
싱글 쓰레드인 Node 이벤트 루프 환경에서 비동기 처리를 지원하는 libuv의 백그라운드 쓰레드 수와, 이를 실행시키는 CPU 코어 수와의 상관관계를 알아보려고 한다.
오해
"Node는 싱글 쓰레드니까, CPU 코어 개수랑 상관없이 성능은 일정해요!"
라고 생각했었는데, 비동기 처리 함수는 백그라운드 쓰레드를 사용하니까 코어수와 상관 관계가 있지 않을까? 생각했었던 것에서부터 이 검증과정을 시작했다.
결과
결론은 코어개수랑 상관이 있다!! 코어가 많을 수록, Background Thread를 병렬로 처리할 수 있게 된다.
코어가 많아질 수록 성능이 올라가는 것은 이해가 되는데, 백그라운드 쓰레드를 많이 설정하면 성능이 올라갈까?
그렇지 않다. 바로 Context Switching의 비용때문이다. 자세한건 테스트를 보며 설명하겠다.
테스트 환경
테스트 로직
테스트할 함수는 다음과 같다.
const argon2 = require('argon2');
const start = Date.now();
async function asyncArgon(){
const promises = [];
for (let i = 0; i < 4; i++) {
promises.push(
console.log(`Start hash1 ${i}`),
console.log(`Start hash2 ${i}`),
argon2.hash('1234567').then(hash => {
console.log(`Hash ${i}:`, hash);
console.log(`Time hash done:`, Date.now() - start);
})
);
}
await Promise.all(promises);
console.log('All tasks completed');
console.log(`Time :`, Date.now() - start);
// 무한 루프로 컨테이너가 종료되지 않도록 함
setInterval(() => {
console.log('Keeping the container alive...');
}, 10000); // 10초마다 메시지를 출력
}
asyncArgon();- 왜 argon2를 사용했어요?
뚜렷하게 실행시간의 차이를 보고 싶어서 선택하였다. 시간을 좀 많이 잡아먹는 마땅한 함수가 hash함수니까! 내부적으로 crypto 라이브러리를 사용해서 libuv 쓰레드풀을 사용하게된다. https://www.npmjs.com/package/argon2 - 왜 console.log를 앞에 두번 찍었어요?
console.log 출력시 결국 I/O가 발생하게 되고, 이에 따라 프로세스, 스레드가 block되어 context switching이 일어나는지 보고싶어서 그랬다. (근데 알고보니 console.log는 비동기함수라고 한다 걱정할 필요없다!) - 왜 Interval을 사용했어요?
함수 실행후 컨테이너를 죽게 냅두고 싶지 않아서, 무한 루프를 돌게 하였다.
환경 조성 (도커)
기본적으로 CPU코어 수, libUV thread 수를 변인으로 Node 런타임 환경을 실행해야한다. 로컬에서 테스트하게 되면, 컴퓨터의 코어수를 그대로 사용할 것이므로 검증이 힘들다.
깔끔하게 테스트하기 위한 좋은 방법은 도커를 활용해서 CPU의 수를 제한을 주는 방법이다. (물론 가상서버 하나 파서 테스트해보면 되지만 굳이..?)
정의한 도커파일은 다음과 같다.
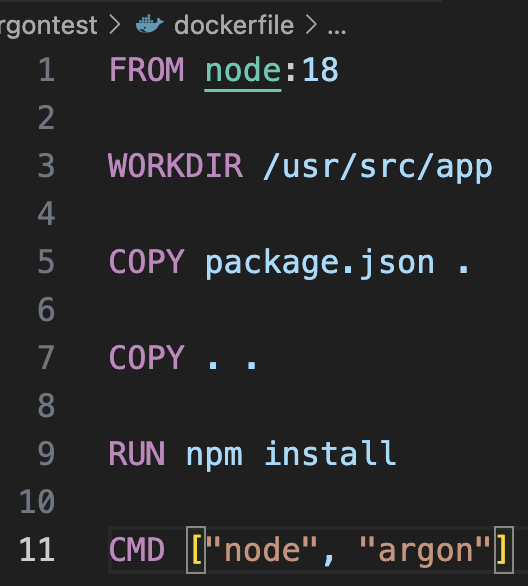
여기서 node 버전을 local에서 돌려본 node 버전이랑 맞추자. 안그러면 버전 이슈로 실행되지 않는다.
또한 libuv thread수와 cpu수를 환경변수로 일일이 넘겨야 하므로, 이 환경변수는 컨테이너를 실행시킬 때 넘기기로 하자.
