1. 파이썬 개념 정리
1) 객체
Everything is an object
: 파이썬에서 모든 object는 변수로 할당되거나 함수의 인자로 넘길 수 있다는 의미
1. 변수 할당

4를 담는 정수형 객체를 생성. 변수는 이 객체를 가리키게 됨. 따라서 변수와 4의 id 값은 동일함.
2. 얕은 복사와 깊은 복사
| 얕은 복사 | 깊은 복사 | |
|---|---|---|
| 의미 | 원본 데이터는 그대로 두고, 참조하는 데이터의 id만을 복사 원본 객체의 주소를 복사 | 원본 데이터를 복사해 동일한 데이터가 생기는 것 원본 객체의 값을 복사 |
| 방법 | = copy.copy() | copy.deepcopy() |
2) 객체지향 프로그래밍
- 계층이 달라져도 데이터를 효율적으로 다룰 수 있는 방식
- 큰 프로그램을 효율적으로 설계 가능
cf) 절차지향 프로그래밍
- 데이터(변수)를 함수로 어떻게 처리를 해야할지에 주목
- 분산 환경에서 데이터 처리에 매우 효율적
3) 클래스
클래스는 상태와 동작을 갖는다.
1. 객체 인스턴스화
인스턴스를 할당했다고 표현, 클래스를 호출했다고 표현하기도 함
➕ 클래스, 함수 명명
- 클래스명 표기법: 카멜 케이스
- 카멜 케이스: 각 단어의 앞 글자를 대문자로 쓸 것.
- 예시: mycar —> MyCar
- 함수명 표기법: 스네이크 케이스
- 스네이크 케이스: 단어는 소문자로 쓰고 각 단어의 연결은 언더바(_)를 사용할 것
- 예시: mycar —> my_car
+) 클래스명은 주로 명사로, 함수명은 주로 동사로 명명
-
self
객체 안에서 self를 사용하면 인스턴스 객체의 고유한 속성을 나타낼 수 있음 클래스가 아닌 self, 즉 인스턴스화된 객체 자신의 속성을 나타냄 -
생성자
__init__
- 인스턴스 객체의 속성값을 초기화
- 인스턴스 생성 시 객체의 속성 지정 가능
✔✔✔🤔 클래스 변수와 인스턴스 변수
- 인스턴스 변수: 생성자 안에서 self를 이용해 선언, 객체가 인스턴스화 될 때마다 초기화
- 클래스 변수: 생성자 밖에 속성을 지정하면 해당 속성을 해당 클래스로 생성한 모든 객체가 공유함
- 상속
class 클래스명(베이스 클래스):
pass- 베이스 클래스 호출 이유: 베이스 클래스의 내용이 변경될 경우 서브 클래스에 그대로 반영됨
- 코드 재활용을 위함
2. 머신러닝 개념 정리
CS231 2강을 듣고 정리한 내용
1) 이미지 분류
- Semantic Gap
실제 사진과 컴퓨터가 인식한 결과의 차이
→ 사람의 눈이 이미지를 인식하는 방법과 컴퓨터가 인식하는 방법이 달라서 생기는 문제 - Challenges
- Illumination
- Deformation
- Background Clutter
- Intraclass variation
- Attempts have been made
- 모든 모서리 각을 계산해 판단 → 물체가 변할 때마다 계산해야해서 계산량이 많아짐.
- Data Driven Approach
- 데이터셋, 라벨 모으기
- 머신러닝으로 classifier 학습시키기
- 새로운 이미지로 성능 평가
2) Nearest Neighbor
simple, dumb
작동 방식, 시간복잡도
1. 훈련 데이터 기억, O(1)
- 단순히 기억하기만 함.
- 예측 O(n)
⇒ 예측보다 훈련 시간이 짧음. 일반적으로 반대가 되어야 함.
| train | test |
|---|---|
| 모든 데이터, 라벨 기억 | 가장 비슷한 훈련 이미지의 라벨 기억 |
하이퍼 파라미터
알고리즘 학습 전 지정해야함. 지정 기준엔 특별한 방식이 없고 직접 해보면서 성능이 좋은 걸 선택.
