2-1. 배깅과 페이스팅(Bagging, Pasting)
Bagging은 Bootstrap Aggregating의 약자로 앞서 다룬 Voting과는 달리 동일한 알고리즘 내에서 샘플링을 다르게 하여 여러 분류기를 생성하는 모델을 뜻한다.
아래의 그림이 Voting과 Bagging의 차이점을 명확히 보여준다.
(Bagging 방식의 대표적인 예가 결정트리 모델인 random forest이기 때문에 해당 그림에서는 Decision Tree 모델을 예로 들었다. 참조 블로그 링크)
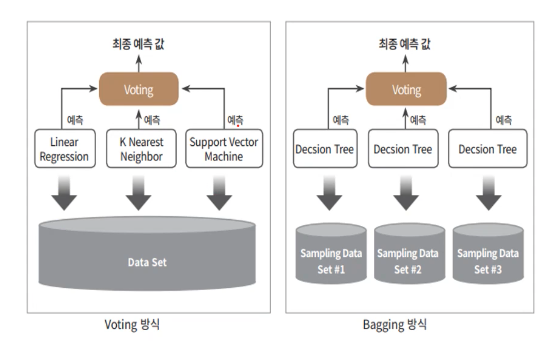
Bagging은 Bootstrap Aggregating의 약자라고 하였다. 그림에서 확인할 수 있듯이 각각의 예측 모델에 데이터를 샘플링하여 추출하는 방식을 Bootstraping이라고 한다. 샘플링된 데이터를 바탕으로 학습한 뒤 각각의 개별 분류기가 예측을 수행하고, 그 결과를 바탕으로 최종 예측 결과를 선정하는 방식을 Bagging Ensemble 방식이라고 부른다.
최종 예측 결과는 회귀모델이냐 분류모델이냐에 따라 다른 방식으로 진행된다.
- 분류 모델에서는 통계적 최빈값을 최종 예측값으로 선정한다.
(Hard Voting과 같은 방식)- 회귀 모델에서는 평균을 최종 예측값으로 선정한다.
(Soft Voting과 같은 방식)
사이킷런에서 제공하는 Bagging Classifier를 활용하여
결정트리 분류기와 결정트리 분류기를 사용한 배깅 분류기의 성능 차이를 확인해봤다.
데이터셋은 이전 글에서 사용했던 Iris 데이터셋을 활용했다.
결정트리 분류기(DecisionTreeClassifier)
from sklearn.ensemble import BaggingClassifier from sklearn.tree import DecisionTreeClassifier from sklearn.metrics import accuracy_score iris = load_iris() X = iris.data Y = iris.target X_train, x_test, Y_train, y_test = train_test_split(X, Y, test_size=0.3, random_state=22) y_pred_tree = tree.predict(x_test) print(accuracy_score(y_test, y_pred_tree)) >>> 0.9333333333333333
배깅 분류기(BaggingClassifier)
from sklearn.ensemble import BaggingClassifier from sklearn.tree import DecisionTreeClassifier from sklearn.metrics import accuracy_score iris = load_iris() X = iris.data Y = iris.target X_train, x_test, Y_train, y_test = train_test_split(X, Y, test_size=0.3, random_state=22) bagging = BaggingClassifier(DecisionTreeClassifier(), n_estimators=1000, max_samples=0.5, bootstrap=True, n_jobs=1) # DecisionTreeClassifier 모델로 Bagging Bootstraping 실행 # n_estimators 메서드는 생성할 모델의 수를 의미한다. # max_samples 메서드는 하나의 분류기에 들어갈 샘플의 비율을 의미한다. 0 ~ 1.0의 값을 넣어 비율을 설정할 수 있고, 직접 갯수를 입력할 수도 있다. # bootstrap 메서드 값을 False로 지정하면 Pasting 모델이 적용된다. # n_jobs는 사용할 컴퓨터의 코어 수를 의미한다. -1을 지정하면 컴퓨터의 모든 코어를 사용한다. bagging.fit(X_train, Y_train) y_pred = bagging.predict(x_test) print(accuracy_score(y_test, y_pred)) >>> 0.9555555555555556
하지만 굳이 배깅 분류기에 결정트리 모델을 적용할 필요는 없다.
