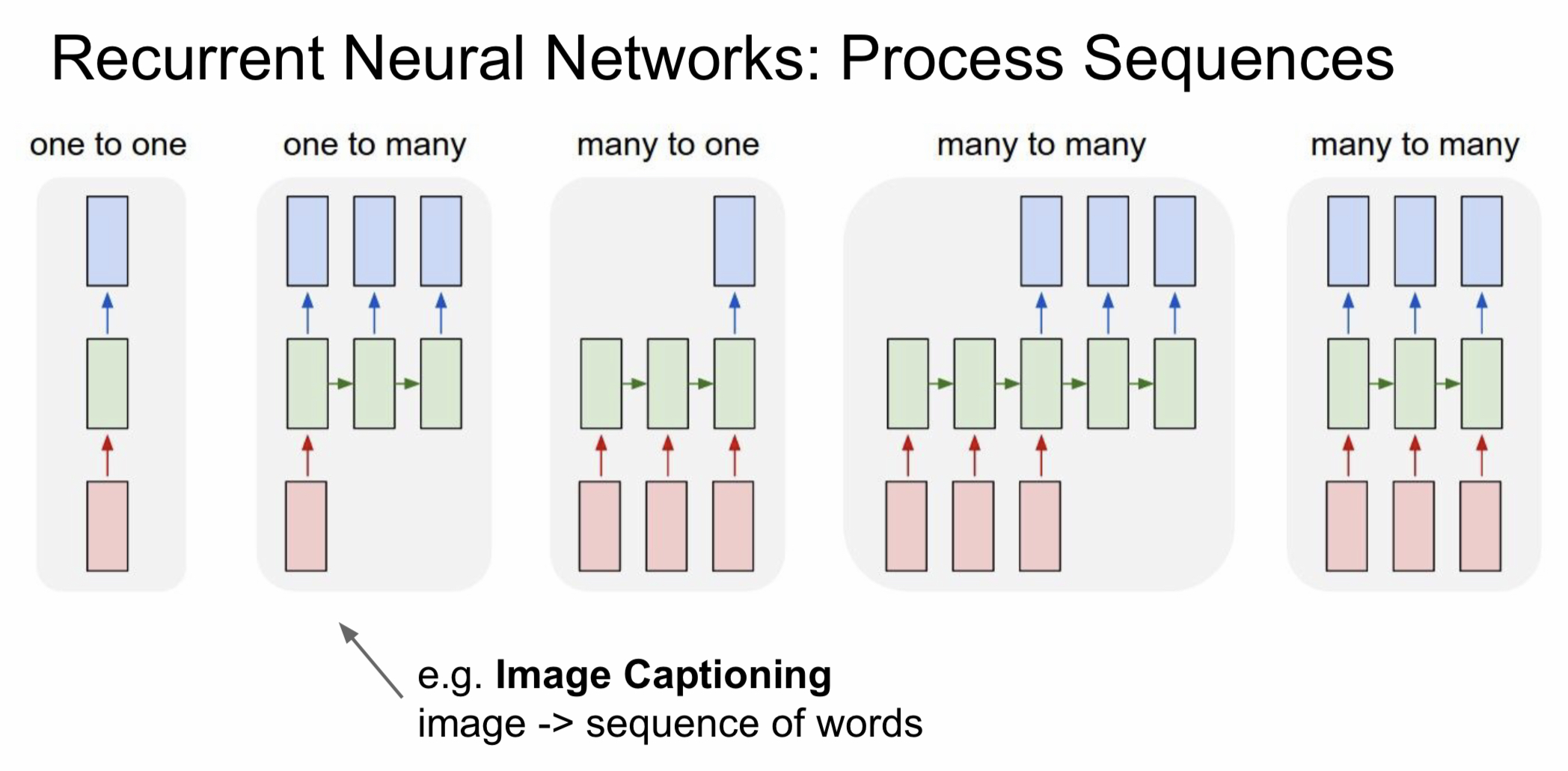
2. 연결 구조
| 연결 구조 | 입력 개수 | 출력 개수 | 대표적인 예시 |
|---|---|---|---|
| one-to-one | 1 | 1 | Vanilla Neural Network(가장 기본적인 네트워크) |
| one-to-many | 1 | 여러 개 | 이미지 캡셔닝(이미지를 글로 설명하는 것) - 이미지가 인풋(1), 이미지 내부의 물체를 여러 단어로 변환해 설명(여러 개) |
| many-to-one | 여러 개 | 1 | 감정 분류(sentiment classification) |
| many-to-many | 여러 개 | 여러 개 | 번역, 비디오 분류 |
- 기본 원리
- 모든 계산 단계에서 재귀식/점화식(recurrence formula)을 적용함