테스트 실행
단일 코어
- CPU '1' 개 libuv 쓰레드 개수 default '4'개
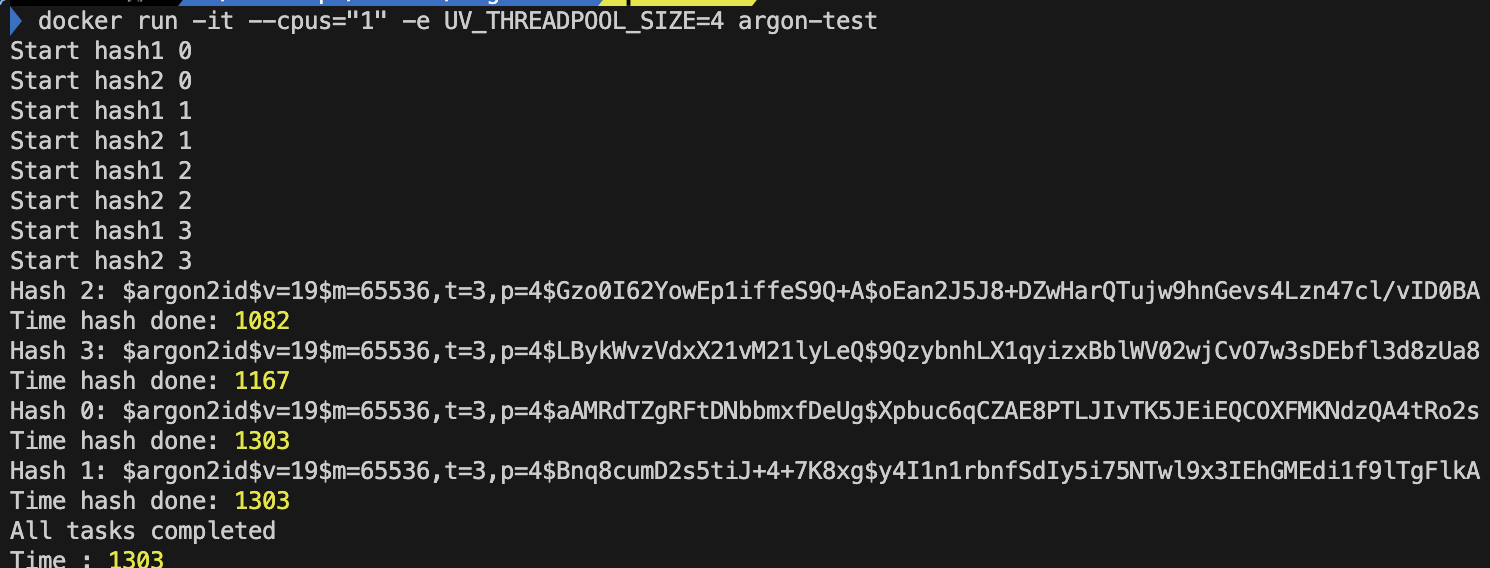
- 4개의 병렬 처리된 비동기 친구들이 거의 동시에 끝났다. 4개의 hash함수는 비슷하게 1초정도 걸렸다.
- 시작 순서와 다른 종료 순서를 볼 수 있다. CPU가 4개의 libuv 쓰레드를 번갈아 실행하면서 종료 순서가 뒤바뀐 것이라고 추측할 수 있다.
- CPU '1'개, libuv 쓰레드 개수 '2'개
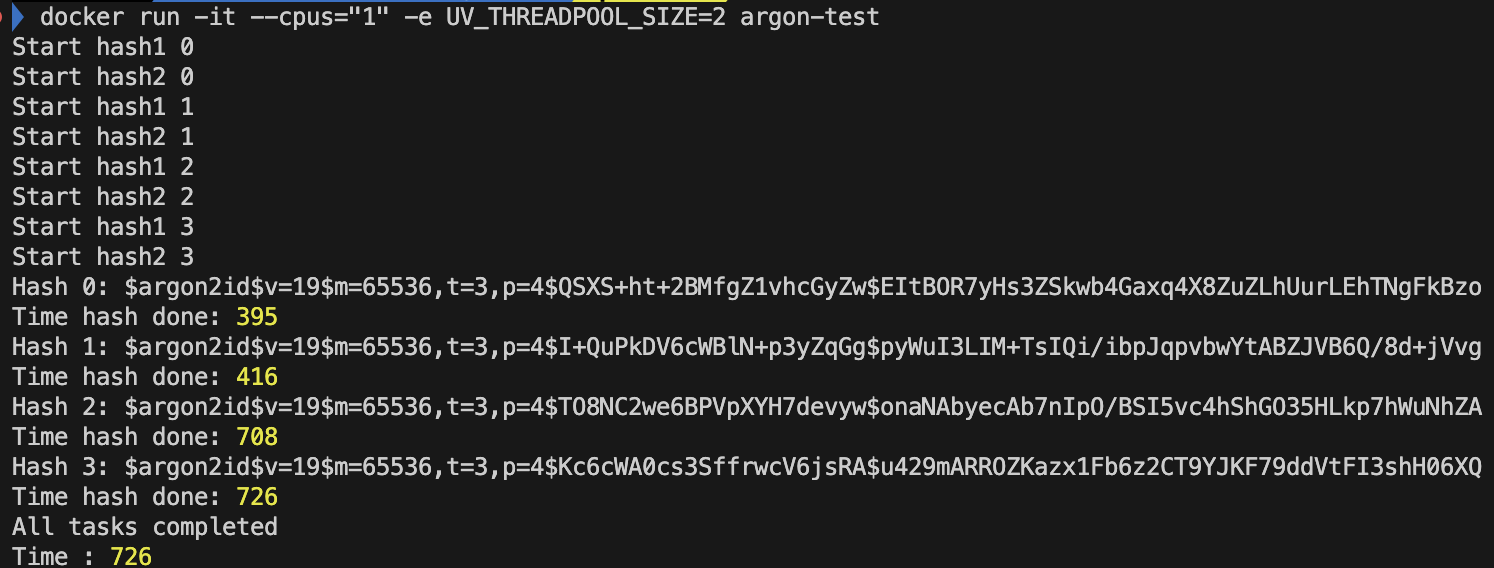