사이킷런에서는 배깅을 적용한 DecisionTree 앙상블 모형을 제공하는데, 이게 그 유명한 랜덤 포레스트이다.
쉽게 말해서 랜덤 포레스트를 쓰면 된다는 얘기다.
2-2. 랜덤 포레스트(Random Forest)
랜덤 포레스트는 여러개의 결정트리를 활용한 대표적인 Bagging 방식의 알고리즘이다.
따라서 RandomForest 모델은 BaggingClassifier와 DecisionTreeClassifier의 매개변수를 모두 가지고 있다.
계속해서 다뤘던 iris 데이터를 바탕으로 랜덤 포레스트 모형을 구축해봤다.
from sklearn.ensemble import RandomForestClassifier rnf = RandomForestClassifier(n_estimators = 1000, max_leaf_nodes = 16, max_samples=0.5, n_jobs = 1, bootstrap=True) # 배깅 분류기와 마찬가지로 n_estimators는 생성할 모델의 수를 의미한다. # max_leaf_nodes 메서드는 결정트리에 생성할 노드의 최대 갯수를 의미한다. # n_jobs는 사용할 컴퓨터의 코어 갯수를 의미한다. -1을 지정하면 모든 코어를 사용 rnf.fit(x_train,y_train) y_pred_rf = rnf.predict(x_test) print("rnd_model : ",accuracy_score(y_pred_rf,y_test)) >>> rnd_model : 0.9555555555555556
예측값을 보면 알 수 있듯이 위의 배깅 분류기를 사용했을 때와 랜덤 포레스트를 사용했을 때의 예측값이 같음을 확인할 수 있다.
이는 당연한 것이 서로 같은 모델이기 때문이다.
모델을 생성할 때의 매개변수 값을 동일하게 적용시키면 같은 예측값이 나와야 정상이다.
랜덤 포레스트 모형은 다음과 같이 설명할 수 있다.
- 알고리즘에서 트리의 노드를 분할할 때 전체 특성에서 최적의 특성을 탐색한다.
- 무작위로 데이터를 추출하여 탐색하기 때문에 최적의 특성에 무작위성을 더한다.
- 즉 트리의 다양성을 확보하면서 분산을 최소화함으로써 최적의 모델을 생성한다.
2-3. 편향과 분산, Extremely Randomized Tree
랜덤 포레스트에서 트리를 무작위하게 생성하는 과정을 극대화한 Extremely Randomized Tree 모델이 있다. 결정트리 모델이 각 노드에서 최적의 임계값을 찾는 과정은 일반적으로 시간이 오래 걸리는 특성 중 하나이다.
그럼에도 랜덤 포레스트 모델은 앙상블 모델 중 비교적 시간이 빠른 모델인 것으로 알고 있다.
Extremely Randomized Tree 모델은(이하 Extra-tree모델) 이를 생성하는 시간이 랜덤 포레스트 모델보다도 빠르다.
일반적으로 개개의 결정트리 모델은 편향(bias)이 큰 경향을 보인다. 앙상블 모형, 그 중에서도 Bagging 방식의 앙상블 모형은 수집 알고리즘을 통과하면서 편향이 감소하는 경향을 보인다.
랜덤 포레스트 모형의 경우 알고리즘을 거치면서 편향은 손해보는 대신 분산을 감소시켜 더 훌륭한 모델을 만드는 것을 목적으로 한다. 물론 그렇다고 하더라도 일반적으로 개별 분류기보다는 편향이 작다는 특성을 가진다.
편향과 분산에 대한 설명은 아래의 블로그 링크를 참고하면 더 이해하기 쉽다.
머신러닝 알고리즘에서의 편향과 분산
RandomForest에서의 편향과 분산
- 편향 값이 증가한다는 것은 예측값이 정답으로부터 멀어진다는 것을 의미한다.
앙상블 모형 중 Bagging의 방식을 사용하는 모델은 알고리즘을 거치면서 개별 예측기보다 편향이 감소된다.- 분산 값이 증가한다는 것은 예측값들이 퍼진 정도가 커진다는 것을 의미한다.