- 점화식: 이웃하는 두 개의 항 사이에 성립하는 관계를 나타내는 식
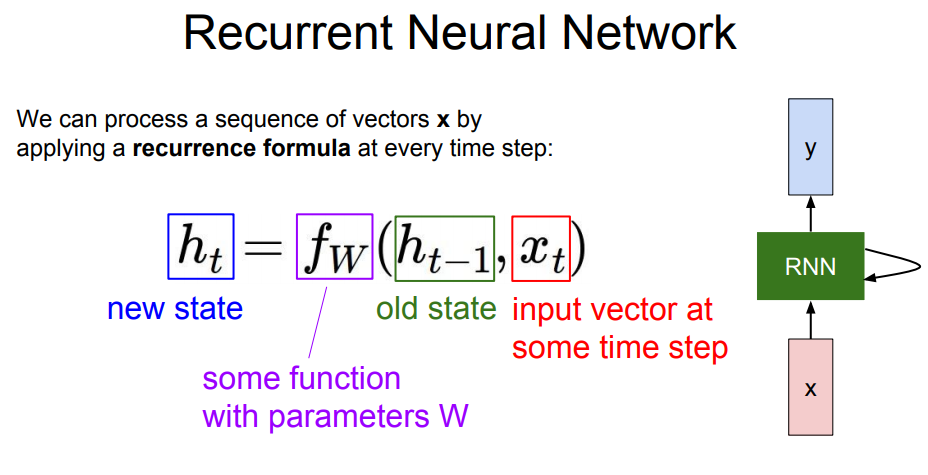
에 대한 점화식을 나타냄 - (t시점의 상태)를 이전 상태인 과 t 시점의 input vector인 를 이용해 구할 수 있음
- 점화식: 이웃하는 두 개의 항 사이에 성립하는 관계를 나타내는 식
- 모든 RNN에서는 동일한 function과 파라미터 w를 사용해야함.
- tanh의 역할

- 비선형성을 유지하기 위해 사용. 선형함수로만 계산할 시엔 층을 거치면서 생기는 변화가 크지 않음. RNN의 gradient를 최대한 오래 유지시키기 위해 사용하는 것.
- 의 경우 h와 h사이의 파라미터, 는 x와 h 사이의 파라미터, 는 h와 y 사이 파라미터라는 의미이다.
- 위의 파라미터는 모든 타임 스텝에서 동일한 값을 가진다.
