안녕하세요.
이 글에서는 EasyOCR을 학습,사용 해보고 추출결과의 정확도를 높이기 위한 전후 처리 과정을 다뤄보려 합니다.
프로젝트 설명
간단히 저희 '믿어방' 프로젝트를 설명하자면...
OCR을 사용해 부동산 등기부등본 또는 전월세주택임대착계약서를 촬영하면 촬영된 이미지 속에서 문서의 텍스트를 추출하고, 이에 대한 분석 결과를 제공하는 서비스를 기획하고 있습니다.
해당 서비스가 원활히 동작하려면 정확한 텍스트를 문서 이미지에서 추출하는 것이 필요한데요. 이때 문서 이미지에서 텍스트를 인식하는 기술이 바로 OCR입니다.
이를 위해 필요한 전반적인 과정을 오늘 포스팅에서 다뤄보겠습니다.
텍스트 추출 전과정
먼저 믿어방 프로젝트에서 문서 사진을 찍으면 그 문서로부터 텍스트를 추출하는 과정은 다음과 같습니다.
- 이미지 전처리 : GrayScale, Thresholding, 이미지의 기하하적 변환, 노이즈 제거 등을 통해 OCR 처리 전에 이미지를 보정함
- fine-tuning
- 추출한 문자에 대한 후처리 : 단어 사전 또는 맞춤법 교정 라이브러리를 이용해 잘못 읽힌 문자를 유사한 단어로 대체함
- 추출된 텍스트에 대한 유저 피드백: 추출 마지막 단계에서 최종적으로 유저 피드백 과정을 거침
오늘 포스팅에서는 1,2 단계에 대한 학습을 진행하겠습니다.
이미지 전처리
OCR 기술을 적용하기 전에 OCR이 읽기 쉬운 상태로 이미지를 세팅할 필요가 있습니다. 이를 위해 이미지 전처리 과정을 거칩니다.
이미지 전처리 과정에서는 촬영한 문서 이미지에 대해 GrayScale, Thresholding, 이미지의 기하하적 변환, 노이즈 제거 등을 적용합니다.
해당 기술을 적용하기 위해 OpenCV를 사용하고자 합니다.

바로 Colab에서 진행해보겠습니다.
먼저 사용될 라이브러리를 import합니다.
import numpy as np
import cv2
import matplotlib.pyplot as plt
from google.colab.patches import cv2_imshowimport문의 cv2가 여기서 사용할 OpenCV를 가리킵니다.
Image Thresholding(이미지 임계처리,이진화 처리)
일반적으로 우리가 사진을 찍으면, 사진에는 다양한 색상이 포함되어 있습니다.
OCR 기술을 적용함에 있어서는 이 점이 방해가 될 수 있습니다.
따라서 이미지를 흑과 백으로 분류하여 처리하는 Thresholding을 이용해 OCR 처리에 도움이 될 이미지로 바꿔보겠습니다. 특정 방법을 통해 임계값을 결정하고, 이 값보다 크면 백, 작으면 흑으로 이미지 속에서 임계치가 결정됩니다.
기본 Thresholding
기본적인 방식의 Thresholding입니다. 사용자가 고정된 임계값을 결정하면 이를 적용한 결과를 보여줍니다.
기본적인 Thresholding에는 OpenCV의 cv2.threshold() 메서드를 사용합니다.
다음 형태로 사용하면 됩니다.
cv2.threshold(src, thresh, maxval, type)
src: input image
thresh: 임계값
maxval: 임계값을 넘었을 때 적용할 값
type: thresholding의 type
- type에는
cv2.THRESH_BINARY,cv2.THRESH_BINARY_INV,cv2.THRESH_TRUNC,cv2.THRESH_TOZERO,cv2.THRESH_TOZERO_INV등이 있다.
Colab에서는 다음과 같이 사용하면 됩니다. 구글링하여 얻은 티켓 이미지를 적용했습니다.
(티켓이미지출처)
img = cv2.imread('ticket1.jpg',0)
ret, thresh1 = cv2.threshold(img,127,255, cv2.THRESH_BINARY)
ret, thresh2 = cv2.threshold(img,127,255, cv2.THRESH_BINARY_INV)
ret, thresh3 = cv2.threshold(img,127,255, cv2.THRESH_TRUNC)
ret, thresh4 = cv2.threshold(img,127,255, cv2.THRESH_TOZERO)
ret, thresh5 = cv2.threshold(img,127,255, cv2.THRESH_TOZERO_INV)
titles =['Original','BINARY','BINARY_INV','TRUNC','TOZERO','TOZERO_INV']
images = [img,thresh1,thresh2,thresh3,thresh4,thresh5]
for i in range(6):
# plt.figure(figsize=(10,8))
plt.subplot(2,3,i+1),plt.imshow(images[i],'gray')
plt.title(titles[i])
plt.xticks([]),plt.yticks([])
plt.show()결과 이미지입니다.