-
k
몇 개의 이웃을 참고할지 -
L1 distance / L2 distance
출처
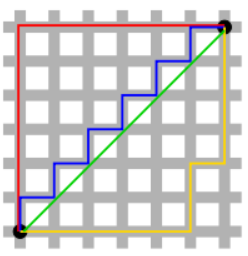
파란색 선이 L1, 초록색 선이 L2
| L1 distance | L2 distance |
|---|---|
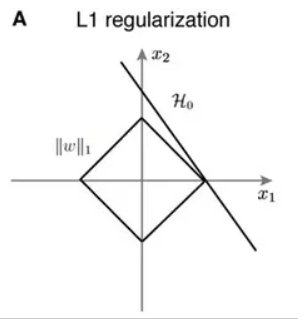 | 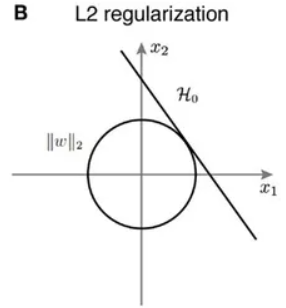 |
| 맨하튼 거리 | 유클리디안 거리 |
| 좌표계에 따라 모양이 바뀜 | 좌표계의 영향 안받음 |
| 특징벡터의 각 요소가 개별적 의미를 가질 경우 사용 | 일반적 벡터, 특별한 의미가 없을 때 사용 |
하이퍼파라미터 설정
1. k = 1 인 경우: 가장 최적의 결과가 나오게 설정하는 경우
2. train / test set으로 분리
3. train / validation / test set으로 분리
가장 좋은 방식은 3.
train set을 이용해 훈련, validation set을 이용해 여러 경우를 검증, test set은 검증된 알고리즘 중 가장 성능이 좋은 알고리즘으로 한 번만 실행
train set vs validation set
라벨을 직접 보느냐 안보느냐. train set은 라벨을 직접 보면서 훈련. validation set은 라벨에 직접 접근하지 않고 성능을 평가.
- cross validation
- 데이터가 적을 때는 유용하지만 딥러닝에서는 계산량이 많아져 쓰지 않는 방식
- 데이터를 여러 fold로 나눈 후 각 fold를 validation set으로 사용해 결과를 평균내는 방법
이미지 분류엔 활용하지 않음
- 시간 많이 걸림
- 픽셀 간의 거리가 유용한 정보는 아님
- 고차원일 수록 많은 데이터셋(포인트)이 필요 = 계산량이 기하급수적으로 늘어남
3) Linear Classification
- NN(Neural Network)과 CNN(Convolution Neural Network)의 기반 알고리즘