- 계산 과정
a. many to many
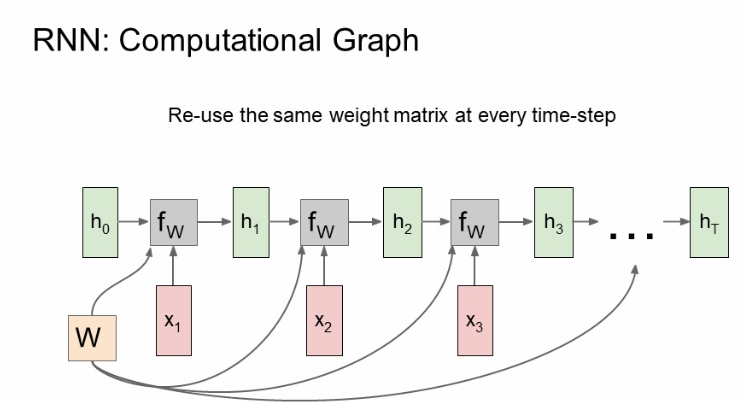
-
동일한 가중치 행렬 W가 사용됨
-
H, x는 계속 달라짐
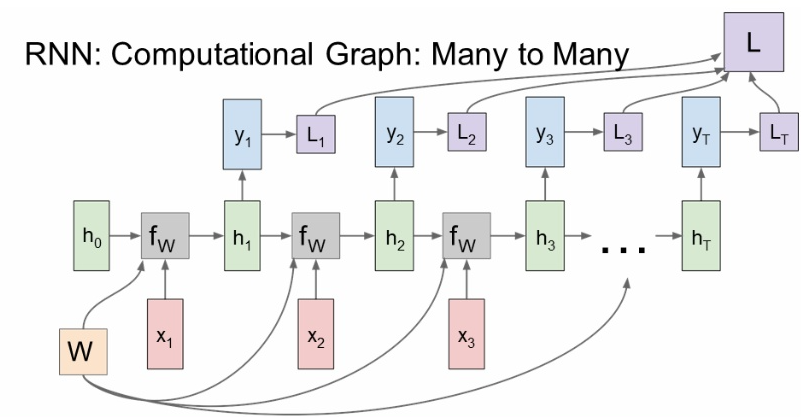
-
각 단계에서 구한 loss를 이용해 최종 loss를 계산
b. many to one
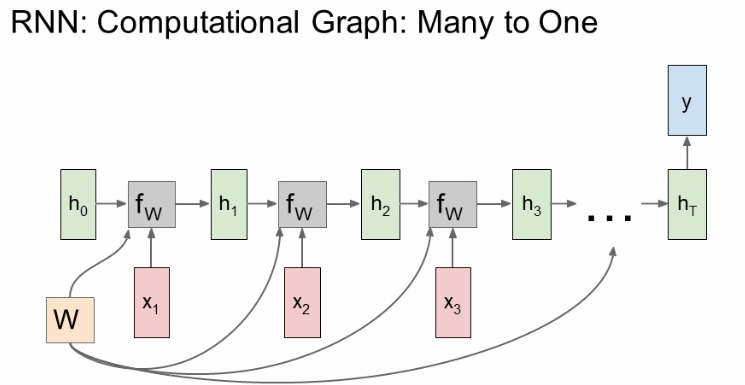
-
최종 hidden state에서만 결과값이 출력 됨
c. one to many
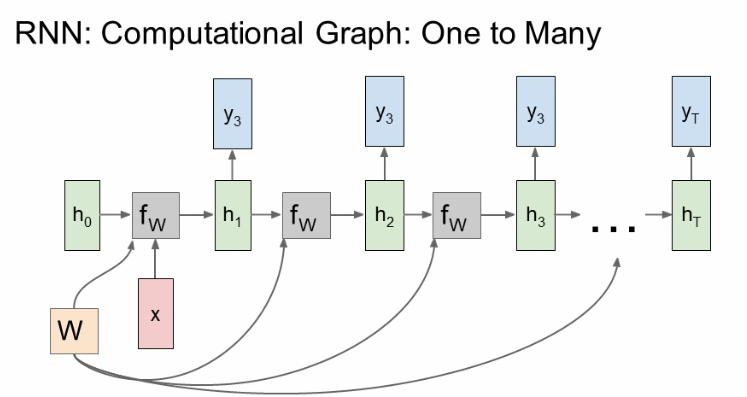
- 입력은 고정, 출력은 가변적
- 고정입력은 initial hidden state를 초기화시키는 용도로 사용함.
