성균관대 코딩 채점 플랫폼 '코드당' 서비스의 변경된 아키텍쳐를 정리/인수인계 문서를 남깁니다.
인프라의 구성 방법이 아닌 구성이유와 지식에 대해 다룹니다.
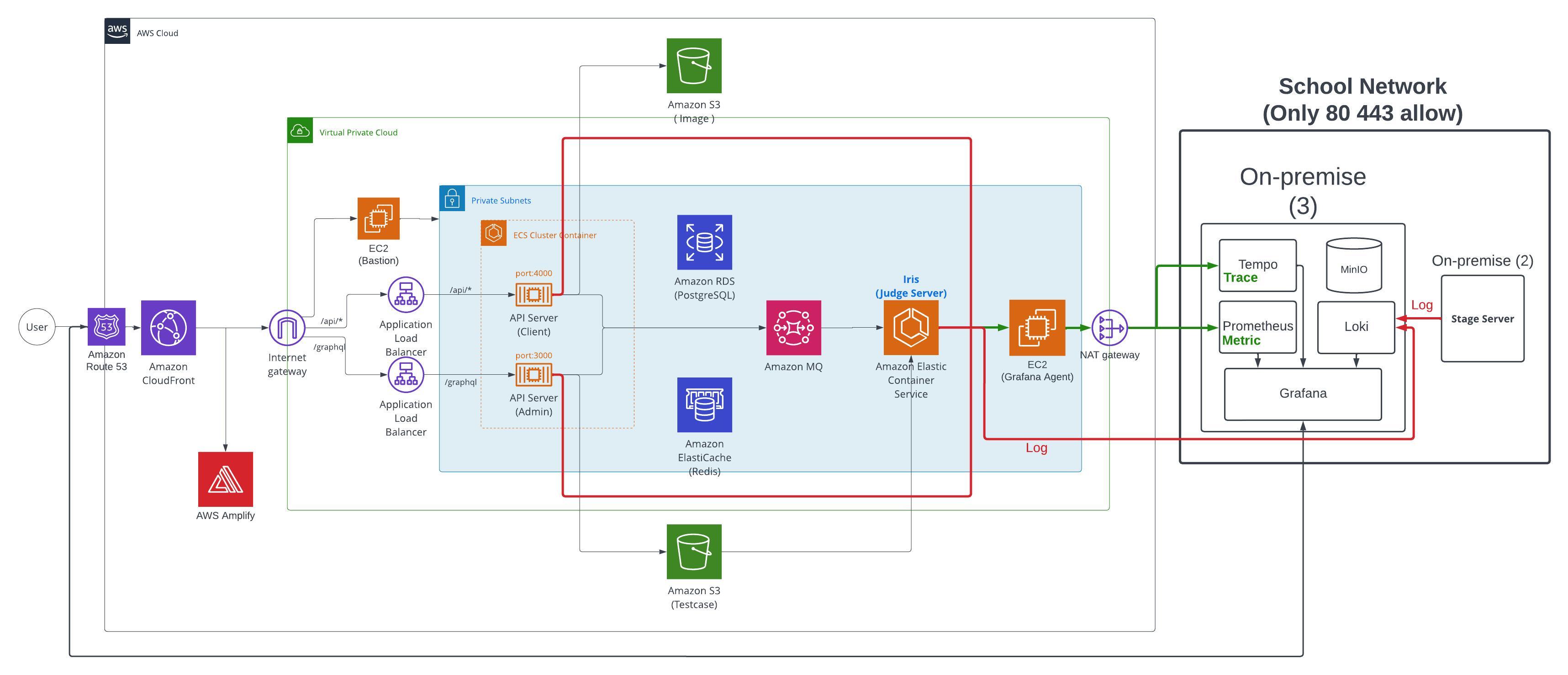
0. 아키텍쳐 사진
1. CloudFront & Route53
CloudFront
사용자가 컨텐츠를 빠르게 받아볼 수 있게 하는 AWS서비스인 CloudFront가 Infra의 시작점입니다.
