활동스트림 html 가져오기
#현재 3.14.1 selenium 버전 사용중
from selenium import webdriver
#타임 객체 선언
from time import sleep
import requests
from bs4 import BeautifulSoup as bs
#크롬 웹 드라이버 경로
driver = webdriver.Chrome('C:\Chrome_Driver\chromedriver.exe')
#크롬으로 네이버 로그인 화면 접속
url = "https://ecampus.chungbuk.ac.kr/"
driver.get(url)
#아이디와 비밀번호 입력(0.5초씩 기다리기) - 너무 빠르면 대형 사이트는 트래픽 공격으로 인식
print('user_id : ')
user_id = input()
sleep(0.5)
driver.find_element_by_name('uid').send_keys(user_id)
print('user_pw : ')
user_pw = input()
sleep(0.5)
driver.find_element_by_name('pswd').send_keys(user_pw)
#Xpath
driver.find_element_by_xpath('//*[@id="entry-login"]').click()
#사이트 이동
driver.get('https://ecampus.chungbuk.ac.kr/ultra/stream')
#활동스트림 내용 담은 element 가져오기
sleep(5)
response=driver.find_element_by_xpath('//*[@id="body-content"]').get_attribute('innerHTML')
soup = bs(response, 'html.parser')
print(soup.prettify()) #soup.prettify() : html구조를 파악하기 쉽게 바꿔줌
login 구현 이후 활동스트림에서 html을 가져오고 싶었으나!
자꾸만 login 화면 내의 html 요소를 가져오는 문제가 있었다.
당시 삽질 코드
sleep(2)
url='https://ecampus.chungbuk.ac.kr/ultra/stream'
driver.get(url)
sleep(10)
html=requests.get(url)
soup = bs(html, 'html.parser')
soup=soup.find('span') #span 태그 가져오기
print(soup)BeautifulSoup이 뭔지도 잘 모르고 무작정 크롤링만 하려고 덤벼서 생긴 문제였다.
위 코드의 문제점은
무작정 url이동만 하고 당연히 이동한 url에서 html을 가져올 것이라고 생각했으나
위 코드대로 하면 url을 구글 주소창에 다시 써서 새로 블랙보드로 들어가는 개념이므로 계속 login 화면에서 html을 가져온 것이었다.!
따라서, 해결법은
response=driver.find_element_by_xpath('//*[@id="body-content"]').get_attribute('innerHTML')
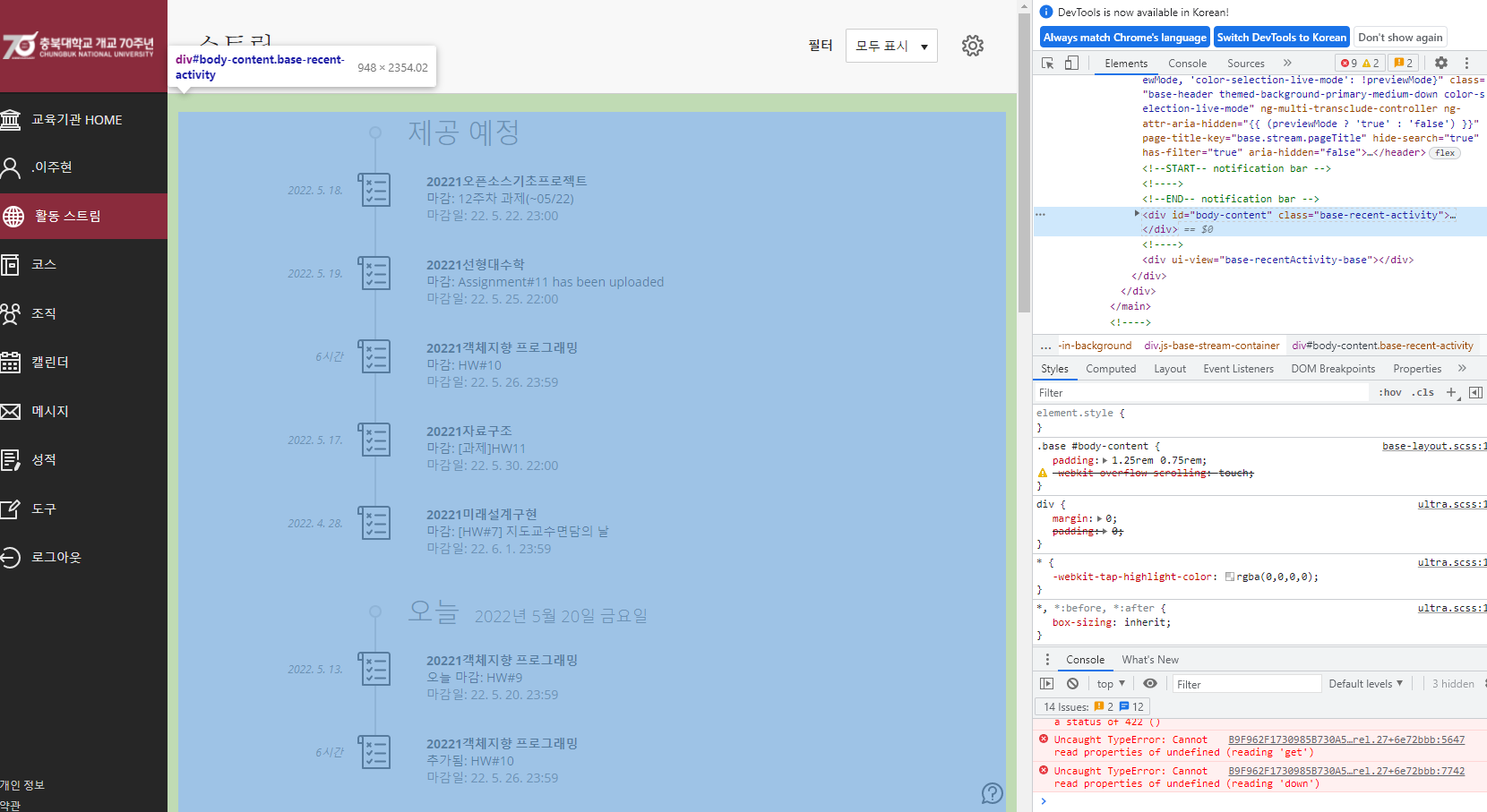
< div id="body-content" class="base-recent-activity" >의 XPath = //*[@id="body-content"]
find_element_by_xpath 와 get_attribute()
- find_element_by_xpath : html의 xpath를 이용해서 원하는 값을 긁어옴
- get_attribute() : 매개변수로 지정된 element의 속성을 읽음
- innerHTML : element 내에 있는 HTML 내용 전체를 반환
- textContent : element 내에 있는 HTML 태그를 제외한 모든 텍스트를 반환

나대로 열심히 하다보면 또 어딘가에 닿아있겠지 p(´∇`)q