- Sequence to Sequence
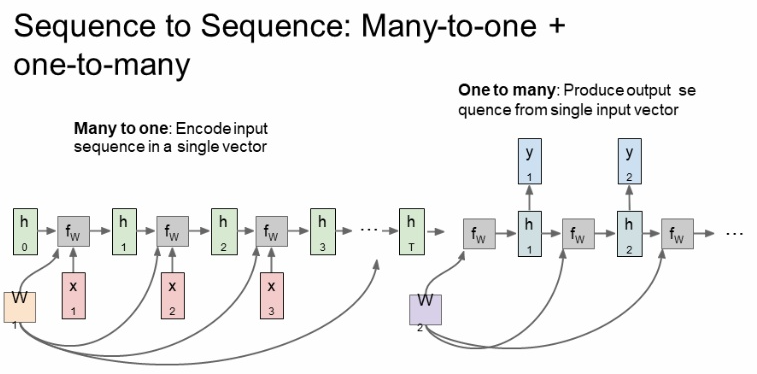
- 번역기 같은 데에 이용 = 가변 입력 + 가변 출력
- many to one과 one to many의 결합으로 볼 수 있음
- 두 개의 스테이지: encoder(가변입력을 받음, 마지막 hidden state를 통해 전체 sentence 요약) + decoder(가변출력)
2) RNN example as Character-level language model
-
hello라는 sequence data가 주어졌을 경우
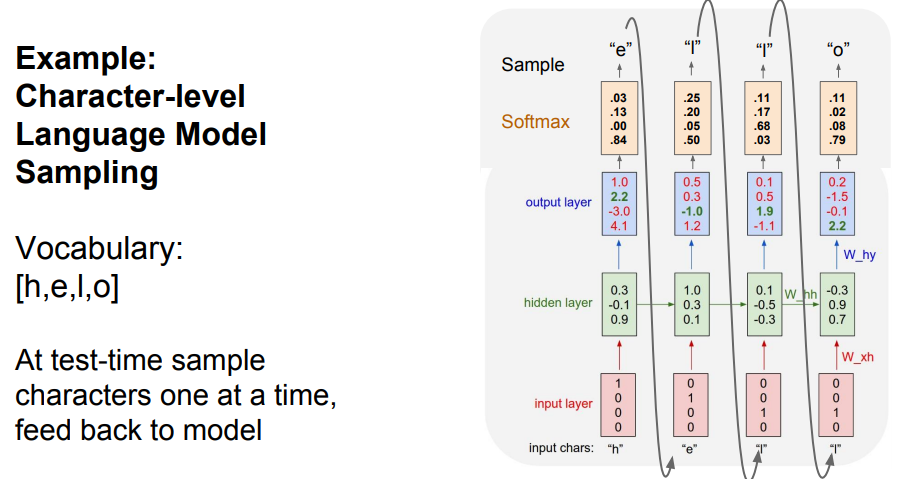
training 이전 - 알파벳 4개(h,e,l,o)를 원-핫 인코딩을 통해 벡터화, vocabulary에 저장.
- input으로 h를 넣었을 때 e가 출력됨. e를 넣으면 l 이렇게 순차적으로 출력될 것.
- input: h, e, l , l
- output: e, l, l, o
- vanilla 이므로 tanh 사용함training time - training sequence로 hello의 각 알파벳을 입력.
> h의 아웃풋을 보면
- 모델 상에서 e를 예측하지 않고 o를 예측한 것을 볼 수 있음
- output layer를 보면 [1.0 2.2 -3.0 4.1]인데 가장 끝 값이 높으므로 원-핫 인코딩을 하면 [0 0 0 1]이 된다. 이는 vocabulary 상에서 o를 의미한다.
- 위와 같이 학습을 진행하면서 예상값과 다를 경우엔 loss 값이 커질 것. 이 loss 값을 줄이는 방향으로 학습을 계속할 것임.test time 모델에게 h가 주어질 경우, vocabulary의 모든 알파벳에 대한 score를 output layer가 출력할 것. 이 score 값을 다음 문자 선택에 이용함. softmax? test time에서 계산한 score를 확률분포로 표현하기 위해 사용, output layer에서 o의 확률이 제일 높았지만 최종적으로는 e가 선택됨 (운이 좋았다고 표현) e를 다시 input해서 반복함.