- 2개의 쓰레드이다보니, 처음 두개는 거의 동시에 끝나지만, 그 이후 두개는 앞의 두개의 쓰레드가 끝나고 실행되는 것을 볼 수 있다.
- CPU '1'개, libuv 쓰레드 개수 '1'개
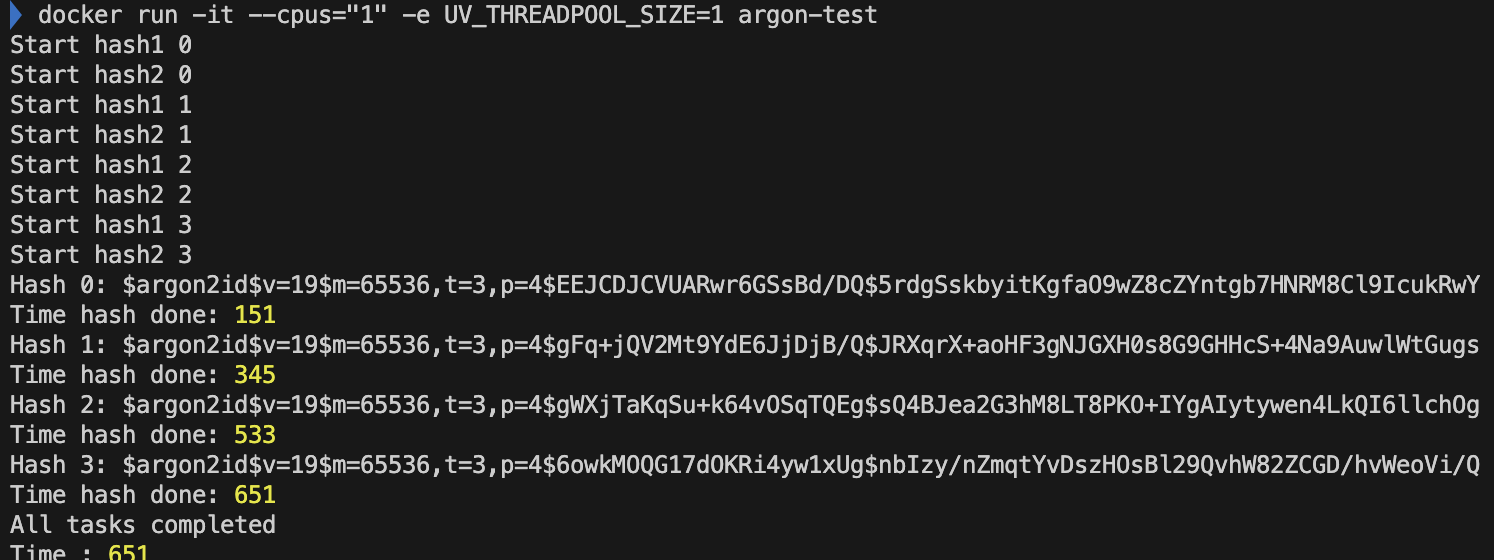
- 병렬로 처리되는 백그라운드 쓰레드는 단 하나이다. 이 경우에는 병렬이 의미가 없어진다. 즉, context switching이 발생하지 않는다는 뜻이다. context switching이 발생하지 않으므로, 이에 해당하는 overhead가 줄어들어 hash 실행 시간이 줄어든 것으로 알 수 있다.
