
데이터크롤링
데이터 크롤링이란 인터넷 상의 다양한 웹 페이지나 소스코드를 자동으로 탐색하고 정보를 수집하는 프로세스를 말한다.
📌HTML
HTML(Hyper-Text Markup Language)은 웹사이트를 만들때 사용되는 마크업 언어이다.
📍HTML 태그
- 웹 페이지를 구성하는 기본적인 구성 요소
– HTML 문서에서 요소의 성격을 지정하거나 페이지의 구조를 결정하는 역할을 한다.
<a href=“https://www.naver.com”>네이버로 이동</a>a : 태그 명
href : 속성 (태그의 종류에 따라 사용할 수 있는 속성이 다르다)
📍태그의 종류
- 제목 태그 : h1 ~ h6
- 본문 태그 : p
- 문단 태그 : div
- 링크 태그 : a
- 목록 태그 : ul, ol, li
- 이미지 태그 : img
- 입력 태그 : input
📍requests
- HTTP 프로토콜을 이용하여 웹 사이트로부터 데이터를 송수신할 수 있
는 Python 라이브러리이다.
import requests📍beautifulsoup
- 웹 페이지의 HTML, XML 파일에서 데이터를 추출하는 Python 라이
브러리이다. - HTML 태그를 검사하고 선택할 수 있다.
from bs4 import BeautifulSoup📍CSS 선택자
-
CSS(Cascading Style Sheets) 선택자는 HTML 요소를 스타일링하거나 특정 요소를 선택할 때 사용한다.
-
클래스 선택자는 ‘class’ 속성을 기반으로 요소를 선택한다.
‘.클래스명’
-
아이디 선택자 ‘id’ 속성을 기반으로 요소를 선택한다.
‘#아이디명’
📌뉴스 제목 크롤링
response = requests.get('https://m.search.naver.com/search.naver?where=m_news&sm=mtb_jum&query=%EC%BA%A0%ED%95%91')
html=response.text
#print(html)
soup = BeautifulSoup(html, 'html.parser')
news = soup.select('.news_tit')
#print(news)
for i in news:
title = i.text
link = i['href']
print(title, link)
제목과 링크 크롤링
import requests
from bs4 import BeautifulSoup
# 검색어 입력
search = input("검색어를 입력하세요: ")
for page in range(1, 4):
#입력할 검색어를 넣어서 url 저장
url = f"https://m.search.naver.com/search.naver?where=m_news&sm=mtb_jum&query={search}&start={page * 10}"
#requests를 통해 url에 전송하기 -> reponse 저장
response = requests.get(url)
#html에 response로 나온 정보를 test화하여 불러오기
html = response.text
#BeautifulSoup 객체 생성 = HTML 문서를 파싱하고 탐색할 수 있는 도구를 제공
soup = BeautifulSoup(html, 'html.parser')
# CSS 선택자를 이용해 원하는 요소를 선택
news = soup.select('.news_tit')
print(f"------------------------")
for i in news:
title = i.text
link = i['href']
print(title, link)

📌상품 정보 크롤링
G마켓(https://www.gmarket.co.kr/)에서 사용자가 검색한 상품
의 정보를 엑셀 파일로 저장한다.
📍openpyxl
- 파이썬에서 엑셀 파일을 쉽게 다루기 위한 오픈 소스 라이브러리
- 엑셀 파일 형식을 읽고 쓰는 기능을 제공하며, 파이썬 코드를 사용하여
엑셀 파일의 데이터를 조작할 수 있다.
!pip install openpyxl
import openpyxlimport requests
from bs4 import BeautifulSoup
wb = openpyxl.Workbook()
ws = wb.create_sheet('posco')
ws['A1'] = '상품명'
ws['B1'] = '가격'
ws['C1'] = '링크'
# 검색어 입력
search = input("검색어를 입력하세요: ")
#입력할 검색어를 넣어서 url 저장
url = f"https://browse.gmarket.co.kr/search?keyword={search}"
#requests를 통해 url에 전송하기 -> reponse 저장
response = requests.get(url)
#html에 response로 나온 정보를 test화하여 불러오기
html = response.text
#BeautifulSoup 객체 생성 = HTML 문서를 파싱하고 탐색할 수 있는 도구를 제공
soup = BeautifulSoup(html, 'html.parser')
# print(soup)
# CSS 선택자를 이용해 원하는 요소를 선택
flower = soup.select('.box__information-major')
for i in flower:
title = i.select_one('.box__item-title')
title_b = title.select_one('.text__item')['title']
price = i.select_one('.box__item-price')
price_b = price.select_one('.box__price-seller')
price_c = price_b.select_one('.text__value').text
link = title.select_one('.link__item')['href']
print(title_b,price_c,link)
ws.append([title_b,price_c,link])
wb.save(r'C:\Users\gram\anaconda3\Untitled Folder\crawlingtest.xlsx')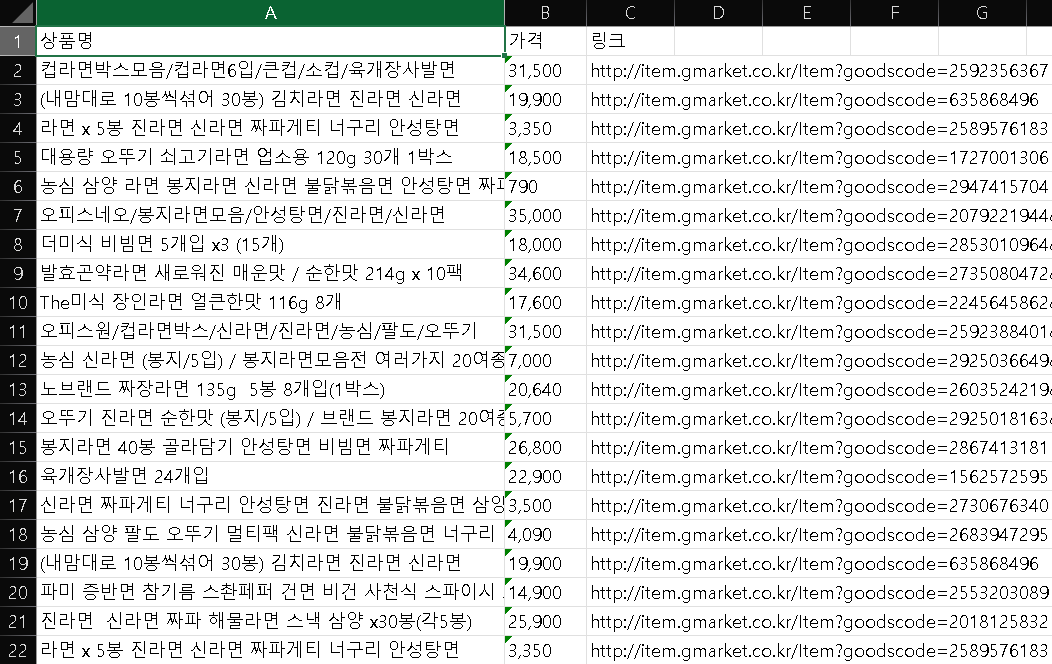

성공의 반대는 실패가 아닌 도전하지 않는 것이다.