동아리에서 개발중인 온라인 코딩 채점 플랫폼 '코드당' 에서 겪은 문제 상황 및 가설입니다.
1. 문제상황
오늘, 학생들이 코드당 서비스에 회원가입을 진행하던 도중에 서버가 죽어버리는 문제가 발생했다. Grafana에서 Log들을 확인해봤을 때, 여러 Error 로그들이 찍혀있는 것을 확인하였다. 하지만, 이러한 Error들은 이미 백엔드 서버에서 Handling작업이 이루어졌기 때문에, 이러한 에러들 때문에 서버가 죽을일은 없었다.
그래서 Metric을 확인해보았다. 하지만 현재 Metric정보들은 Container 별로 측정하고 있긴 하지만, '사용량'만 나타낼뿐, Container에 할당된 Memory Usage를 비율로 보여주고 있지 않아서, 문제를 알아내는 것이 쉽지 않았다.
그래서, ECS의 컨테이너들을 호스팅하는 EC2서버에 직접 들어가서
docker ps -a로 죽어있는 컨테이너까지 확인해보았다.
그랬더니, 문제가 되었던 백엔드 서버 컨테이너에서 Exited(137)이 적혀있었다.
찾아보니, 해당 오류는, 도커 Memory를 전부 사용해서 발생한 문제라고 한다. (도커 OOM) 이라고 한다.
재차 확인해보고자, AWS Cloud Watch를 들어가서 살펴보았다.
그리고 ECS에서 문제가 생겼던 Service의 Metric 정보를 살펴본 결과
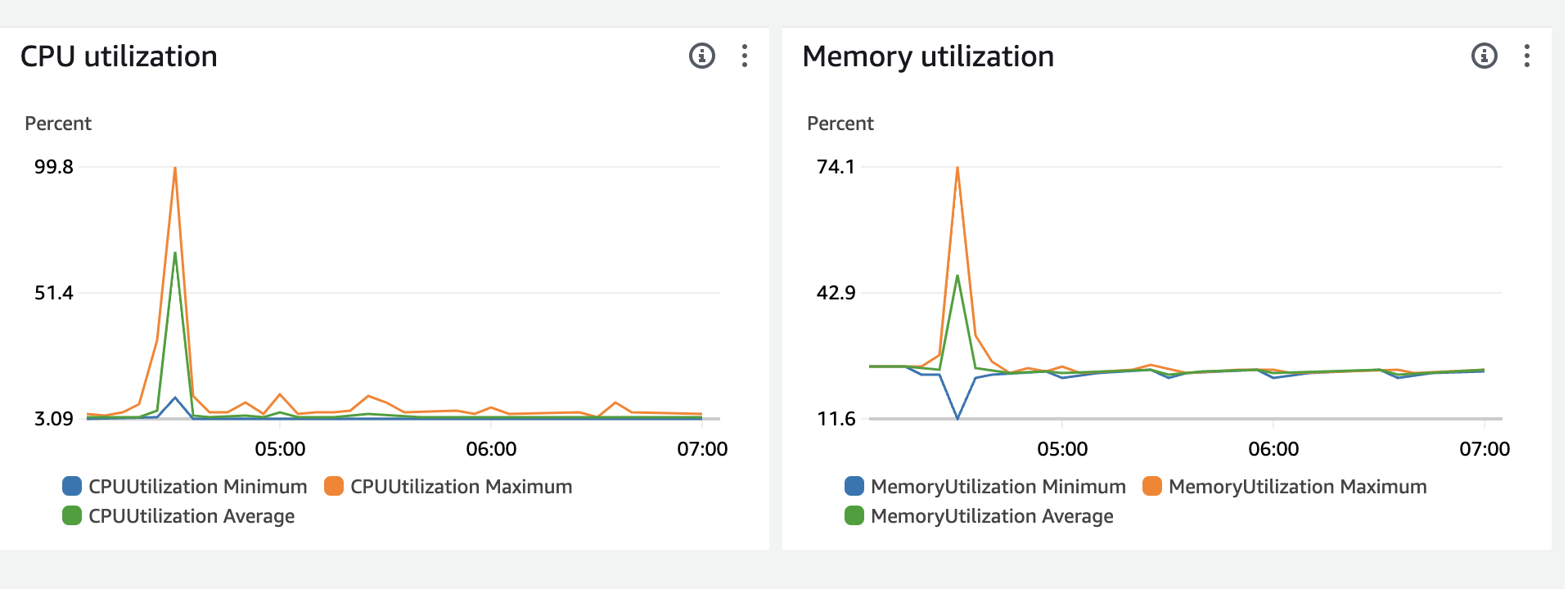 다음과 같이 CPU가 99%를 찍은 것을 볼 수 있다.
