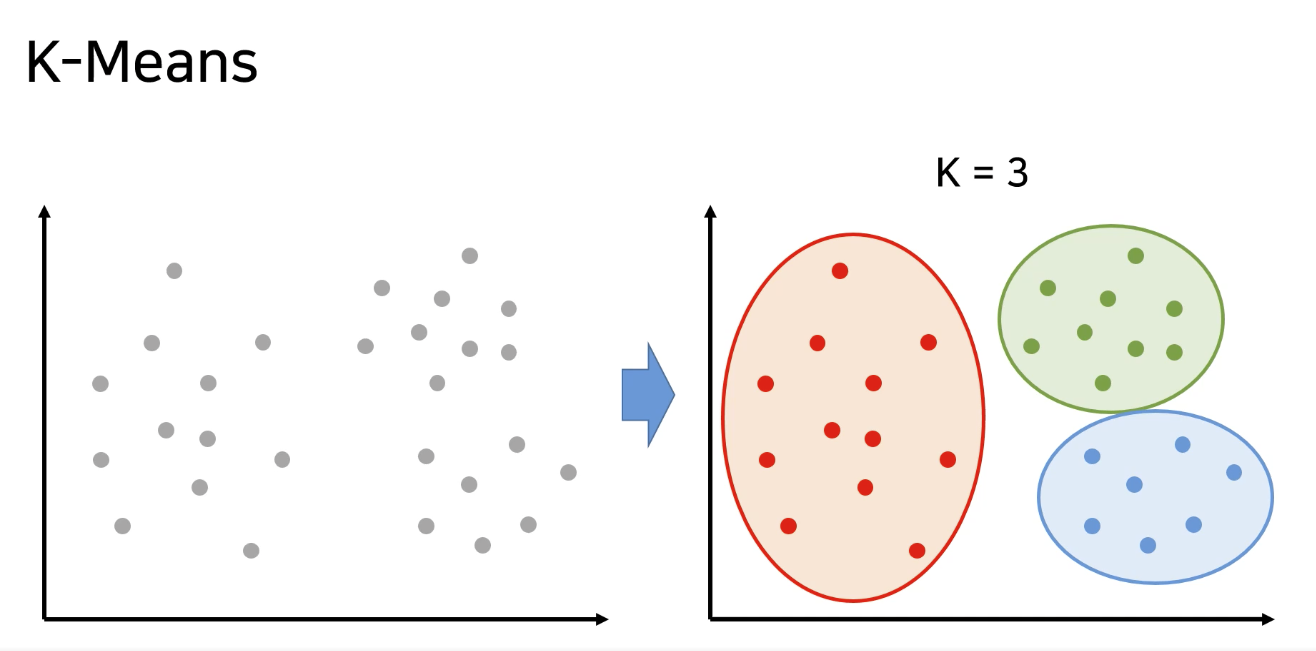
K-Means (K-평균)
- 데이터를 K개의 클러스터(그룹)로 군집화하는 알고리즘, 각 데이터로부터 이들이 속한 클러스터의 중심점까지의 평균 거리를 계산
중심점 : Centroid- 비지도 학습
[K-Means 동작 순서] 1. K 값 설정
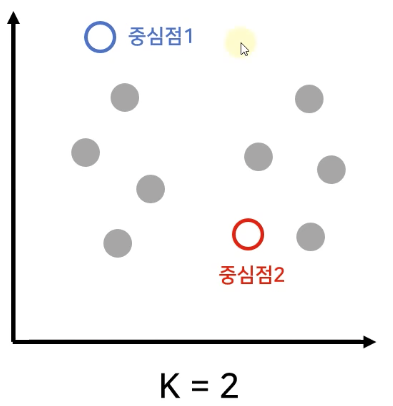
[K-Means 동작 순서] 2. 지정된 K개 만큼의 랜덤 좌표 설정
- 랜덤 좌표 설정이 제일 민감한 문제. 값이 천차만별로 변경될 수 있다 => 원치않는 결과 초래
- 각 Centroid 간의 거리가 짧으면 클러스터링이 제대로 이루어지지 않을 수 있다.
Random Initialization Trap : (중심점) 무작위 선정 문제
[K-Means 동작 순서] 3. 모든 데이터로부터 가장 가까운 중심점 선택
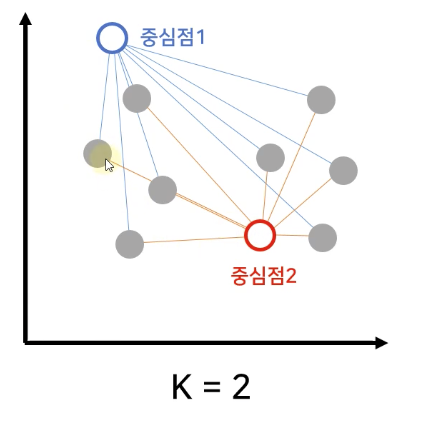
- 중심점1과 중심점2를 선으로 긋는다.
- 연결된 선의 중간 지점에 수직인 선을 긋는다. (중심점1과 중심적2 연결선은 제거)
- 아래와 같은 수직선이 생성된다.

