1. 딥러닝 실습
1) 필요한 개념
- 순환신경망 RNN
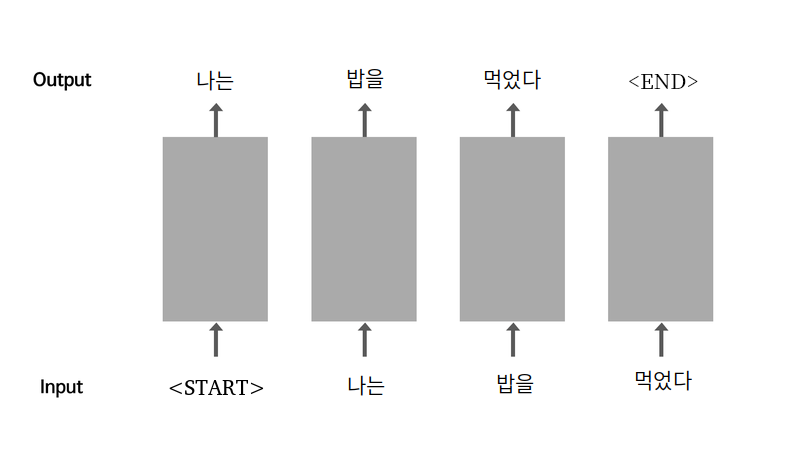
- 첫 번째부터 n번째까지 단어 시퀀스가 주어졌을 때 n번째 단어로 어떤 것이 올 지 예측하는 것
- 데이터 셋 구성 방법의 예) n-1번째까지의 단어 시퀀스가 x_train이 되고 n번째 단어가 y_train이 되도록 구성
- 언어 모델(Language Model)
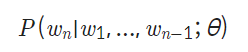
- θ: 파라미터
- 토큰화(Tokenize)
텍스트 분류 모델에서와 같이 텍스트 생성 모델에도 단어 사전을 만들게 되는데, 이때 문장을 일정한 기준으로 쪼갠다. 이를 토큰화라고 칭함.
2) 자연어 처리
-
소스 문장(Source Sentence)
모델의 입력이 되는 문장 -
타겟 문장(Target Sentence)
모델의 출력 문장 -
토큰화
딥러닝을 이용한 자연어 처리 입문
토큰화 할 때 텐서플로우의 Tokenizer와 pad_sequences를 사용. 토큰화가 완료되면 숫자 배열로 결과를 반환함. 각 숫자는 단어의 인덱스임 -
입출력
자연어처리 분야에서 모델의 입력이 되는 문장을 소스 문장(Source Sentence) , 정답 역할을 하게 될 모델의 출력 문장을 타겟 문장(Target Sentence) 라고 관례적으로 부릅니다. 각각 X_train, y_train 에 해당한다고 할 수 있겠죠?
그렇다면 우리는 위에서 만든 정제 함수를 통해 만든 데이터셋에서 토큰화를 진행한 후 끝 단어 를 없애면 소스 문장, 첫 단어 를 없애면 타겟 문장이 되겠죠? 이 정제 함수를 활용해서 아래와 같이 정제 데이터를 구축합니다!
- 데이터 전처리
순서
- 정규표현식을 이용한 corpus 생성
- tf.keras.preprocessing.text.Tokenizer를 이용해 corpus를 텐서로 변환
- tf.data.Dataset.from_tensor_slices()를 이용해 corpus 텐서를 tf.data.Dataset객체로 변환
✔✔✔🤔 사전의 길이와 num_words가 다른 이유
반환되는 사전에는 모든 단어가 포함이 되지만 이후에 texts_to_sequences 이런식으로 메소드를 사용할 때는 7000번 인덱스까지만 사용되고 그 7000개 안에 포함되지 않는 단어들은 로 반환 됨
- LMS에서 사용된 자연어 처리 모델의 구조
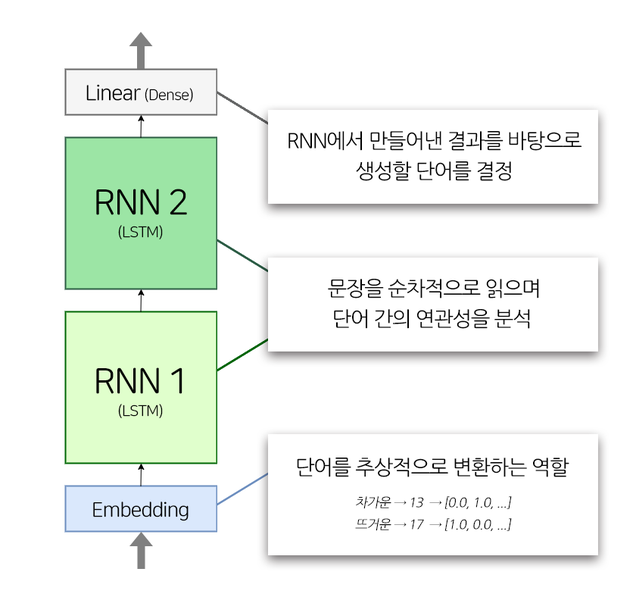
class TextGenerator(tf.keras.Model):
def __init__(self, vocab_size, embedding_size, hidden_size):
super().__init__()
self.embedding = tf.keras.layers.Embedding(vocab_size, embedding_size)
self.rnn_1 = tf.keras.layers.LSTM(hidden_size, return_sequences=True)
self.rnn_2 = tf.keras.layers.LSTM(hidden_size, return_sequences=True)
self.linear = tf.keras.layers.Dense(vocab_size)
def call(self, x):
out = self.embedding(x)
out = self.rnn_1(out)
out = self.rnn_2(out)
out = self.linear(out)
return out
embedding_size = 256
hidden_size = 1024
model = TextGenerator(tokenizer.num_words + 1, embedding_size , hidden_size)-
embedding_size: 워드 벡터의 차원수. 단어가 추상적으로 표현되는 크기. 값이 커질 수록 추상적인 특징을 더 잡아낼 수 있지만 데이터가 충분하지 않을 경우 혼란을 가중시킬 수 있음.
-
hidden_size: LSTM 레이어의 hidden state의 차원수. 모델이 얼마나 많은 일꾼을 둘 것인가로 이해하면 됨.
2. 회고
머신러닝 하면 아는 분야가 NLP 밖에 없었어서 막연히 NLP 분야로.. 파파고로.. 가고싶다 한 적 있었는데 오늘 해보니까 될까 싶다. 언어 학습시킬 때 정규표현식 쓰는 게 너무 ,, 싫다 마음에 걸린다.. 그래도 재미는 있긴 했는데 뭔가 확 와닿진 않는 거 같다. 오늘따라 fit 할 때 시간이 오래 걸려서 다른 할 일도 하고 그래서 그런지 다른 날에 비해 버겁진 않았다.
지금 생각으로는 이미지 분류 같은 거보단 상대적으로 시간이 덜 걸리고 쉬운 편에 속하지 않나 싶긴 한데, 한국어의 경우는 워낙 예외도 많고 기준점을 잡기 쉽지 않다고 하니 어떨지 모르겠다.