일명 CDN(Contents Delivery Network)이라고도 합니다. CloudFront에 등록된 Origin Name을 통해 Domain Name을 하나로 통일할 수 있게 됩니다.
1. 캐싱
CloudFront는 사용자의 위치와 가장 가까운 Edge Server에 컨텐츠를 저장,캐싱하고 이를 사용자에게 내려주는 역할을 합니다. 이를 통해 특정 웹페이지나 이미지등의 정적 컨텐츠, 혹은 동적 컨텐츠 중 API Response를 캐싱할 수 있습니다. 더불어 동적 컨텐츠의 네트워크 최적화(DNS Lookup 등등..)과 같은 과정을 통해 전송 속도를 증가시킵니다.
2. 보안
- ACM을 활용한 SSL인증서를 손쉽게 처리할 수 있습니다.
- 특정 지역 (대륙)의 접근을 제한할 수 있습니다.
- (Signed URL) 특정 URL로만 CloudFront의 컨텐츠에 접근할 수 있게 합니다. 단, 파일 '하나'만 가능합니다.
- (Signed Cookie) 특정 쿠키 헤더가 포함된 요청이어야만 CloudFront의 컨텐츠에 접근할 수 있습니다. 이 경우 다수의 컨텐츠에 접근할 수 있습니다.
- (Origin Access Identity) S3의 컨텐츠에 접근할 때, S3 endpoint가 아닌, CloudFront를 통해서만 가능하게 설정할 수 있습니다. 이는 S3를 CloudFront에 등록할때 설정합니다.
3. 동작 원리
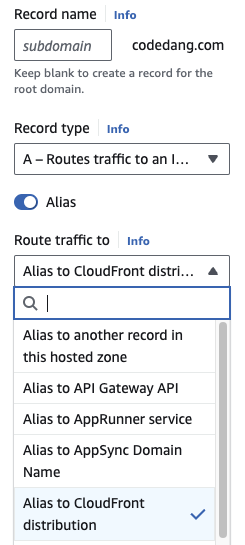
사용자가 Route53의 등록된 Domain Name으로 요청하였을 때, Route53에서 CloudFront에 등록된 URL로 라우팅합니다.
아래 사진처럼 Route53의 레코드를 등록할 때, CloudFront Distribution을 Alias(별칭)으로 등록 가능합니다.
CloudFront에는 아래와 같이 Cache Behaviors(동작) 경로를 설정할 수 있는데, Precedence 순으로 Pattern의 캐싱 경로를 확인하고 각 Origin으로 캐싱 요청을 보냅니다.
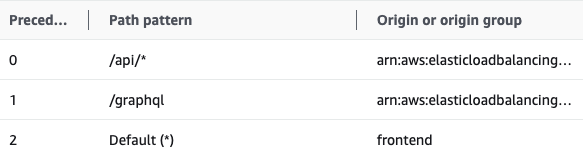
캐싱 요청의 의미가 모호하게 들릴 수 있는데, 이는 캐싱을 허용할 Http Method나, 캐싱 유효 기간의 Time To Live(TTL)정보를 포함한 요청을 보내는 것입니다. 그 후에는 Edge Server에 캐싱 정보가 저장이 될 것입니다. 그 후, 같은 pattern으로 요청이 오면 캐싱된 정보를 제공합니다. 만일 (Cache miss의 예시로) TTL이 만료되면, 다시 Origin으로 캐시 요청을 보내겠죠?
4. 우리 서비스의 동작 과정
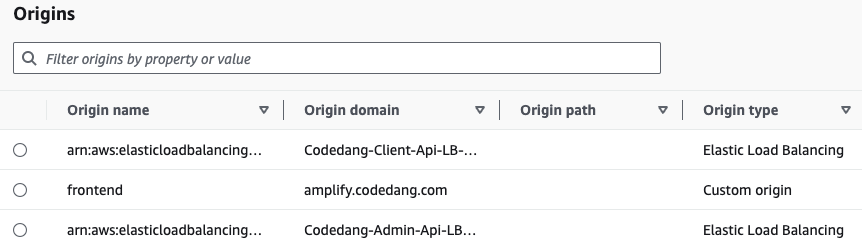 이는 CloudFront에 설정된 Origin 서버 정보들입니다.