2 Core
- CPU '2' 개 libuv 쓰레드 개수 default '4'개
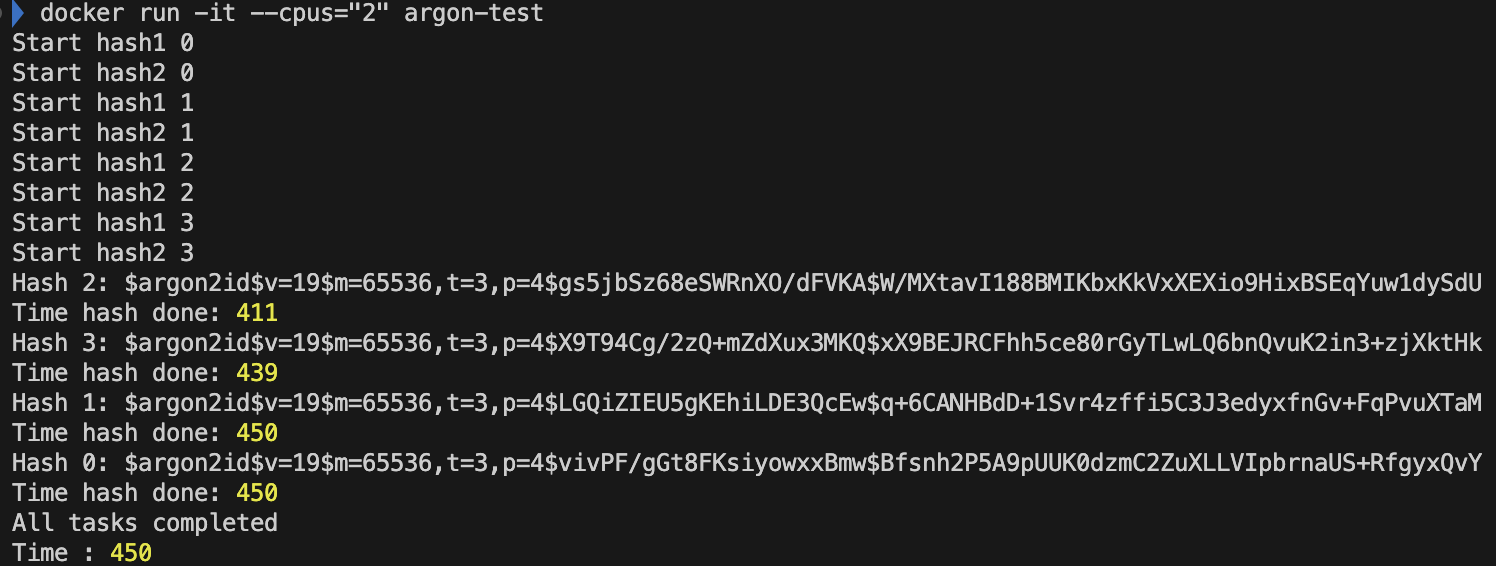
- 오! CPU 1개 였을 때보다, 시간이 반 이상 줄어든 것을 볼 수 있다! 이유는? 두개의 코어가 하나의 쓰레드를 각각 병렬적으로 처리하면서 반이 줄어들었다고 볼 수 있다.
- CPU '2' 개 libuv 쓰레드 개수 '2'개
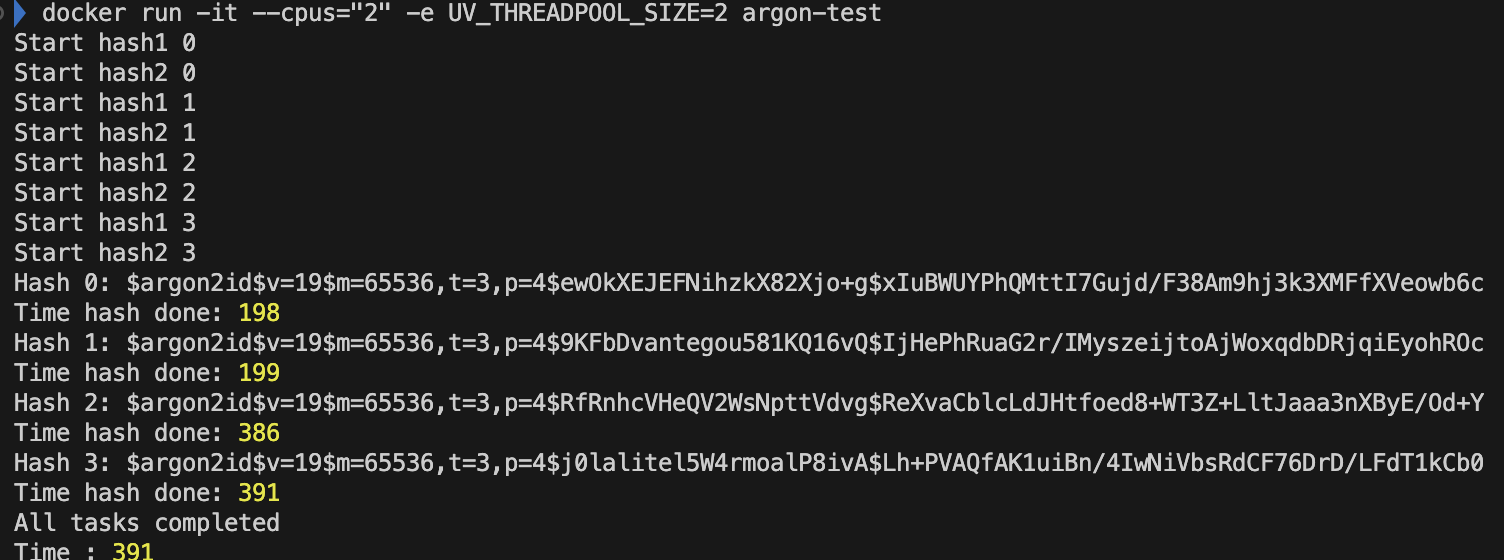
- 비동기로 처리할 libuv 쓰레드 개수가 2개이므로, CPU코어 두개는 parallel하게 쓰레드를 실행한다. 그 이후에, 뒤이어 도착한 쓰레드를 실행한다.