적응 Thresholding
앞서 나온 기본 Thresholding 방식의 한계는 임계값을 이미지 전체 적용하기 때문에 일부분이 모두 흰색 또는 검정색으로 나타날 수 있습니다.
이를 해결하기 위해 사용할 수 있는 것이 cv2.adaptiveThreshold()입니다. 이는 이미지를 작은 영역들로 나누어 각 영역에서 Thresholding을 합니다.
다음 형태로 사용하면 됩니다.
cv2.adaptiveThreshold(src, maxValue,adaptiveMethod,thresholdType, blockSize, C)
src: 그레이스케일처리한 이미지
maxValue: 임계값
adaptiveMethod: 임계값을 결정하는 계산방법
thresholdType: thresholding의 type
blockSize: thresholding을 적용할 영역의 크기
C: 평균이나 가중평균에서 차감하는 값
- AdaptiveMethod에는
cv2.ADAPTIVE_THRESH_MEAN_C,cv2.ADAPTIVE_THRESH_GAUSSIAN_C등이 있다.- thresholdType에는
cv2.THRESH_BINARY,cv2.THRESH_BINARY_INV,cv2.THRESH_TRUNC,cv2.THRESH_TOZERO,cv2.THRESH_TOZERO_INV등이 있다.
Otsu의 이진화
앞서 이미지 Thresholding을 설명할 때 "특정 방법을 통해 임계값을 결정"한다고 언급했습니다. 그렇다면 임계값은 어떻게 결정하는 걸까요?
일반적인 방법은 trial and error를 통해 결정하는 것입니다. 이렇게 하는 방식은 gloabl thresholding이라고 합니다. 임의의 T를 기준으로 잡고 클래스를 나눠서 각 클래싀의 평균의 평균을 구하고, 그것을 다시 T를 잡아 앞의 고정을 반복합니다.
하지만 다른 방법이 하나 더 있습니다.
thresholding 하고자 하는 이미지가 bimodal image인 경우에는 히스토그램을 통해 임계값을 계산할 수도 있습니다.
이때 bimodal image의 정의는 이렇습니다
Bimodal literally means "two modes" and is typically used to describe distributions of values that have two centers.
값의 분포가 두 개의 center로 나타나는 이미지를 말합니다.
따라서!
히스토그램으로 이미지를 분석했을 때 peak가 2개 생기는 이미지는 임계값을 계산할 수 있습니다.
이를 Otsu의 이진화라고 합니다.
그렇다면 임계값은 어떻게 계산할까요? Otsu 이진화에서는 평균과 분산을 이용하여 within-class와 betweenj-class를 이용합니다.
예를 들어보겠습니다.
출처:https://www.quora.com/What-are-bimodal-images