이는 CloudFront에 설정된 Origin 서버 정보들입니다.
Route53 에 codedang.com의 도메인 네임이 CloudFront의 도메인 네임으로 Routing 됩니다. 이후, 캐싱요청의 pattern이 /api(클라이언트 api서버), /graphql(admin api서버), frontend(amplify 배포 프론트엔드 서버)로 이루어지게 됩니다. 그후 캐싱이 되면 더이상 Origin 서버로 요청이 안가고 Edge server에 Cache hit 되어 바로 응답을 내려줍니다.
2. VPC
VPC는 Virtual Private Network의 약자로, 클라우드 사설 네트워크 환경입니다.
3. Internet Gateway, NAT Gateway, RoutingTable (Network 구성요소)
(1) Internet Gateway, VPC, Public Routing Table
외부에서 VPC내부의 서버에 접근을 하기 위해서는 반드시 Internet Gateway를 지나야 합니다. 이를 위해, VPC의 사설 IP주소 (10.0.0.0/16)와 Internet Gateway를 같은 라우팅 테이블에 포함시킵니다. Internet Gateway가 연결된 라우팅 테이블은 Public하다고 합니다. 저희 리소스들 중, 외부에서 접속이 가능해야하는 리소스들의 Subnet을 해당 Routing Table에 연결만 해주면됩니다.
- Public Routing Table 라우팅 경로
 Routing Table의 다음 패킷의 경로는 Longest Prefix Matching에 따라
Routing Table의 다음 패킷의 경로는 Longest Prefix Matching에 따라 10.0.으로 시작하는 Private IP의 경우 VPC내부(local)로 향하게 되고, 이외의 경우는 모두 Internet Gateway(외부)를 향합니다.
(2) NAT Gateway, Private Routing Table
NAT Gateway는 Private Subnet에 존재하는 Resource들로 하여금 외부와 통신할 수 있는 길을 만들어 줍니다. 하지만, 단방향입니다. 즉 내부에서 외부로 통신은 가능한데, 외부에서는 들어올 수 없습니다. NAT는 Network Address Translation의 약자로, 내부 사설 IP를 공인 IP로 바꾸는 역할을 합니다. 그러면 외부에서는 내부 IP를 알 수 없고, 리소스들이 Private Subnet에 위치하므로 데이터를 보낼 수 없습니다.
NAT Gateway가 공인 IP로 바뀌기 위해, Elastic IP를 고정적으로 할당해야 합니다. 따라서 NAT Gateway는 고정 IP할당을 위해서 Public Subnet중 하나를 선택해야합니다.
저희는 NAT Gateway를 활용하여 교내 서버에서 Log, Metric, Tracing정보를 수집하고 있습니다. 또한 NAT Gateway에 붙어있는 IP만 요청을 받게끔 설정해놓은 상태입니다.
- Private Routing Table 라우팅 경로
 이 라우팅 테이블에 Private Subnet을 모두 연결해주면 됩니다.
이 라우팅 테이블에 Private Subnet을 모두 연결해주면 됩니다.
4. ALB
앞선 CloudFront내용 /api/* 경로로 elb가 붙고, /graphql 경로로도 arn:aws:elasticloadbalancing이 붙었던 것을 확인할 수 있습니다. 그 주인공이 Application Load Balancer 입니다.
외부의 요청을 받아 ECS service의 task를 로드 밸런싱합니다.
5. ECS
저희가 사용하고 있는 ECS Cluster는 두개입니다.
- Api server
Client가 4000번 포트로 Admin이 3000번포트로 두가지 서비스가 돌고 있습니다. (붙어있는 alb가 다릅니다.) - Iris server
코드 채점이 시행되는 Go언어의 서버입니다. 이 서버에는 ALB가 붙어있지 않습니다. 이유는, Message Queue와 Connection을 맺고 있기 때문입니다. 즉, 외부에서 요청이 들어오는 것이 아닌, 내부 MQ만 바라보고 있기 때문에 어떠한 Port도 열려있지 않습니다.