- CPU '2' 개 libuv 쓰레드 개수 '1'개
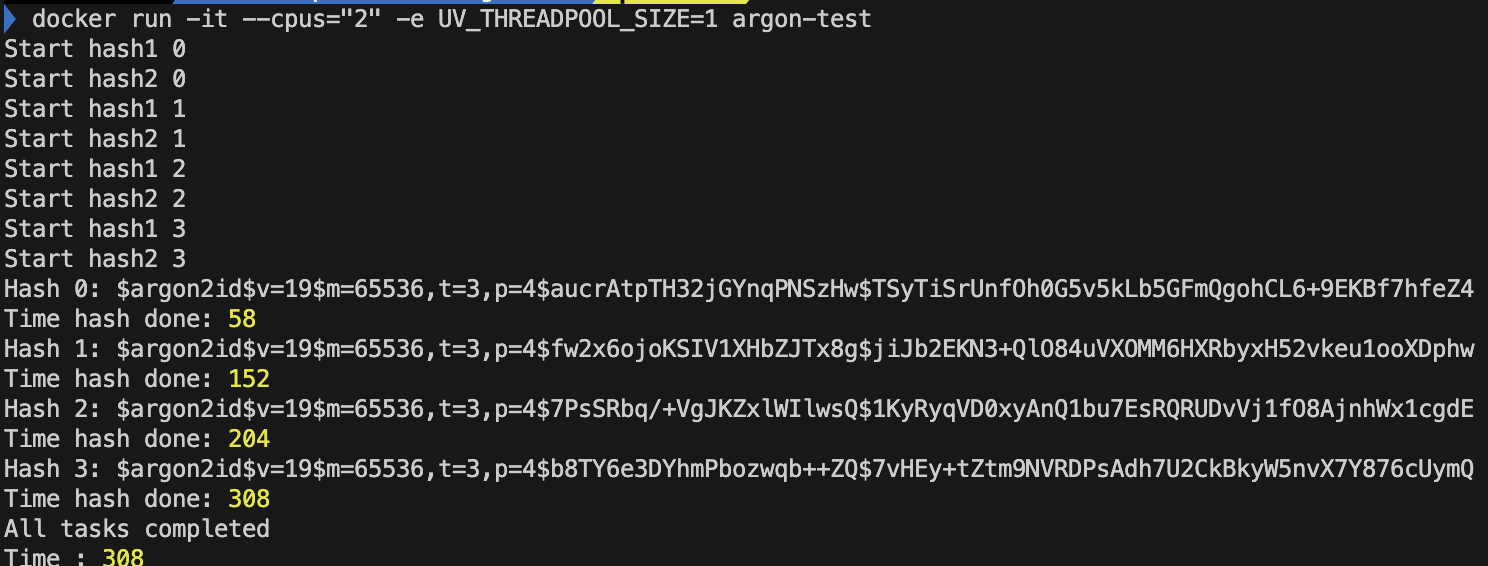
- 비동기로 병렬적으로 처리할 쓰레드가 1개밖에 없어서.. 이런.. 코어 하나는 남아돌겠다. 하지만 CPU 개수가 1개였을 때보다 성능이 올랐다. 이유는 무엇일까? 싱글 쓰레드의 이벤트 루프도 처리해야했기 때문이다. 즉 CPU가 1개였을 때에는 사실상 event loop 담당 쓰레드와 백그라운드 스레드 2개가 컨텍스트 스위칭한다. 하지만 CPU 2개를 사용하면서 성능이 개선된다.