실제로 score와 확률분포 둘 다 활용할 수는 있음. 하지만 확률 분포를 사용하는 쪽이 모델에서의 다양성을 얻을 수 있기 때문에 확률분포를 사용.
- backpropagation through time
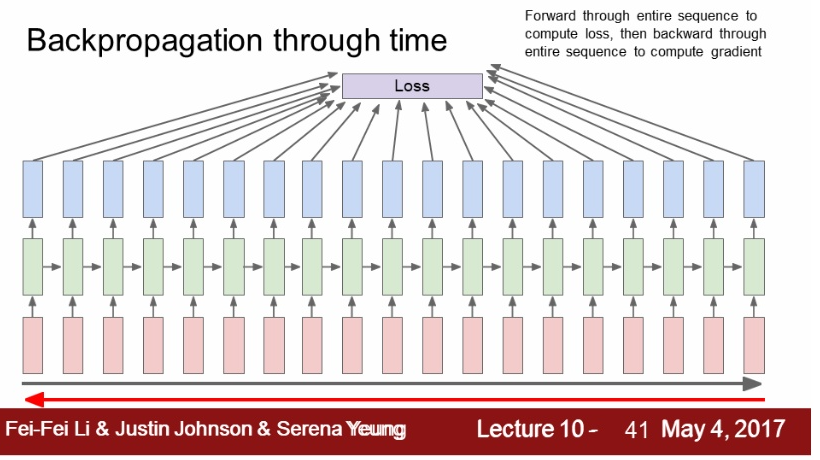
- backpropagation through time: 1.에서 학습을 진행한 모델의 경우 매번 출력값이 나오는데, 이 출력값의 loss를 계산해서 final loss를 얻는 것
- back pass에서 전체 sequence를 가지고 loss를 계산할 경우, 모든 sequence를 한 번 훑고 나서야 gradient를 1회 계산하기 때문에 계산이 매우 비효율적임.
- 그렇기 때문에 truncated backpropagation을 사용함.
- mini batch와 비슷한 과정: train time에 하나의 스텝을 일정한 단위로 자른 후, 그 단위만큼 forword 계산을 통해 loss를 계산. 이를 토대로 gradient step을 진행하며, 이 과정을 반복함
- Searching for interpretable cells
 |  |
|---|---|
| 아무런 패턴이 안보임 | 따옴표를 기준으로 패턴을 인식 |
- 그외) 문장의 길이, if 뒤에 쓰인 조건문, 주석문, 들여쓰기에 따라 파악
- Image Captioning
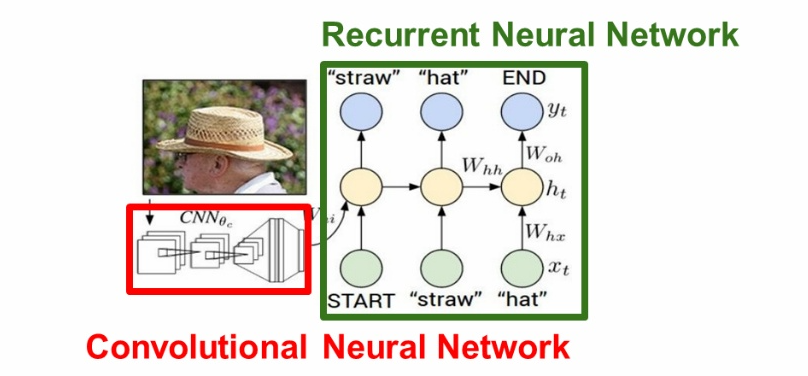
- CNN + RNN, 입력은 이미지지만 출력은 자연어
- 과정
- 이미지가 input data로 들어감
- CNN을 지나면서 해당 이미지에 대한 요약된 벡터 값을 받음. 이때 마지막의 softmax score는 사용하지 않음. 그 전의 fc-4096 벡터를 출력으로 하며, 이를 이용해 전체 이미지 정보를 요약함.