알아두면 좋은 점 (과정 및 주의점)
(Task Definition은 이미 만들어 졌다고 가정합니다)
-
클러스터 생성
ECS의 클러스터를 만들 때, Launch Type(Capacity Provider) 및 해당 Launch Type의 Network 구성(VPC, Subnet, Security Group)을 설정합니다. -
서비스 생성
클러스터를 생성하면, Task를 실행할 가상 서버 설정만 완료된 상태입니다. 서비스를 생성할때, 그 외의 부분을 설정해야 합니다. (advanced한 설정으로 Capacity Provider 의 Strategy를 추가적으로 수립할 수 있습니다. 하지만 순정 Launch Type으로 충분합니다.)
(1) Application Type과 어떤 Task로 서비스를 실행시킬지 설정
(2) Load Balancer로 Task Definition에 Port가 열린 컨테이너중 어떤 컨테이너를 Balancing할 것인지 설정! (아래 사진 참고)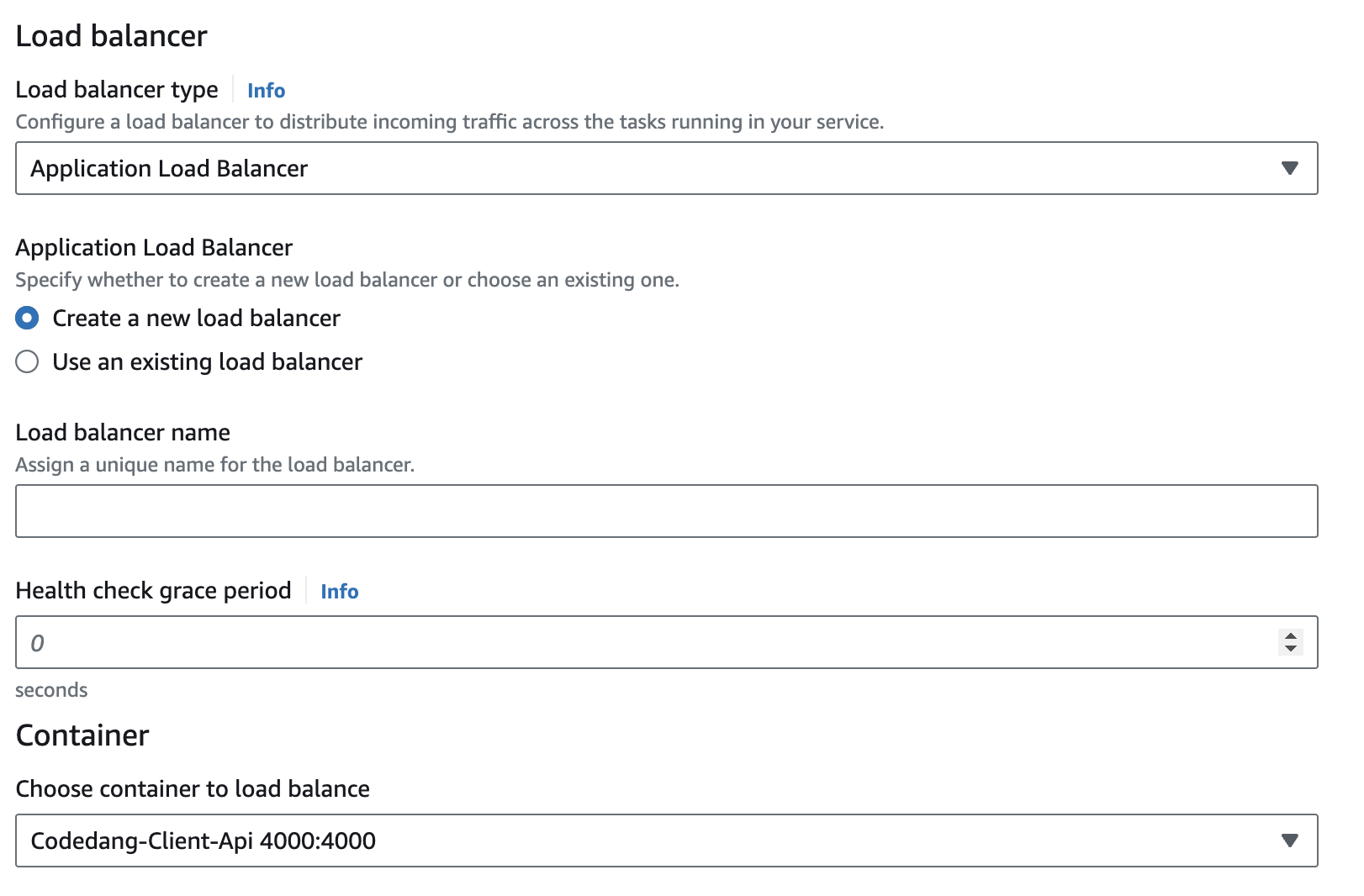 (3) Service AutoScaling
(3) Service AutoScaling
이 부분이 중요합니다. AutoScaling Group으로 ECS의 시작유형을 지정했지만, 이는 EC2(Task가 실행되는 주체)만 Scaling 된다는 점을 기억하셔야 합니다. 우리가 필요한 것은 Task들입니다. Task 없는 빈 EC2는 쓸모없습니다.