[K-Means 동작 순서] 4. 데이터들의 평균 중심으로 중심점 이동

[K-Means 동작 순서] 5. 중심점이 더 이상 이동되지 않을 때까지 반복
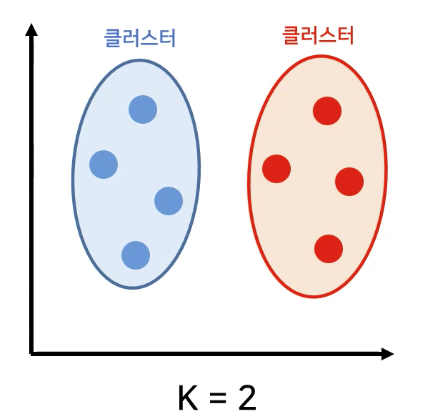
- 총 2개의 클러스터가 발생한다.
Random Initialization Trap : (중심점) 무작위 선정 문제
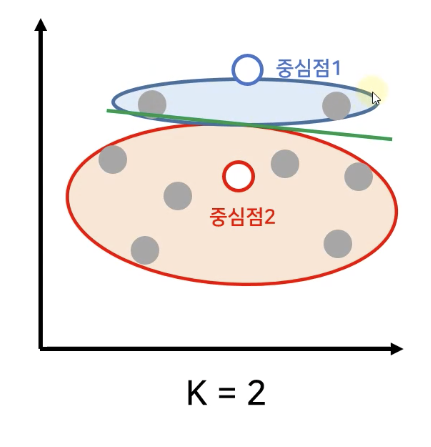

- 정상적으로 Centroid를 선정한 결과물과 완전히 다른 결과를 초래할 수 있다.
- 위와 같은 문제를 해결하기 위하여,
K-Means++
K-Means++
- 데이터 중에서 랜덤으로 1개를 중심점으로 선택
- 나머지 데이터로부터 중심점까지의 거리 계산
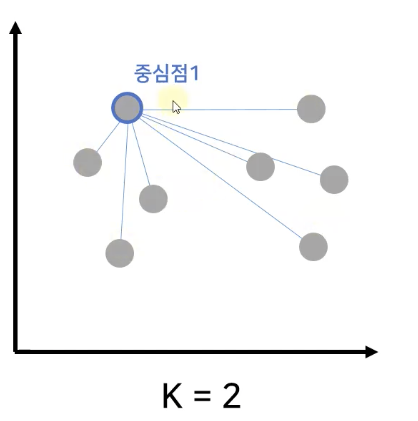
- 중심점과 가장 먼 지점의 데이터를 다음 중심점으로 선택

- 중심점이 K개가 될 때까지 반복
- 4번까지 완료되고 난 후, 앞에서의 K-Means 전통적인 방식으로 진행

꾸준히 새로운 것을 알아가는 것을 좋아합니다.