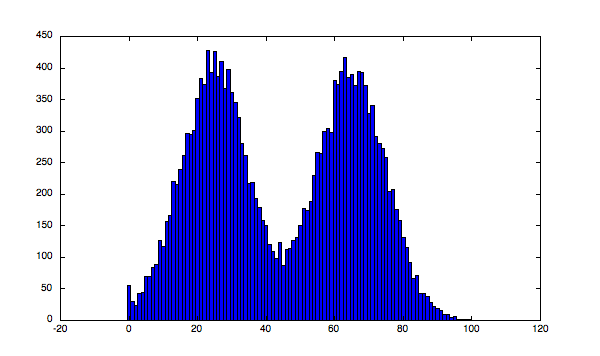
이런 이미지가 bimodal image의 예시인데요.
이 축구공 이미지를 히스토그램으로 분석하면 다음처럼 peak가 2개 생기기 때문입니다.
출처: 위 사진과 동일
이러한 Otsu의 이진화는 OpenCV에서 cv2.threshold()를 이용해 구현할 수 있습니다.
cv2.threshold() 메소드의 cv2.THRESH_STSU를 추가로 적용하고 임계값은 0으로 넣으면 됩니다.
적용한 코드는 다음과 같습니다.
img = cv2.imread('ticket1.jpg',0)
# global thresholding
ret1, th1 = cv2.threshold(img, 127, 255, cv2.THRESH_BINARY)
ret2, th2 = cv2.threshold(img, 0, 255, cv2.THRESH_BINARY+cv2.THRESH_OTSU)
blur = cv2.GaussianBlur(img,(5,5),0)
ret3, th3 = cv2.threshold(img, 0, 255, cv2.THRESH_BINARY+cv2.THRESH_OTSU)
# plot all the images and their histograms
images = [img, 0, th1, img, 0, th2, blur, 0, th3]
titles = ['Original Noisy Image','Histogram','Global Thresholding (v=127)', 'Original Noisy Image','Histogram',"Otsu's Thresholding", 'Gaussian filtered Image','Histogram',"Otsu's Thresholding"]
for i in range(3):
plt.figure(figsize=(15,8))
plt.subplot(3,3,i*3+1),plt.imshow(images[i*3],'gray')
plt.title(titles[i*3]), plt.xticks([]), plt.yticks([])
plt.subplot(3,3,i*3+2),plt.hist(images[i*3].ravel(),256)
plt.title(titles[i*3+1]), plt.xticks([]), plt.yticks([])
plt.subplot(3,3,i*3+3),plt.imshow(images[i*3+2],'gray')
plt.title(titles[i*3+2]), plt.xticks([]), plt.yticks([])
plt.show()가장 우측 열은 위에서부터 global threshold 값, otsu threshold 값, Gaussian blur를 이용해 노이즈를 제거한 뒤에 otsu thresholding을 적용한 값입니다.
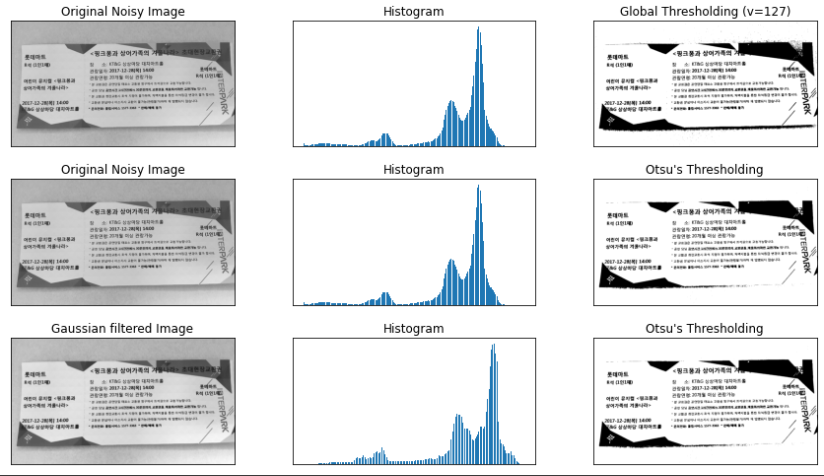
Image Smoothing
Image filtering
이미지도 주파수로 표현 가능하다는 사실 알고 계셨나요?
고주파는 밝기의 변화가 많은 곳, 즉 이미지 속 경계에서 나타납니다.
따라서, 비슷한 밝기가 계속되는 부분에서는 저주파가 나타나겠죠.
따라서 filtering 처리를 하려면 고주파와 저주파 중 어느 곳을 제거해야 할까요?
바로 고주파입니다.
OpenCV에서는 cv2.filter2D를 이용해 이미지의 filter를 적용할 수 있습니다.
코드로 확인해보면 다음과 같습니다.
src = cv2.imread('ticket1.jpg', cv2.IMREAD_GRAYSCALE)
kernel = np.ones((3,3), dtype = np.float64) / 9
dst = cv2.filter2D(src, -1, kernel)
cv2_imshow(src) #필터링 적용전
cv2_imshow(dst) #필터링 적용 후아래 이미지가 필터링 적용전,

아래 이미지가 필터링 적용후입니다.