다음과 같이 CPU가 99%를 찍은 것을 볼 수 있다.
분명 우리의 그라파나에서는 문제가생긴 13:33분 경, CPU사용률이 99%로 나오지 않았다.. (100%-idle) = 60%쯤..
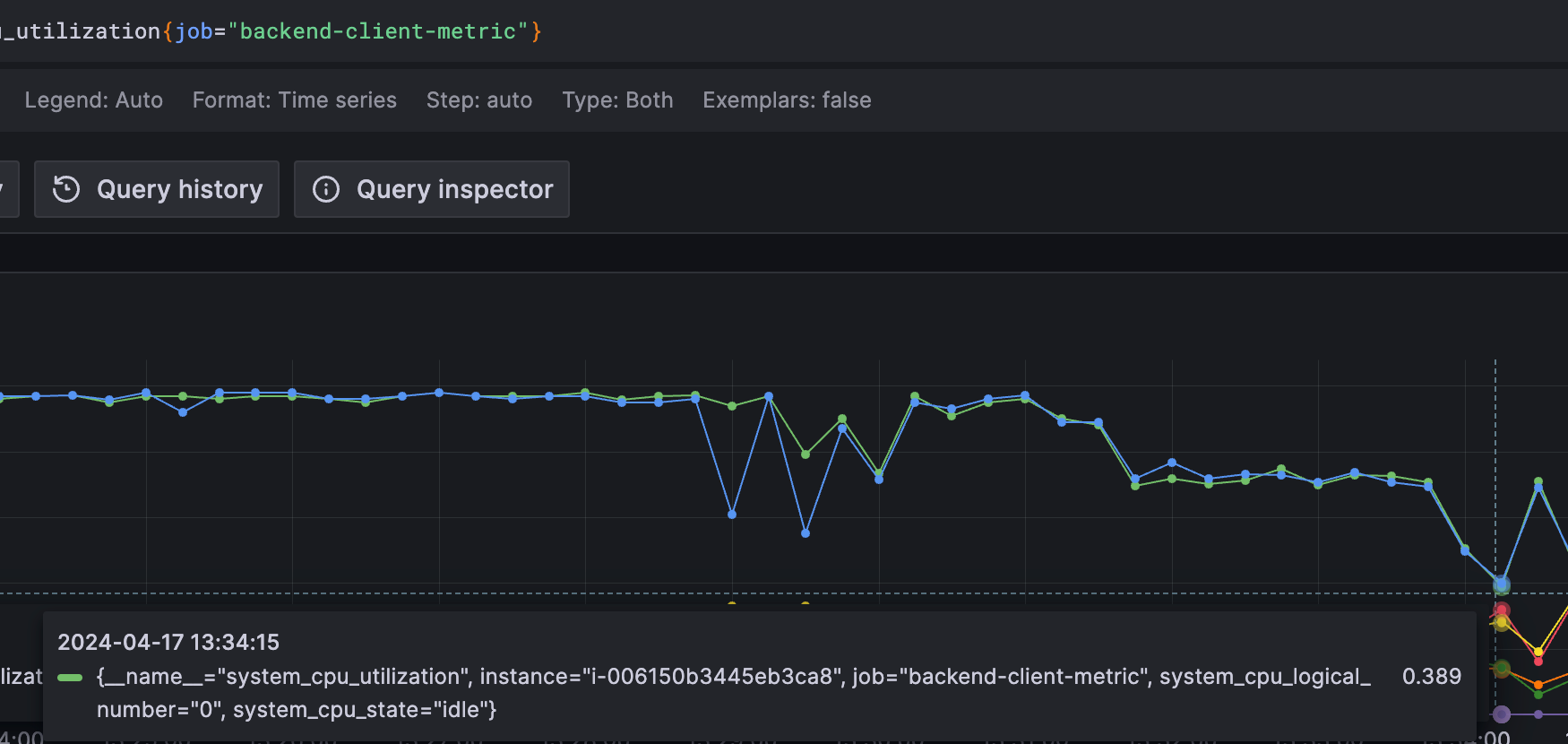
그래서 Exited(137)의 원인을 살펴보니 두가지이다.
현재 우리 서비스의 컨테이너를 관리하는 주체는 AWS ALB와, ecs-agent 컨테이너이다. 따라서 일반적인 Exited(137)의 문제상황과 다를 수 있다.