- 전 단계에서 받은 값을 Vanilla RNN 식에 추가해 계산. 처음 x0값은 START라는 토큰 값과 함께 주어짐. 모든 단어는 RNN을 통해 출력됨.
- 모든 출력을 마친 후에는 END 토큰으로 종료. 이미지 캡셔닝에선 마지막 단계에 END 토큰을 출력하는 것 또한 학습시켜야함.
- Attention

- 이미지의 다양한 부분을 집중해서 보는 것
- 원리
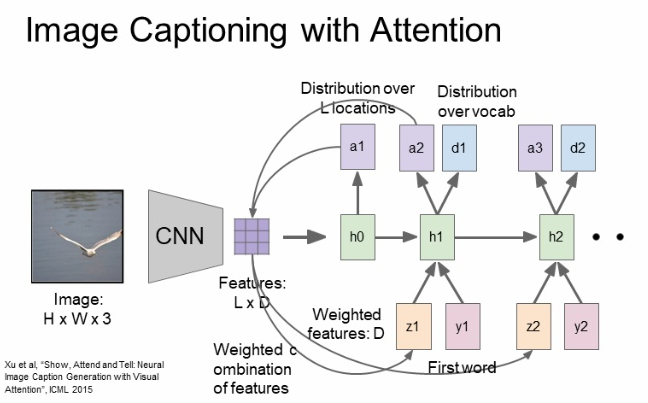
- 기존의 계산 + 캡션을 할 때 집중할 위치도 계산 함
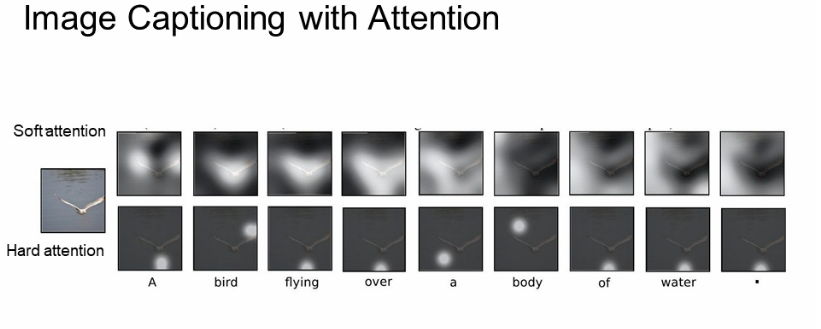
- train이 끝나면 caption 생성을 위해 이미지의 attention을 이동시킴
- 기존의 계산 + 캡션을 할 때 집중할 위치도 계산 함
3) Long-Short Term Memory (LSTM)
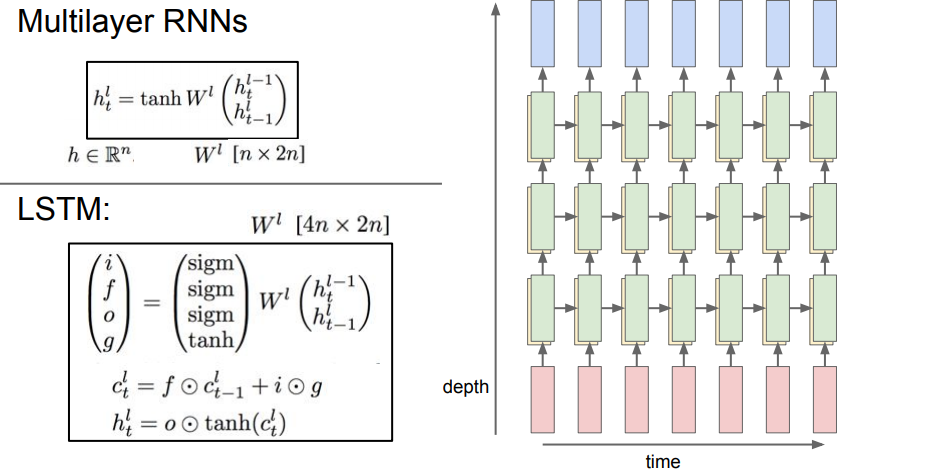
- 여러 개의 hidden layer: 이전과의 차이
- RNN의 장기 의존성 문제(vanishing gradient, 은닉층의 과거 정보가 마지막 단계까지 전달되지 못하는 현상)를 해결하는 것이 LSTM