4 Core
- CPU '4' 개 libuv 쓰레드 개수 default '4'개
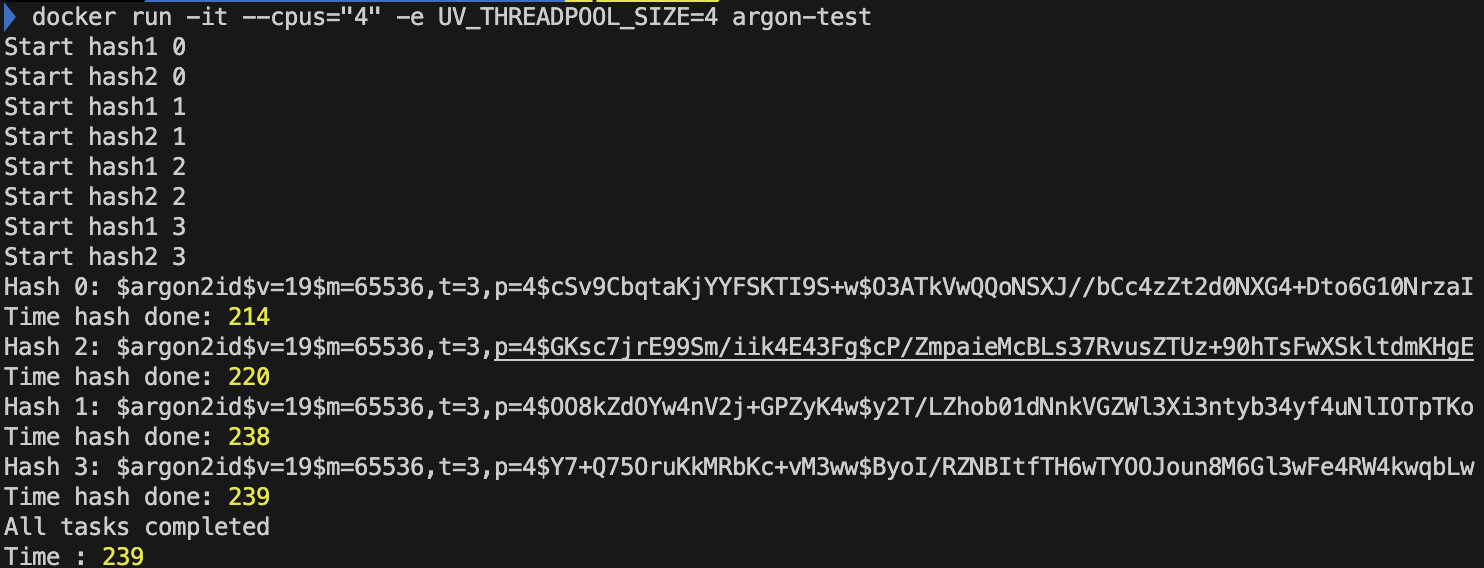
- CPU '4' 개 libuv 쓰레드 개수 '2'개
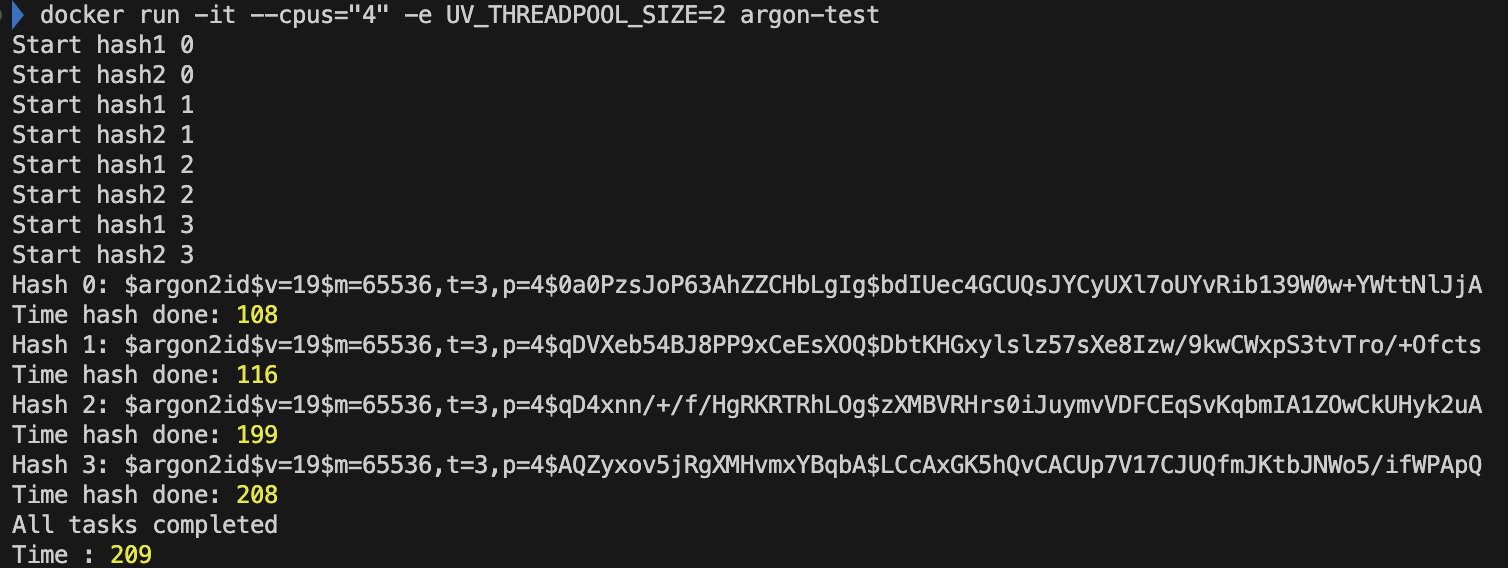
