# w1 과 w0 를 업데이트 할 w1_update, w0_update를 반환.
def get_weight_updates(w1, w0, X, y, learning_rate=0.01):
N = len(y)
# 먼저 w1_update, w0_update를 각각 w1, w0의 shape와 동일한 크기를 가진 0 값으로 초기화
# np.zeros_like : 어떤 특정 array와 같은 사이즈, 크기(shape)의 zeros array를 구하고자 함.
w1_update = np.zeros_like(w1)
w0_update = np.zeros_like(w0)
# 예측 배열 계산하고 예측과 실제 값의 차이 계산
y_pred = np.dot(X, w1.T) + w0
diff = y-y_pred
# w0_update를 dot 행렬 연산으로 구하기 위해 모두 1값을 가진 행렬 생성
w0_factors = np.ones((N,1))
# w1과 w0을 업데이트할 w1_update와 w0_update 계산
w1_update = -(2/N)*learning_rate*(np.dot(X.T, diff))
w0_update = -(2/N)*learning_rate*(np.dot(w0_factors.T, diff))
return w1_update, w0_updatenumpy.T를 하는 이유?
Q. dot 연산 시, 전치행렬을 곱해주는 것
- Gradient Descent를 수행할 때, 예측값 y_pred = np.dot(X, w1.T) + w0
이는 X가 [x1, x2, x3]와 같이 여러 개의 feature 들로 되어 있고, 가중치 W 벡터 역시 [w1, w2, w3]로 되어 있을 때 예측 회귀식은 y_pred = x1w1 + x2w2 + x3w3 와 같이 계산하기 위해서 가중치 W 벡터의 전치값을 취한다. (편의상 w0는 제외)
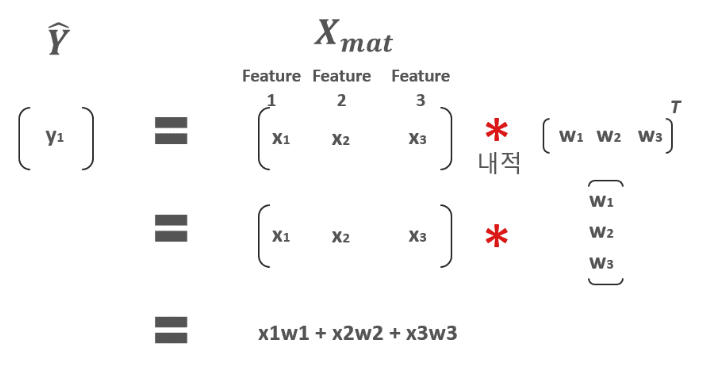
물론 강의에서는 feature도 1개, 가중치도 1개이기 때문에 w벡터의 전치를 하지 않아도 무방하지만, 보통 여러 개의 feature들이 있기 때문에 w벡터의 전치를 적용하여 X feature와 내적한다.
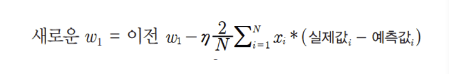
2-1. W1_update 시에는 위와 같은 식을 구하려면 X집합과 실제값 - 예측값 집합을 내적하면 구할 수 있습니다. (개별 X 데이터 원소들을 하나씩 더하고 곱하는 식을 반복할 필요 없이 한번에 내적으로 구하는 방식입니다. )
X 데이터 셋의 Shape가 (100, 1) 즉 100개의 행을 가지는 1개의 feature로 되어 있으며 실제값 -예측값 집합 역시 각 개별 X 데이터 별로 타겟값과의 차이를 나타내는 diff 변수로서 Shape가 (100, 1)입니다. 이때 X.T (즉 (1, 100)으로 Shape 변환)한 결과와 diff 를 dot 연산하면 쉽게 결과를 얻을 수 있습니다.

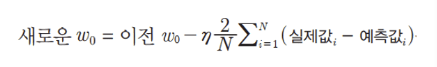
그런데 이게 오히려 선형 대수의 dot 같은 연산으로 바로 구하기가 어려워서 일부로 전체가 1의 값을 가지는 w0_factors = np.ones((100, 1)) 즉 100개의 행을 가지는 1개의 feature되어 있는 행렬을 만들고 이를 이용하여 dot 연산으로 유도하였습니다. 1에 각각 자기 원소를 곱하면 원래 자기 원소임을 이용한 것입니다.
w0_factors = np.ones((100,1))
w0_update = -(2/100)learning_rate(np.dot(w0_factors.T, diff))

꾸준히 새로운 것을 알아가는 것을 좋아합니다.