따라서 이 설정을 위해서 서비스를 생성하실 때, Service Auto Scaling 설정으로 Task의 수를 지정해주시면 됩니다.
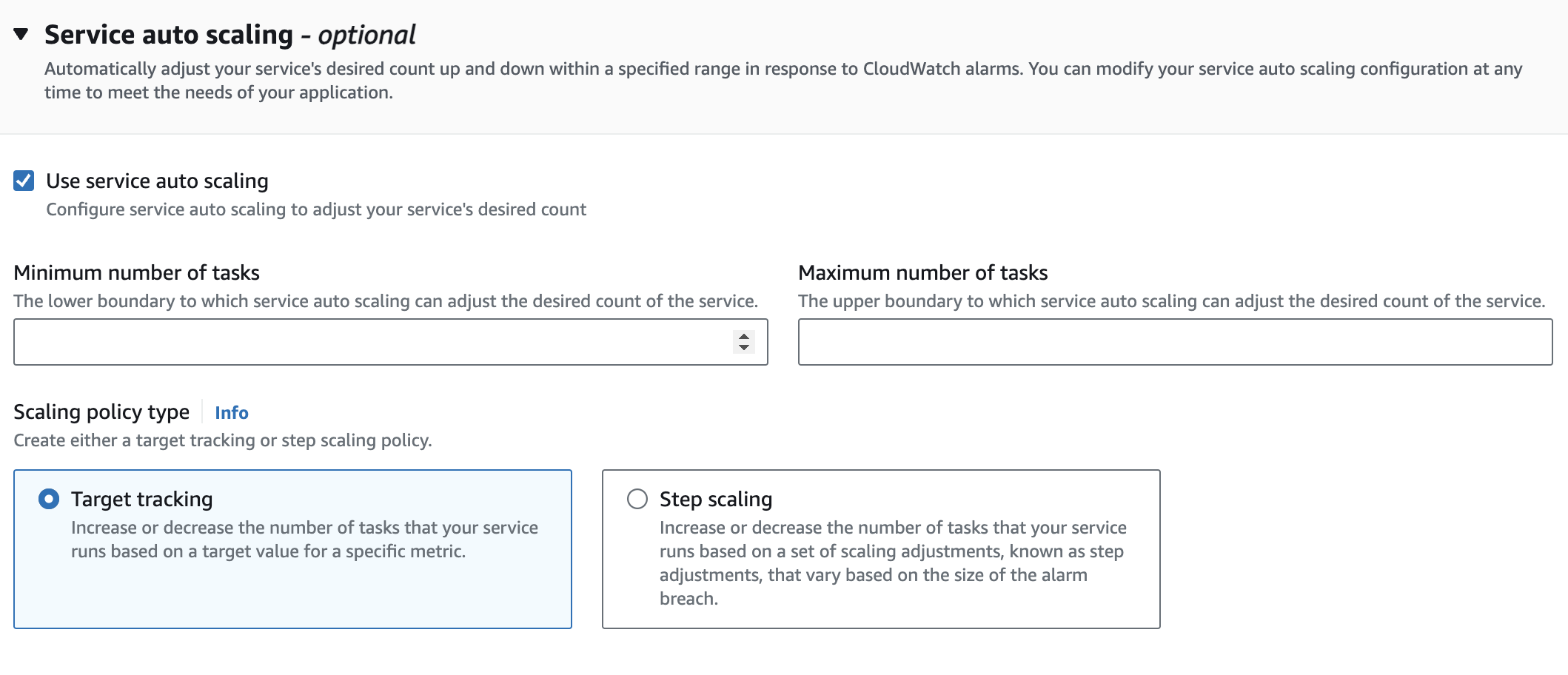
동작 원리
이렇게 설정하시면, Scale-Out시, Load Balncer가 Auto Scaling 된 'EC2'에 실행중인 'Task Container' 에 알아서 요청을 분산합니다.