- CPU '4' 개 libuv 쓰레드 개수 '1'개
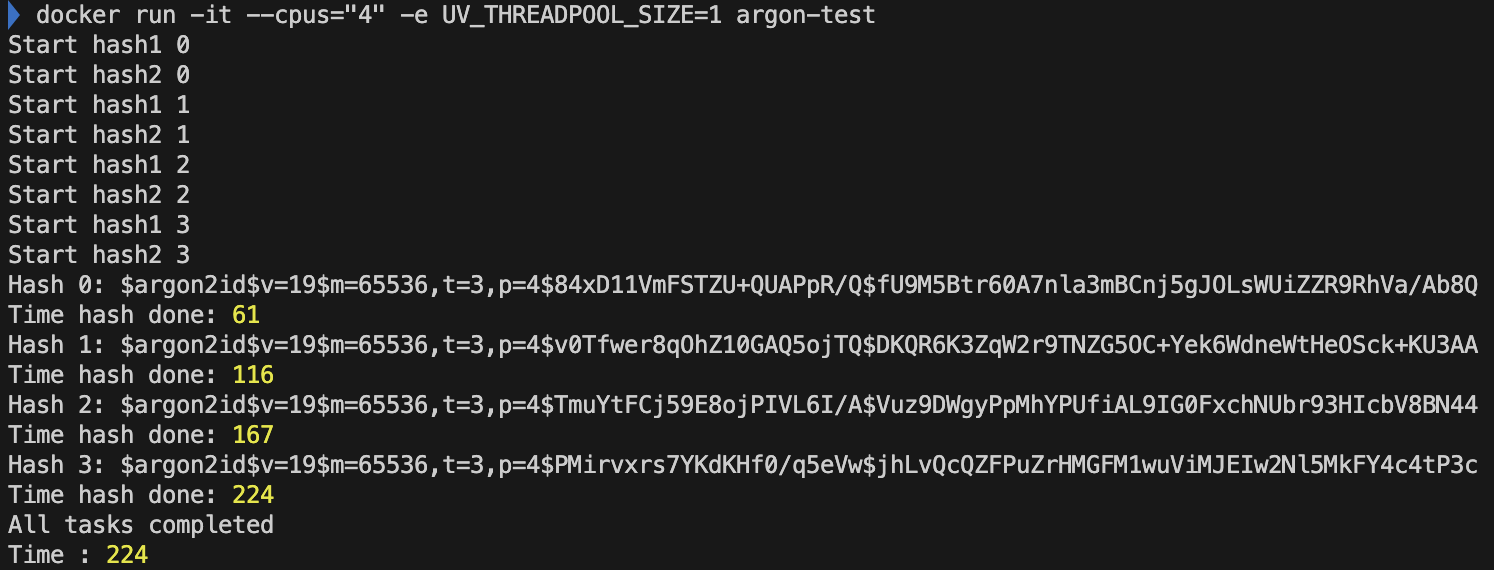
UV_Thread 개수를 늘리면? 성능이 무조건 향상된다? (코어 1개)
먼저 hash함수를 100번 시키도록 바꿔봤다.