Image Blurring
Image Blurring을 위한 기술들은 loss-pass filter를 통해 고주파 영역을 제거하여 노이즈를 제거하고, 사진 속 경계를 흐릿하게 합니다.
문서 속에서 텍스트를 추출하는 ocr 기술의 전처리로서 글자를 선명하게 해야하는데 오히려 글을 흐릿하게 보일 것이라고 생각했습니다.
그래서 직접 한번 적용해보면서 ocr의 전처리 기술로서 의미가 있는지 알아보려 합니다.
OpenCV에서 제공하는 blurring 기능은 4가지입니다.
기본 블러
cv2.blur(src, ksize)를 사용합니다.
ksize: 커널 사이즈
박스 형태의 커널을 이미지에 적용합니다. 그 다음에 평균값을 박스의 중심점에 적용합니다.
Gaussian Filtering
cv2.GaussianBlur(img,ksize,sigmaX)을 사용합니다.
가우시안 함수를 이용한 커널을 이용한다는 것이 기본 블러와의 차이점입니다.
Median Filtering
cv2.medianBlur(src, ksize)을 사용합니다.
kernel window와 pix의 값들을 정렬하고 중간값을 선택해 적용합니다.
Bilateral Filtering
cv2.bilateralFilter(src, d, sigmaColor, sigmaSpace를 사용합니다.
d: 필터링 시에 고려할 주변 pixel의 지름
sigmaColor: 색을 고려할 공간
sigmaSpace: 숫자가 클수록 멀리 떨어진 pixel도 고려
경계선은 보존하되 가우시안 블러 처리가 가능합니다.
다음 코드를 이용해 직접 사용해 보겠습니다.
import cv2
import numpy as np
from matplotlib import pyplot as plt
img = cv2.imread('ticket1.jpg')
# pyplot를 사용하기 위해서 BGR을 RGB로 변환.
b,g,r = cv2.split(img)
img = cv2.merge([r,g,b])
# 일반 Blur
dst1 = cv2.blur(img,(7,7))
# GaussianBlur
dst2 = cv2.GaussianBlur(img,(5,5),0)
# Median Blur
dst3 = cv2.medianBlur(img,9)
# Bilateral Filtering
dst4 = cv2.bilateralFilter(img,9,75,75)
images = [img,dst1,dst2,dst3,dst4]
titles=['Original','Blur(7X7)','Gaussian Blur(5X5)','Median Blur','Bilateral']
for i in range(5):
plt.figure(figsize=[20,10])
plt.subplot(3,2,i+1),plt.imshow(images[i]),plt.title(titles[i])
plt.xticks([]),plt.yticks([])
plt.show()결과 이미지입니다.