주의점
"Task Definition으로 task의 컨테이너 port를 지정하면, 같은 EC2에서 service가 scale up될때, port가 충돌되지 않나요?"
의 답변은 다음과 같다.
ECS는 기본적으로 Dynamic Port Mapping을 지원한다. 중복을 피할 컨테이너의 Host Port를 0으로 지정하면 ECS가 알아서 동적으로 컨테이너의 포트를 호스트의 포트로 매핑하여 포트 충돌을 피하여 요청을 분산할 수 있다.
6. MQ
저희의 서비스는 코드 채점 서비스입니다.
코드 요청을 보내는 Client가 있고, 요청된 코드를 받아서 채점을 하고 처리결과를 Client에게 내려주어야 하는 채점 서버가 있습니다.
만일 MQ가 없이, 순수히 Client와 Server 두가지로만 통신한다고 생각해봅시다.
(1) 요청을 보냈는데 요청이 안와요
만일 요청을 보냈는데 Iris서버가 모종의 이유로 죽거나, Response가 오지않아 TimeOut이 났다면 어떻게 될까요?
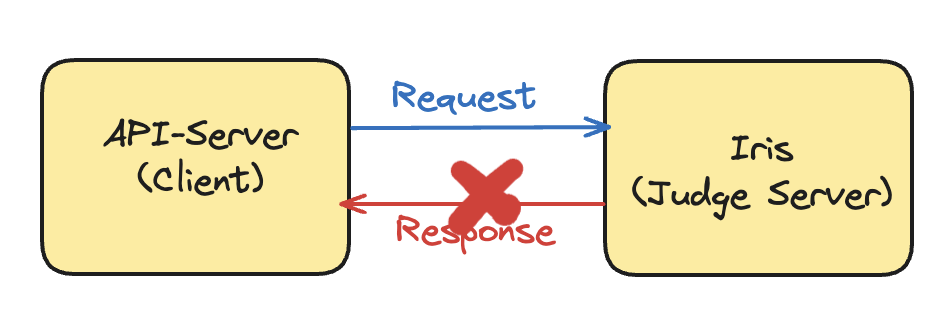 이러면, Client측에는 500 Error가 반환될 것이고, 이에 따라 다시 요청하는 방식으로 해결할 수 있겠지만, 영원히 죽는다면 계속 쌓이는 Request에 Client가 맛이 갈 확률이 큽니다. 또한, 중간에 갑자기 Iris가 살아난다고 해도, Synchronous하게 요청을 보내면 Iris서버가 해당 요청을 순서대로 처리하므로 결과를 받는데에도 큰 지장이 생깁니다.
이러면, Client측에는 500 Error가 반환될 것이고, 이에 따라 다시 요청하는 방식으로 해결할 수 있겠지만, 영원히 죽는다면 계속 쌓이는 Request에 Client가 맛이 갈 확률이 큽니다. 또한, 중간에 갑자기 Iris가 살아난다고 해도, Synchronous하게 요청을 보내면 Iris서버가 해당 요청을 순서대로 처리하므로 결과를 받는데에도 큰 지장이 생깁니다.
