cs231 Convolutional Neural Networks for Visual Recognition 에 나오는 소프트맥스 역전파 코드를 공부해봄
1. 데이터 셋 생성
import numpy as np
import matplotlib.pyplot as plt
N = 5 # number of points per class
D = 2 # dimensionality
K = 3 # number of classes
X = np.zeros((N*K,D)) # data matrix (each row = single example)
y = np.zeros(N*K, dtype='uint8') # class labels
for j in range(K):
ix = range(N*j,N*(j+1))
r = np.linspace(0.0,1,N) # radius (0.0 ~ 1의 시작 값과 끝 값을 갖는 N개의 원소를 가진 배열 생성)
t = np.linspace(j*4,(j+1)*4,N) + np.random.randn(N)*0.2 # theta
X[ix] = np.c_[r*np.sin(t), r*np.cos(t)]
y[ix] = j
# lets visualize the data:
plt.scatter(X[:, 0], X[:, 1], c=y, s=40, cmap=plt.cm.Spectral)
plt.show()
print(X)
print(y)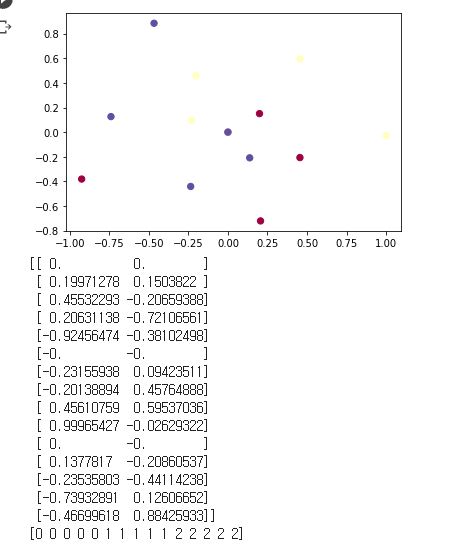
-
X : 데이터 (비선형성 데이터 생성. 15개 밖에 안돼서 나선형 데이터인게 잘 안보이지만 원글처럼 300개를 넣으면 나선형인 것을 알 수 있음)
-
y : 정답 (데이터가 0, 1, 2 어떤 클래스에 속하는지)
#Train a Linear Classifier
# initialize parameters randomly
W = 0.01 * np.random.randn(D,K) # 평균 0, 표준편차 0.01을 가지는 가우시안 분포를 가지는 랜덤 넘버
b = np.zeros((1,K))
# some hyperparameters
step_size = 1e-0
reg = 1e-3 # regularization strength
print(W)
print(b)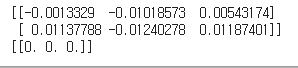
- W : 가중치
- b : 바이어스
2. 소프트맥스 분류기와 역전파
# gradient descent loop
num_examples = X.shape[0]
for i in range(200):
# evaluate class scores, [N x K] : 선형분류기(linear score function) - 클래스 스코어를 단일 행렬 곱셈의 병렬 계산
scores = np.dot(X, W) + b
if i == 0:
print(scores)
# compute the class probabilities : 각 클래스 별로 계산된 score이 정답일 확률이 담긴 배열(probs) 만들어짐.
# 정규화(합으로 나누는 과정)를 통해 각 행의 합은 1이 된다
exp_scores = np.exp(scores)
probs = exp_scores / np.sum(exp_scores, axis=1, keepdims=True) # [N x K]
if i == 0:
print(probs)
# compute the loss: average cross-entropy loss and regularization
correct_logprobs = -np.log(probs[range(num_examples),y])
data_loss = np.sum(correct_logprobs)/num_examples
reg_loss = 0.5*reg*np.sum(W*W)
loss = data_loss + reg_loss
if i % 10 == 0:
print("iteration %d: loss %f" % (i, loss))
# compute the gradient on scores
dscores = probs
dscores[range(num_examples),y] -= 1
dscores /= num_examples
# backpropate the gradient to the parameters (W,b)
dW = np.dot(X.T, dscores)
db = np.sum(dscores, axis=0, keepdims=True)
dW += reg*W # regularization gradient
# perform a parameter update : 미분값의 반대방향으로 업데이트
W += -step_size * dW
b += -step_size * db
if i == 0:
print(W)
print(b)
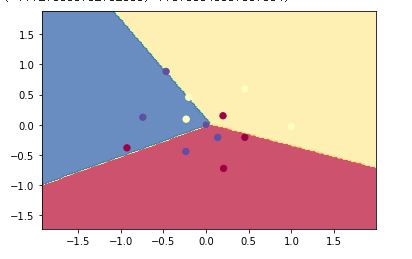
3. 학습
# initialize parameters randomly
h = 100 # size of hidden layer
W = 0.01 * np.random.randn(D,h)
b = np.zeros((1,h))
W2 = 0.01 * np.random.randn(h,K)
b2 = np.zeros((1,K))
# some hyperparameters
step_size = 1e-0
reg = 1e-3 # regularization strength
# gradient descent loop
num_examples = X.shape[0]
for i in range(10000):
# evaluate class scores, [N x K] : 위랑 다르게 추가된 부분
# 히든레이어 계산 후 이를 입력으로해서 다음 단계 (로스 계산, 그래디언트 계산 등) 진행
hidden_layer = np.maximum(0, np.dot(X, W) + b) # note, ReLU activation
scores = np.dot(hidden_layer, W2) + b2
# compute the class probabilities
exp_scores = np.exp(scores)
probs = exp_scores / np.sum(exp_scores, axis=1, keepdims=True) # [N x K]
# compute the loss: average cross-entropy loss and regularization
correct_logprobs = -np.log(probs[range(num_examples),y])
data_loss = np.sum(correct_logprobs)/num_examples
reg_loss = 0.5*reg*np.sum(W*W) + 0.5*reg*np.sum(W2*W2)
loss = data_loss + reg_loss
if i % 1000 == 0:
print("iteration %d: loss %f" % (i, loss))
# compute the gradient on scores
dscores = probs
dscores[range(num_examples),y] -= 1
dscores /= num_examples
# backpropate the gradient to the parameters
# first backprop into parameters W2 and b2
dW2 = np.dot(hidden_layer.T, dscores)
db2 = np.sum(dscores, axis=0, keepdims=True)
# next backprop into hidden layer
dhidden = np.dot(dscores, W2.T)
# backprop the ReLU non-linearity
dhidden[hidden_layer <= 0] = 0
# finally into W,b
dW = np.dot(X.T, dhidden)
db = np.sum(dhidden, axis=0, keepdims=True)
# add regularization gradient contribution
dW2 += reg * W2
dW += reg * W
# perform a parameter update
W += -step_size * dW
b += -step_size * db
W2 += -step_size * dW2
b2 += -step_size * db2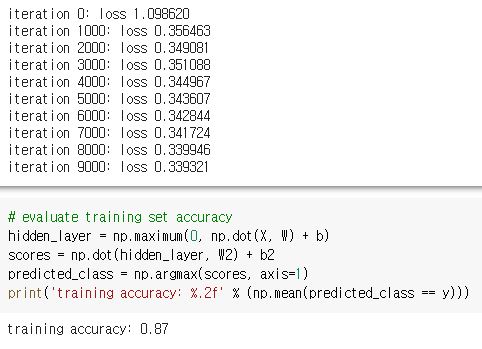

^^~