결과적으로 image smoothing은 모두 ocr을 위한 전처리 과정으로는 부적합하며, grayscale과 thresholding이 ocr을 위한 전처리 과정으로 가장 적합함을 알 수 있었습니다.
EasyOCR 테스트
환경 구축
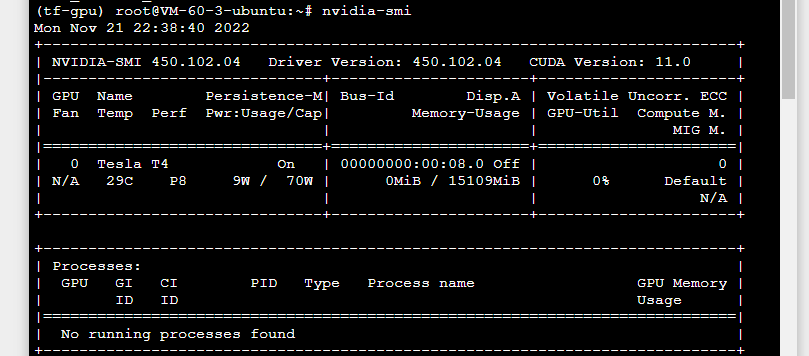
ubuntu를 이용해 가상공간을 만들고 gpu를 확인합니다.
nvidia-smi
Tesla T4를 확인할 수 있습니다.
한국어 EasyOCR 학습은 해당 깃허브를 참고해 진행했습니다.
참고 깃허브
git clone https://github.com/parksunwoo/ocr_kor.git
default 모델로 테스트
우선 EasyOCR에서 제공하는 default 모델로 테스트 해봤습니다.
해당 모델을 조합하여 사용합니다. 각 부분에서 쓰이는 모델은 다음과 같습니다.
Transformation: None, TPS
FeatureExtraction: VGG, RCNN, ResNet
SequenceModeling : None, BiLSTM
Prediction: CTN, Attn
(gpu문제로 중간에 새로운 인스턴스를 이용해 우분투 환경을 조성하여 모델 학습을 할때와 fine-tuning을 통한 학습을 할 때의 디렉토리 구조가 좀 다릅니다. 방식은 같습니다. 참고 바랍니다.)
None-ResNet-BiLSTM-CTC
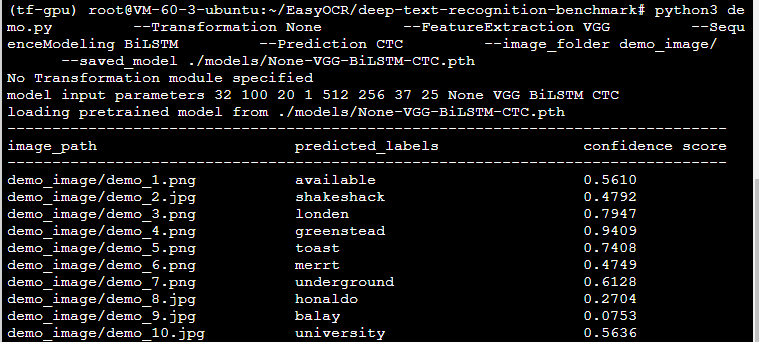
TPS-ResNet-BiLSTM-CTC
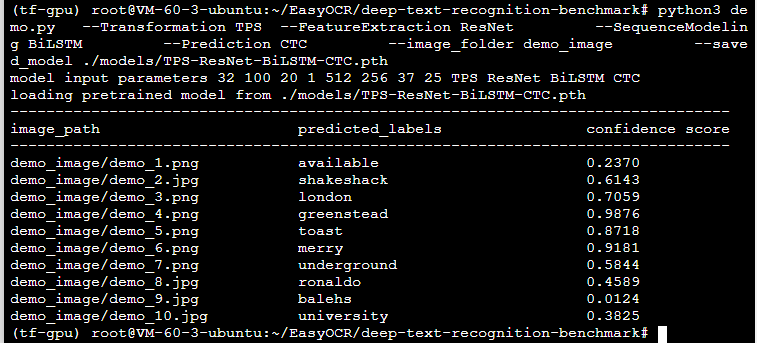
TPS-ResNet-BiLSTM-Attn-case-sensitive
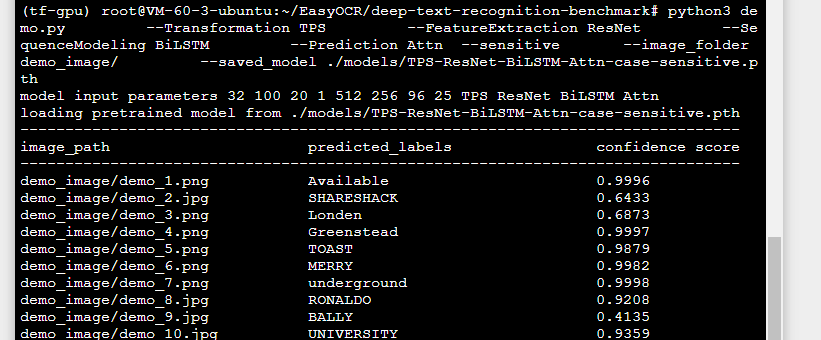
TPS-ResNet-BiLSTM-Attn-case-sensitive 모델이 전반적으로 높은 confidence score를 보여줬습니다.
FINE-TUNING
나아가 OCR 기능의 성능을 특화시킬 여지가 있는지 알아보기 위해 EasyOCR에 대한 fine-tuning을 진행했습니다. 모델을 학습시키는 것이 핵심이기 때문에 이번 글에서는 모델 학습에 초점을 맞춰 작성했습니다.
TextRecognitionDataGenerator를 이용해 다양한 형태의 문장 데이터를 제작하고, deep-text-recognition-workbench로 데이터를 이용해 fine-tuning을 진행했습니다.
문장 데이터 생성
먼저 bash 파일을 이용해 문장 데이터를 생성합니다.
폰트는 네이버 나눔글꼴 23종과 네이버 나눔손글씨 109종을 사용했습니다.