const argon2 = require('argon2');
const start = Date.now();
async function asyncArgon(){
const promises = [];
for (let i = 0; i < 100; i++) {
promises.push(
console.log(`Start hash1 ${i}`),
console.log(`Start hash2 ${i}`),
argon2.hash('1234567').then(hash => {
console.log(`Hash ${i}:`, hash);
console.log(`Time hash done:`, Date.now() - start);
})
);
}
await Promise.all(promises);
console.log('All tasks completed');
console.log(`Time :`, Date.now() - start);
// 무한 루프로 컨테이너가 종료되지 않도록 함
setInterval(() => {
console.log('Keeping the container alive...');
}, 10000); // 10초마다 메시지를 출력
}
asyncArgon();- 쓰레드 수 4

- 쓰레드 수 8

거진 두배차이의 시간이 걸린다. 즉 쓰레드가 많을 수록, 컨텍스트 스위칭이 발생해서 문제가 발생한다. CPU코어수가 2개일 경우엔 어떨까?
UV_Thread 개수를 늘리면? 성능이 무조건 향상된다? (코어 2개)
- 쓰레드 수 4

- 쓰레드 수 8
 약간 개선된다.
약간 개선된다. - 쓰레드 수 2
 흠.. 결과가 신기하다.
흠.. 결과가 신기하다. - 쓰레드 수 1

대부분의 경우에는 쓰레드의 수가 늘어나면, 성능이 하락된다. 이유가 무엇일까 - 쓰레드 수 32개
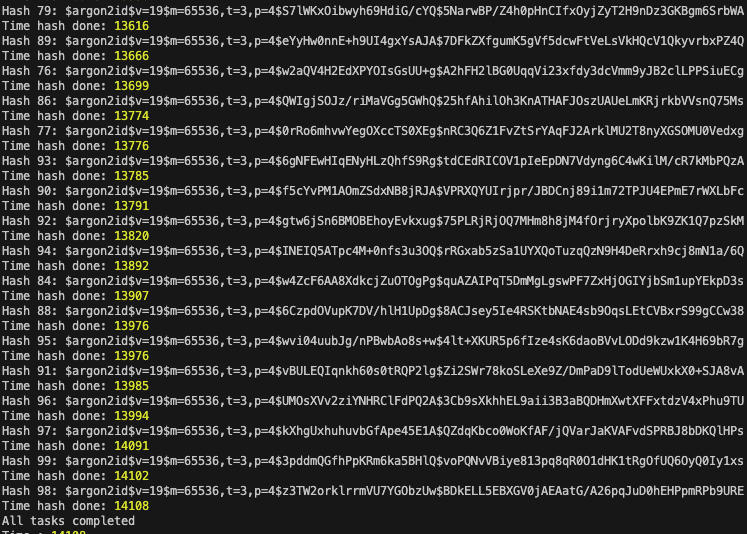
이번에는 신기하게도, 쓰레드의 처리 순서가 뒤죽박죽인 데에다가, 성능이 더욱 안좋아졌다.
CPU-Bound 작업의 비동기 작업?
CPU-Bound한 작업들이 오래동안 CPU를 사용해야 함 + Context Switching 비용이 매우 늘어나면서 시간이 지연되었다고 추측이된다.
정해진 Time Quantum을 실행은 해야겠는데, 한번 실행되어야할 쓰레드는 오랜시간을 잡아먹어서 시간이 지나 다시 thread switching이 일어나고, 이에 따라 switching비용이 발생되었다고 추측된다.
결국 CPU-Bound한 작업들은 Thread의 수로 조절하다기 보다는, Core의 개수로 조절하는게 맞지 않을까 싶다.
Network I/O?
CPU-Bound가 아닌 I/O Bound의 작업이라면 어떨까?
I/O Bound는 libuv의 백그라운드 쓰레드를 사용하지 않는다. 그래서 쓰레드의 수랑도 상관이 없다. 이 친구는 kernel의 비동기 작업에 맡겨서, 메인 쓰레드에 영향을 주지 않는다고 한다.
https://www.youtube.com/watch?v=qCC56uJh3bk&list=PLC3y8-rFHvwh8shCMHFA5kWxD9PaPwxaY&index=42
따라서, asynchronous한 작업들이 kernel에서 async하게 작동하는지, libuv 쓰레드에서 async하게 작동하는지는 어떠한 Job을 하는지에 따라 다르다. 이는 libuv의 내부 구조를 뜯어보면 알 수 있을 것 같다.
정리
background thread pool을 사용하는 async작업들은 Core에 영향을 받지만, 그렇지 않은 작업들은 OS Kernel에게 이관되므로, Core와 Thread에 영향을 받지 않는다.

와 저도 오늘 이거 비슷한 주제로 유튜브 영상 봤는데 후덜덜...
자매품으로 cpu-bound하지 않은 작업(network I/O)은 core나 thread_pool size를 늘려도 성능이 향상되는가? 도 있습니다