Asynchronous하게 보냈다고 해도, 채점서버가 죽어있는 동안 Client는 계속해서 요청을 보내어 데이터 순서가 보장이 안되거나, TTL 만료등의 이유로 데이터가 사라질 수도 있습니다.
(2) Scale-In/Out 에서의 처리
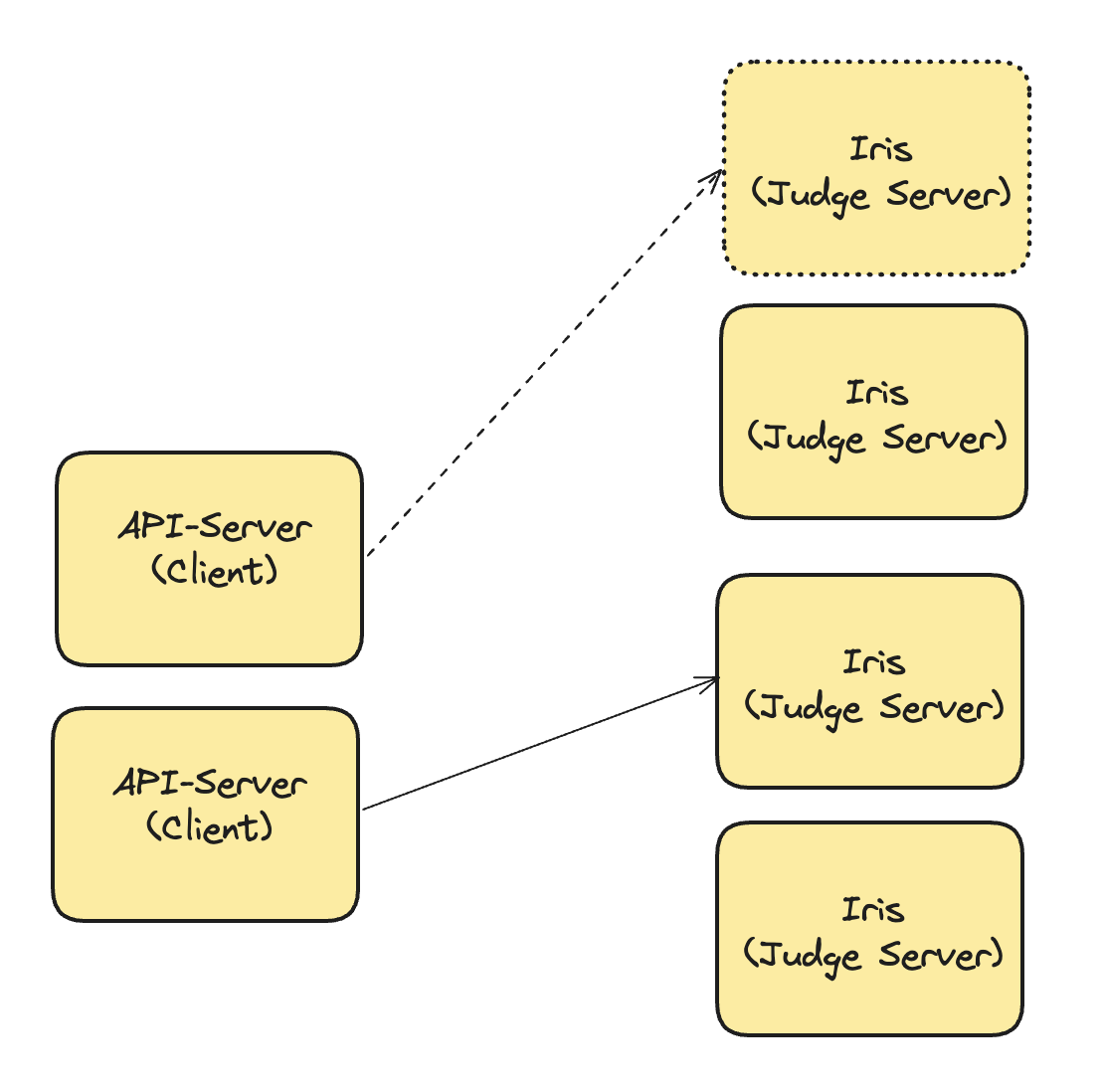
만일 위 상황처럼 Scale-Out 그리고 Scale-In이 되었다고 하면, Client측에서 이러한 서버 상황에 맞춰서 일일이 EndPoint를 수정해야 하는 상황이 발생합니다.