단어 데이터셋은 국립국어원 한국어 학습용 어휘목록 데이터셋을 사용했습니다.
ocr의 정확도를 높이기 위해선 다양한 스타일의 문장 데이터를 생성하여 학습시킬 필요가 있습니다. 따라서 기본 3000문장,기울기를 조정한 4000문장, 왜곡을 포함하는 2000문장,블러를 적용한 2000문장, 배경을 포함하는 1000문장을 생성하였습니다.
기본문장과 기울기를 조정한 문장, 총 7000문장은 training data로 사용합니다. 또 블러를 적용한 문장, 배경을 포함하는 문장, 왜곡을 포함하는 문장을 합한 5000문장은 validation data로 사용합니다.
사용한 bash 파일은 다음과 같습니다.
generate_data_5type.sh
# train_basic 9000
python run.py -c 3000 -w 10 -f 64 -l ko --output_dir out/basic;
# train_skew 9000
python run.py -c 2000 -w 10 -f 64 -k 5 -rk -l ko --output_dir out/skew;
python run.py -c 2000 -w 10 -f 64 -k 15 -rk -l ko --output_dir out/skew;
# val_distortion 3000
python run.py -c 1000 -w 10 -f 64 -d 3 -do 0 -l ko --output_dir out/dist;
python run.py -c 1000 -w 10 -f 64 -d 3 -do 1 -l ko --output_dir out/dist;
# val_blur 3000
python run.py -c 1000 -w 10 -f 64 -l ko -bl 1 --output_dir out/blur;
python run.py -c 1000 -w 10 -f 64 -l ko -bl 2 --output_dir out/blur;
# val_background 3000
python run.py -c 500 -w 10 -f 64 -l ko -b 0 --output_dir out/back;
python run.py -c 500 -w 10 -f 64 -l ko -b 1 --output_dir out/back;
각 설정들이 의미하는 바는 다음과 같다.
- c: 문장의 개수
- w: 포함할 단어의 개수
- f: 포맷 (수평인 경우 생성된 이미지의 높이와 너비를 정의)
- l: 언어
- rk: 기울어진 정도
- do: 왜곡 정도
- bl: 블러 정도
- b: 배경 정도
sh generate_data_5type.sh 명령을 터미널에서 실행하면 데이터가 생성됩니다.