분산이 크다는 것은 모형의 설득력이 떨어진다고 평가할 수 있다.- 랜덤 포레스트 모형은 트리의 노드를 탐색하는 과정에서 편향을 조금 손해보면서 분산을 감소시킴으로써 더 훌륭한 모델을 만들어내는 것을 목적으로 한다.
- Extra-tree 모형은 랜덤 포레스트 모형에서 트리의 무작위성을 극대화한 것으로, 편향은 더 늘어나지만 분산을 더 감소시킨다.
2-4. RandomForest의 하이퍼 파라미터
랜덤 포레스트의 또 다른 특성으로는 하이퍼 파라미터 값이 많아 튜닝하는데 시간이 걸린다는 점이 있다. 특히 Extra-tree와 성능을 비교할 때 파라미터 값을 수정해가며 어떠한 모델의 성능이 더 좋은지 평가해야 하는 것이 필요하다.
물론 하나하나의 값을 지정해가며 편향과 분산 등의 값을 조정할 수도 있지만 사이킷런에서 제공하는 그리드 서치 함수(GridSearchCV)를 사용하여 조금 더 편리하게 최적의 값을 튜닝할 수 있다.
from sklearn.model_selection import GridSearchCV params = { 'n_estimators' : [10, 100, 1000], 'max_depth' : [6, 8, 10, 12], 'min_samples_leaf' : [8, 12, 18], 'min_samples_split' : [8, 16, 20], 'max_leaf_nodes' : [8, 12, 16, 2] } rnf = RandomForestClassifier(random_state = 22, n_jobs = 1) grid_cv = GridSearchCV(rnf, param_grid = params, cv = 3, n_jobs = 1) grid_cv.fit(x_train, y_train) print('최적 하이퍼 파라미터 :', grid_cv.best_params_) print('최고 예측 정확도 : {:.3f}'.format(grid_cv.best_score_)) >>> 최적 하이퍼 파라미터: {'max_depth': 6, 'max_leaf_nodes': 8, 'min_samples_leaf': 12, 'min_samples_split': 8, 'n_estimators': 1000} >>> 최고 예측 정확도: 0.971
물론 그렇다고 해도 GridSearchCV 과정 자체의 시간이 오래 걸리기 때문에(파라미터 값으로 지정한 경우의 수를 모두 실행하기 때문) 소요되는 시간에 관한 문제는 여전히 남아있다.
2-4. Feature Importance
트리 기반의 모델은 각 변수의 특성 중요도를 측정하기가 쉽다는 특징이 있다. 사이킷런에서는 학습이 끝날 때 각 특성의 점수를 측정하여, 모든 특성의 중요도를 합하면 1이 되도록 feature_importances 변수에 저장한다.
import seaborn as sns import pandas as pd import matplotlib.pyplot as plt df = pd.DataFrame(columns = iris['feature_names']) lst = [] for name,importance in zip(iris['feature_names'],rnf.feature_importances_): print(name,' : ',importance) lst.append(importance) >>> sepal length (cm) : 0.104943731405476 sepal width (cm) : 0.010301467392751893 petal length (cm) : 0.43825285771168193 petal width (cm) : 0.44650194349009 lst = sorted(lst) plt.title('Feature importances') sns.barplot(y=iris['feature_names'],x=lst)
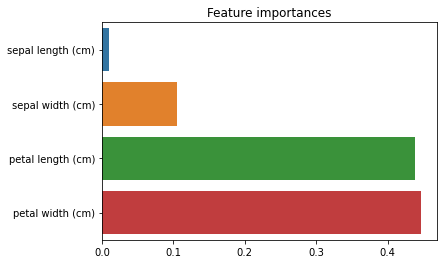
모델을 생성할 때 어떠한 특성(변수)가 모델에 큰 영향을 주었는지 확인할 수 있다.
Feature importance는 다음에 다룰 부스트 방식의 앙상블 모형에서도 사용할 수 있다. 다음 글에서는 앙상블 모형 중 Boosting 방식에 대해 알아보고자 한다.