정리하면
만일 Client와 채점 Server만 존재한다면, 코드 요청을 보냈는데 코드 요청이 사라질 수도 있는, 데이터의 안전성이 떨어집니다. 또한 서버가 Scale-In Out시에 데이터를 송수신하기 위한 설정이 복잡합니다. 이를 해결하기 위해 Message Broker(Message Queue)가 필요합니다.
Message Queue의 역할
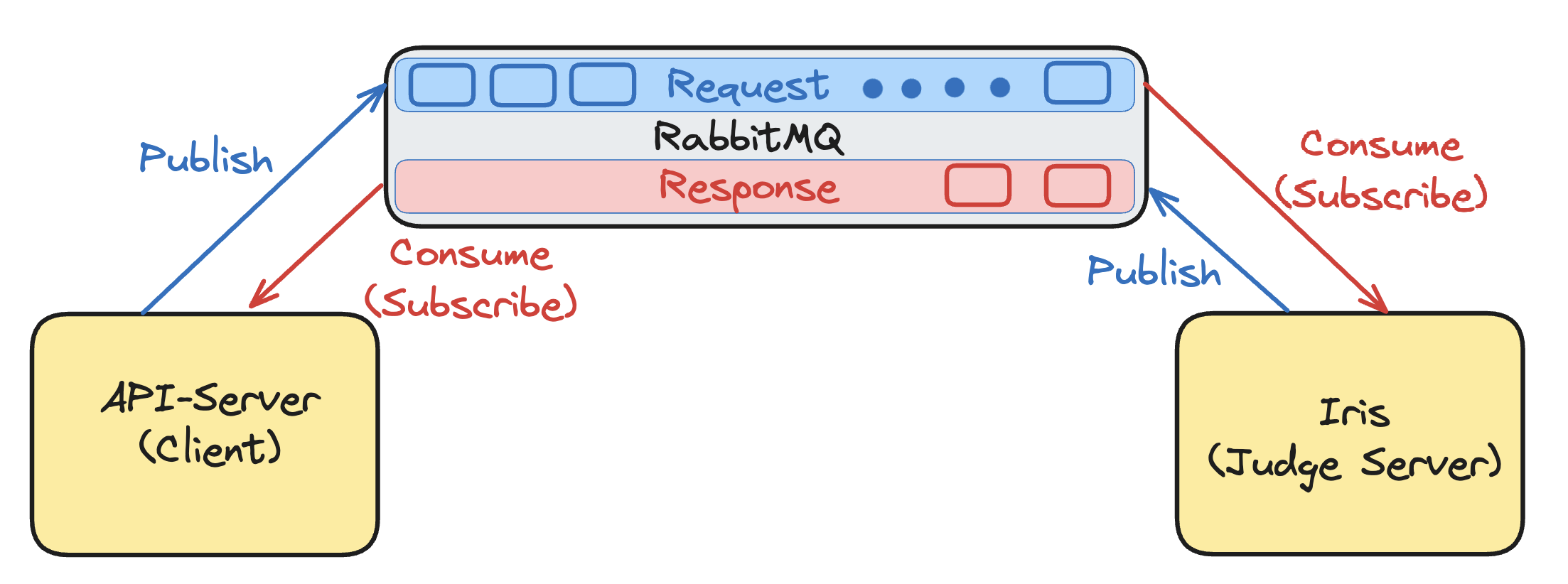
- Scale In/Out이 되어도 Client와 Server측 모두 RabbitMQ만 바라보면 됩니다.
- 채점서버가 죽어있어도, 클라이언트의 Request는 채점서버가 Request를 Consume할때 까지 Message Queue에 위치합니다. (데이터의 안전성과 순서를 모두 보장받습니다)