아래 StackOverflow에서 두가지의 원인을 추측할 수 있었다.
https://stackoverflow.com/questions/46282928/aws-ecs-exit-code-137
- Task Definition으로 컨테이너에 할당된 메모리 사용량을 초과해서 사용해서 컨테이너가 죽었다.
- Task Definition으로 컨테이너의 할당된 CPU를 99%찍고나서 컨테이너가 죽었다.
동아리원이 알아본 바에 의하면, 컨테이너 사용 CPU가 99%를 찍고 죽은 것이 아니고, Container들을 hosting하는 ec2 instance가 문제가 된 task의 실행 속도를 늦추는 방식으로 동작하는 것을 알게되었다. 그래서 들어온 Health check 리퀘스트들을 유효한 시간내에 처리하지 못해 Time Out이 발생하여 task가 죽었다고 판단하였다고 한다.
위 두가지의 경우이다.
그리고 그 이후에 ECS Event Log들을 살펴보니까,
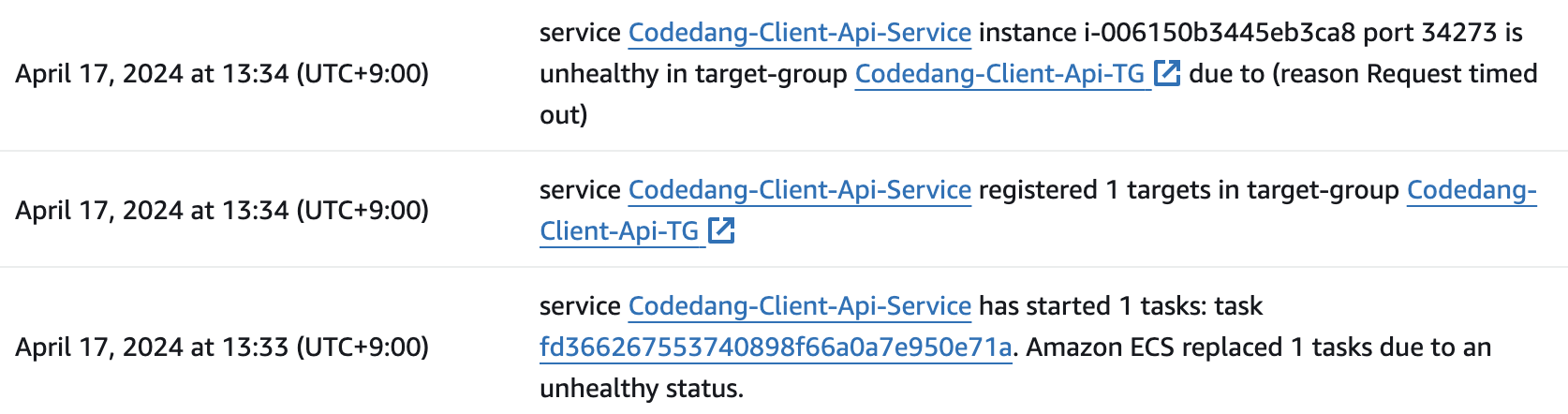
ALB 에서 Health check 안됨 -> 죽었다고 체크함 -> ecs-agent가 해당 컨테이너 Exit 시키고 재실행하였다.
Cloud Watch가 정확하다고 하다면, 2번일 확률이 크다. 왜냐하면 Memory사용량이 99%가 찍힌 적이 없고, CPU가 99%였기 때문이다.
더불어, 우리의 그라파나 시스템의 부정확도 또한 개선해야 한다.
Cloud Watch는 ECS service 단위로 Metric을 수집하는 반면, 우리의 그라파나는 그렇지 못한다. 이러한 것들 때문에 정확도가 떨어지는 것 같다.
2. 해결방법 (추측)
(1) Task Definition에서 해당 컨테이너 (혹은 Task) 에 CPU할당량을 높인다.
회원가입의 트래픽을 하나의 Container가 감당하지 못한다는 것은 큰 문제가 있다. 기본 컨테이너에 할당된 CPU를 높이자. (어쩌면 백엔드 로직에 문제가 있을 수도 있다.더불어, 한가지 요청에서의 로그가 10개 이상씩 쌓이는 문제도 있다. 로그 IO 문제일 수도 있다.)
(2) CPU Reservation 설정 및, Task Scaling up
또한, 컨테이너를 호스팅하는 EC2의 CPU Reservation에 따라 Scaling Up되는 것을 꺼두었는데, 이를 다시 켜두도록 하자!