ex) CNN으로 이미지 학습, RNN으로 텍스트 학습 - parametic model의 가장 단순한 형태
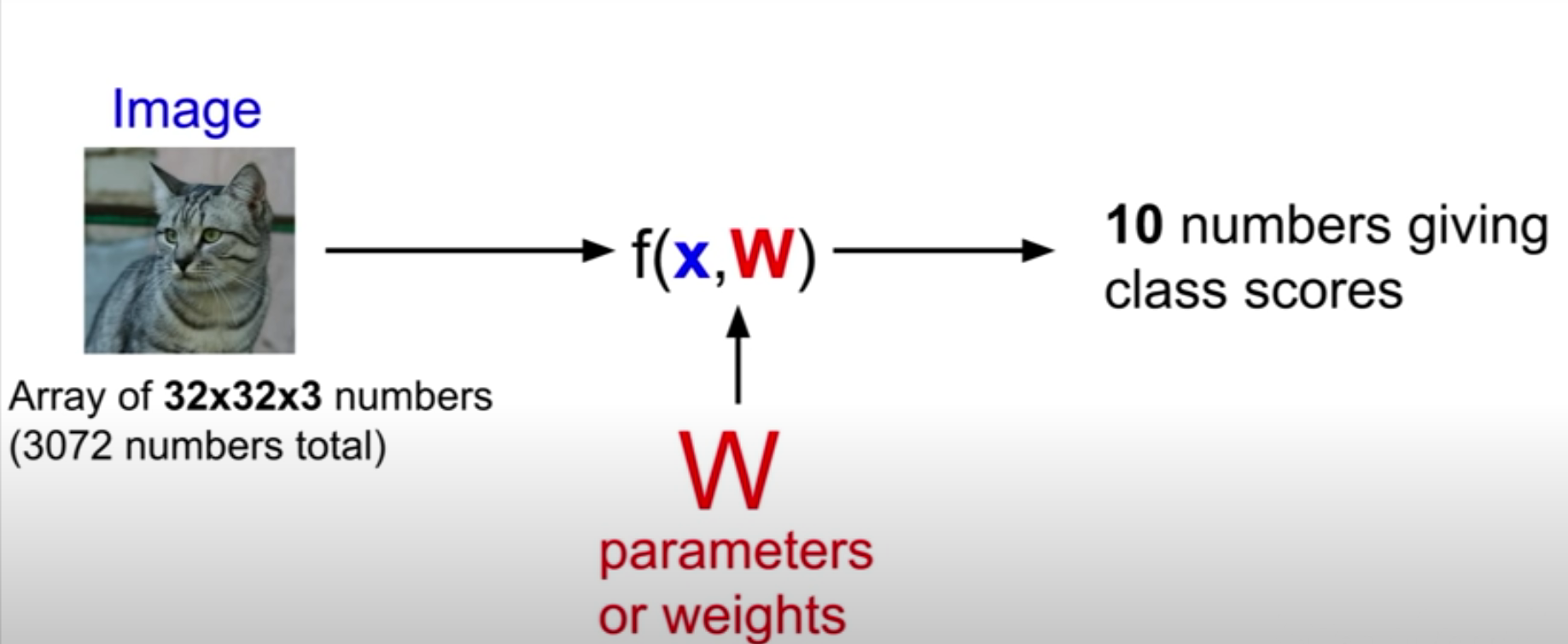
- 2 개의 다른 component: 입력 이미지(x), 가중치(W)
- 함수: x, W를 가지고 10개의 숫자를 출력. 이 숫자는 CIFAR-10에서 10개의 카테고리의 스코어임. 모델의 score가 높다는 것은 알맞게 라벨링을 했을 가능성이 높다는 의미
- parametric approach: training data의 정보를 요약, 이 요약된 정보를 W에 집약시킴. 그렇기 때문에 test time에 training data 필요 없고 W만 쓰면 됨.
⇒ 딥러닝에서 할 일: 함수를 잘 설계하는 것. 어떻게 W와 데이터를 합칠지에 대한 고민이 반영됨. (=NN)
1) Linear Classification
- 가장 간단한 방식: W, 데이터 단순 곱하기 = 행렬과 벡터의 곱의 형태
- bias: 데이터가 불균형할 때 데이터와 무관하게 특정 클래스에 우선권 부여
- 탬플릿 매칭과 유사
✔✔✔🤔 벡터의 내적 개선
-
한계: 하나의 클래스에 대해 하나의 탬플릿만 학습
-
이미지를 고차원의 점 중 하나라고 생각하기
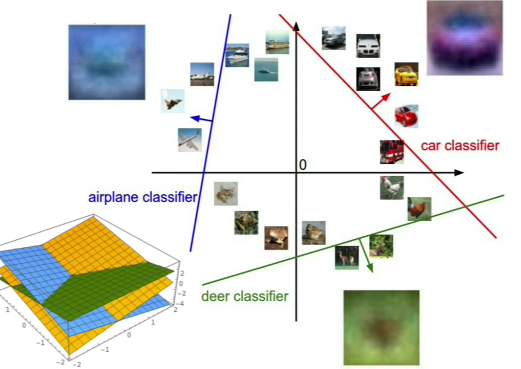
⇒ parity problem을 해결 못함
3. 회고
DeepML로 들어온 첫 날이다. 오전에 한 LMS는 클래스에 대해 다뤄서 괜찮았는데 오후에 휘몰아친 양이 많았다. 그래도 완전 이해 못할 정도는 아니어서 다행이었다. 오랜만에 수식을 봐서 멍했다가 천천히 생각해보니 이해돼서 괜찮았다. 기계학습 강의를 수강할 때 train - validation - test set을 나눠서 하는 방식이 있다는 건 그냥 흘리듯 듣기만 하고 직접 해보지 않았는데 나중에 이런 방식으로도 모델을 학습시켜봐야겠다.