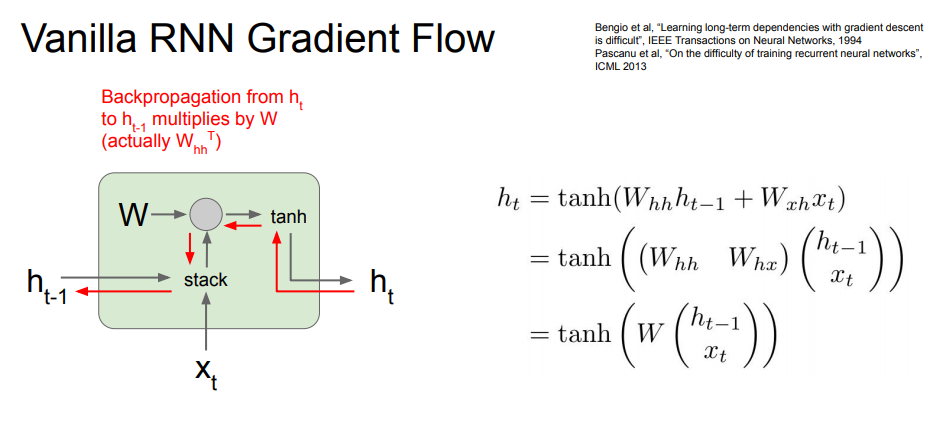
- RNN에서 backpropagation을 통해 weight 성능을 업데이트 하는 과정
- 빨간색 경로: tanh gate ⇒ mul gate 순으로 이동. mul gate에서는 transpose를 곱하게 됨
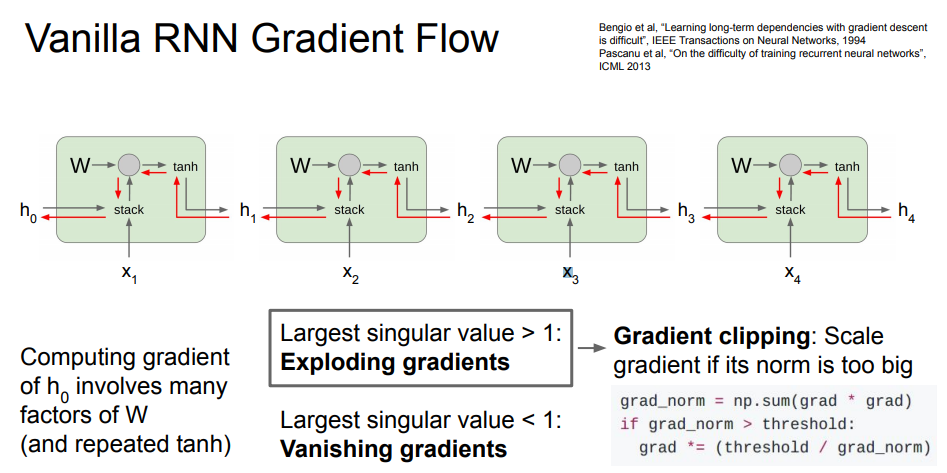
- 빨간색 경로: tanh gate ⇒ mul gate 순으로 이동. mul gate에서는 transpose를 곱하게 됨
- RNN의 문제
- backward pass 과정에서 동일한 RNN을 통과할 때마다 weight의 일부 값을 곱하게 됨
- 많은 가중치 행렬이 개입해 매우 비효율적
- 곱해지는 값이 너무 작으면 vanishing, 크면 exploding
- exploding: gradient clipping으로 방지 가능
- backward pass 과정에서 동일한 RNN을 통과할 때마다 weight의 일부 값을 곱하게 됨
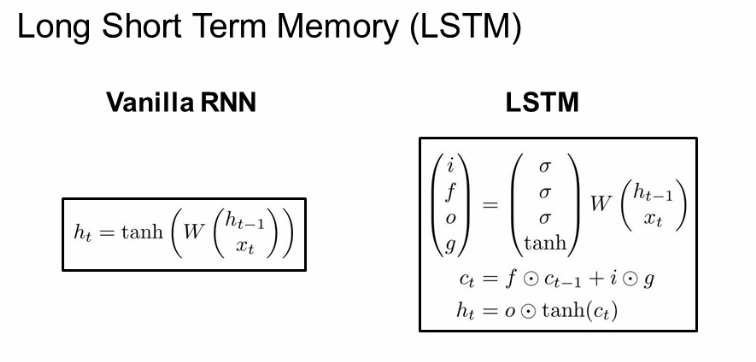
- LSTM