생성된 데이터는 다음과 같은 경로로 저장됩니다.
ocr_kor/data/generator/TextRecognitonDataGenerator/out
ocr_kor/data/generator/TextRecognitonDataGenerator/out/basic
생성된 개별적인 문장 데이터는 다음과 같습니다.
basic (기본)

back (배경포함)

blur (블러)

distortion (왜곡)
skew (기울기)

문장케이스별 gt.file 생성
학습에 필요한 lmdb dataset 형식을 만드려면 gt.file이 필요합니다.
gt. file은 다음과 같은 구조로 이뤄져 있습니다.

문장케이스별로 gt file을 만들어 결과적으로 gt_basic.txt, gt_blur.txt, gt_back.txt, gt_skew.txt, gt_dist.txt 파일을 얻을 수 있었습니다.
lmdb dataset 생성
해당 문장을 deep-text-recognition-benchmark에 적용하여 모델을 학습시키기 위해서는 문장 데이터를 이용해 lmdb dataset을 생성해야 합니다.
다음 코드의 형식을 이용하여 타입을 바꿔주면서 5개의 파일을 생성하는데
$ python3 trdg/create_lmdb_dataset.py --inputPath trdg/ --gtFile trdg/gt_basic.txt --outputPath ../deep-text-recognition-benchmark/data_lmdb_release/training/basic;이처럼 lmdb 파일이 만들어집니다.

train.py로 학습 시키기
드디어 학습 단계입니다.
train.py를 이용해 학습을 진행합니다.
!CUDA_VISIBLE_DEVICES=0 python3 train.py
--train_data ../data/data_lmdb_release/training
--valid_data ../data/data_lmdb_release/validation
--select_data basic-skew
--batch_ratio 0.5-0.5
--Transformation TPS
--FeatureExtraction VGG
--SequenceModeling BiLSTM
--Prediction CTC
--data_filtering_off
--valInterval 100
--batch_size 128
--batch_max_length 50
--workers 6
--distributed
--imgW 400;
--train_data : training 데이터
--valid_data: validation 데이터
--select_data: 학습에 사용할 데이터
--Transformation: None, TPS 중 선택
--FeatureExtraction: VGG, RCNN, ResNet 중 선택
--SequenceModeling : None, BiLSTM 중 선택
--Prediction: CTN, Attn 중 선택
이후 gpu 문제로 colab으로 학습 환경을 변경하여 진행하였습니다. 데이터수가 적어 정확도가 낮다고 판단해 법무부 생활법률지식 데이터셋에서 부동산 계약과 관련된 단어 287개를 단어를 뽑아 문장 생성을 위한 dictionary에 넣고 새롭게 basic 9000, skew 9000, blur 3000, back 3000, dist 3000 문장을 생성하여 데이터셋을 늘려 다시 학습을 진행했습니다.
학습중
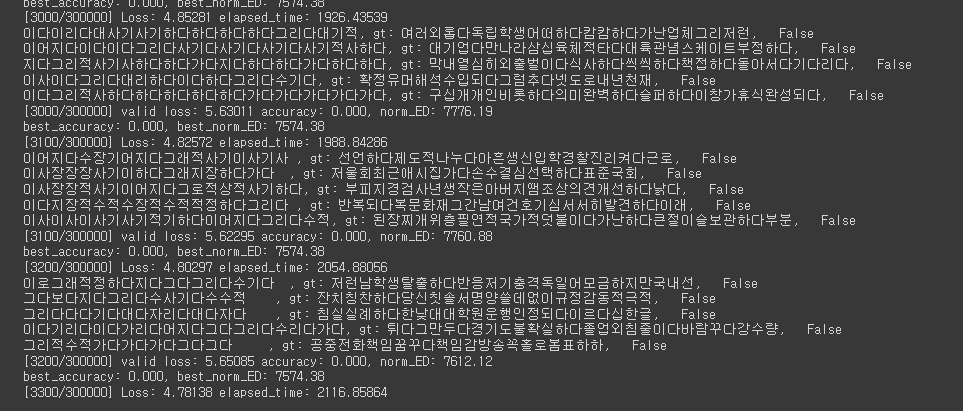

log.train 파일을 통해 학습 결과를 확인할 수 있습니다.
앞으로의 계획
- 모델 구조를 변경하고 문장 생성을 위한 단어 데이터를 새롭게 하여 계속하여 학습을 진행하고, 가장 정확도가 높은 모델을 찾아낼 계획입니다. 프로젝트 주제인 부동산 관련 단어 데이터인 법무부 생활지식 데이터셋과 새롭게 추가한 폰트를 이용해 새로운 문장 이미지를 만들고 이를 이용해 학습을 진행할 계획입니다.
- EasyOCR의 정확도 향상에 한계가 있다면 전처리 방식과 후처리 방식을 좀 더 탐구해볼 계획입니다. 부동산 단어 데이터셋을 이용한 오타를 유사한 단어로 바꾸는 방식을 고려하고 있습니다.


잘 읽었어요~