딥러닝 파트를 시작하면서 전에 아무 생각없이 쓰던 adam optimizer, RMSprop에 대해 정리해보려고 한다. 딥러닝 모델을 만들면서 optimizer에 대해서 무지한채 사용만 해왔던 것 같다. 정말 많은 optimizer들이 있겠지만 그 중에서 가장 기본이 되는 Gradient Descent와 가장 많이 본 Adam optimzer와 RMSprop 총 3가지 optimzer에 대해 정리해볼 것이다.
Optimizer?
우선 optimzer란 무엇일까?
딥러닝에서 optimizer는 학습 알고리즘이라고 할 수 있다. 대부분의 optimizer는 미분을 통해 gradient(기울기)를 구하고 해당 방향의 반대방향으로 나아가면서 optimal minimum을 찾아가는 방식이다. 대표적으로 Gradient descent가 있고 이것을 바탕으로 성능을 업그레이드한 다양한 optimizer들이 있다.

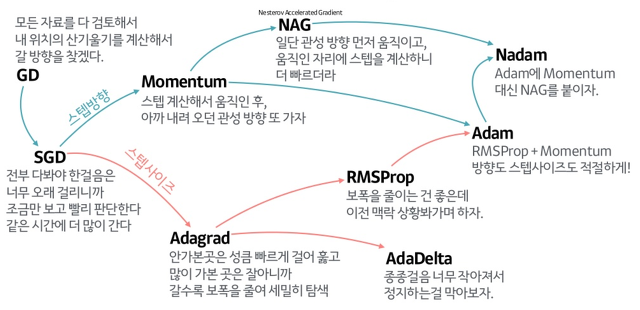
1. SGD(Stochastic Gradient Descent)
Gradient descent에는 loss function의 gradient를 구하는데 얼마나 많은 데이터를 쓰느냐에 따라 세 가지 종류가 있다.
- Batch Gradinent Descent
- Stochastic Gradient Descent
- Mini-batch Gradient Descent
한 번에 사용하는 데이터 양만 다르고 같은 방식으로 진행된다. Batch는 한 번에 모든 데이터를 사용, Stochastic은 한 개의 데이터씩 사용, Mini-batch는 batch size만큼 사용한다. 한 번에 사용하는 데이터가 커질때마다 training에 걸리는 시간은 줄어들지만 정확도는 낮아질 수 있다.
- 현재 weight들을 통해 나온 error 값(loss function 상의 점이 될 것)에서 gradient(기울기)를 구한다.
- gradient의 반대 방향(음수)으로 이동 시킨다. 이때 learning rate를 통해 한 번에 얼마나 이동할 지 정한다.
- 위 과정을 반복하여 loss function의 값이 최소가 되는 weights들을 구한다.
2. RMSprop
RMSprop은 다른 optimizer인 Adagrad의 단점을 보완하기 위해 제안된 것이다. Adagrad는 변수의 업데이트 횟수에 따라 learning rate를 조절하는 옵션이 추가된 것이다 (learning rate decay). 그리고 Adagrad는 각 step의 모든 gradient에 대한 제곱의 합이다. 계속해서 gradient를 누적하여 descent가 진행되는 것이다. 따라서 값이 무한히 커질 수 있다. 너무 커지면 한 번에 이동하는 step size가 매우 작아져서 학습이 잘 안될 수 있다. 그리고 convex하지 않은 loss function에서는 잘 작동하지 않는다.
RMSprop은 Adagrad가 무한히 커지는 것을 방지하고자 제안되었으며 지수 이동 평균을 사용했다. 다시말해, 최근 값을 더 잘 반영하기 위해 최근 값과 이전 값에 각각 가중치를 두어 계산하는 것이다.
 Adagrad에서는 그냥 이전값과 현재 gradient가 더해졌지만, RMSprop에서는 지수평균으로 더해진다.
Adagrad에서는 그냥 이전값과 현재 gradient가 더해졌지만, RMSprop에서는 지수평균으로 더해진다.
3. Adam optimizer
adam optimizer는 Adagrad와 RMSprop의 장점을 섞어놓은 것이라고 한다.