- RNN의 문제를 해결하기 위해 사용: 참고
- hidden state에 cell state를 추가한 구조: 라는 두 번째 벡터 존재
Gate
- input gate: 현재 정보를 얼마나 사용하는지에 관한 게이트
- forget gate: 이전 정보를 얼마나 잊을 지에 관한 게이트
- output gate: 얼마나 드러낼 것인가에 관한 게이트
- gate gate: input을 얼마나 포함시킬 것인지에 관한 게이트
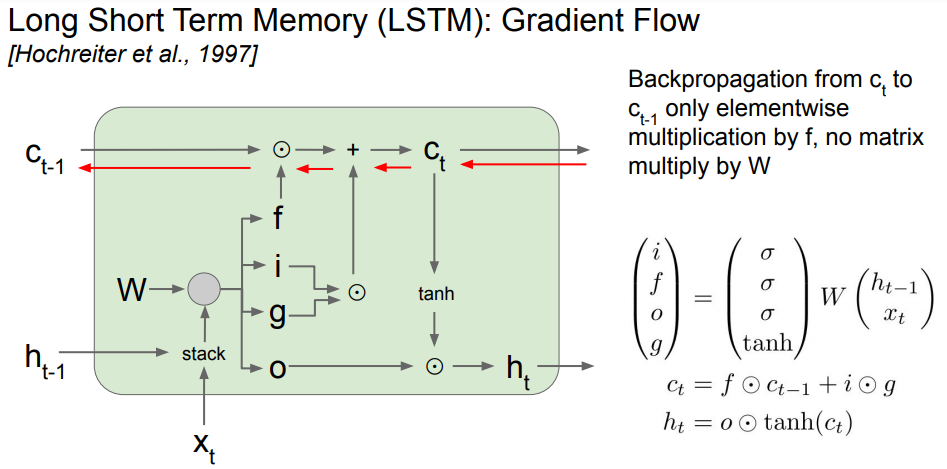
- 흐름 ✔✔✔🤔
- cell state를 활용하기 때문에 정보를 최대한 잃지 않으면서 gradient 값을 구할 수 있음(ResNEt과 유사)
수학
3. 회고
수학적인 개념이 많이 나와서 어려웠다. RNN은 벌써 세 번은 다뤄서 저번에 다 이해하고 왔다고 생각했는데 다시 보니까 이해 안가는 부분이 있더라. 그래서 이전에 적어둔 자료 찾아보는데 거기에도 내가 모르겠는 부분에 대한 설명은 없었다.. 누가 아는 게 많아질 수록 무지의 영역도 넓어진다고 했는데 그런 거였으면 좋겠다.. 수요일에 공부할 혼공머로 보충해봐야겠다.
