- kafka에 관심이 생겨, 몇몇 강의나, 여러내용을 봤지만, 모르는 용어들이 들려, 아무리 들어도 이해가 가지않는 상황이 있었다.
- 즉, 기초가 부족하다는 것이었다.
- 그래서 kafka를 이해하기 위한 기초를 쌓아보자고 한다.
Kafka 기본 개념
- 카프카는 메시지를 생산하는 Producer와 소비하는 Consumer , 그리고 그 사이에서 메시지를 저장, 전달하는 Broker(브로커)로 구성 된다.

- 카프카를 통해 흘러가는 메시지에 대해 알아보고, 카프카의 요소인 토픽과 파티션에 대해 알아보자

카프카 메시지
- 카프카의 메시지는 Key(키)와 Value(값)로 구성된다.
- Key값
- 먼저, 메시지의 키는 해당 메시지가 카프카 브로커 내부에 저장될 때, 저장되는 위치와 관련된 요소이다.
- Producer가 메시지를 브로커로 전달할때, 프로듀서 내부의 Partitioner(파티셔너)가 저장위치를 결정하는데, 이때 키의 값을 이용하여 연산하고 그 결과에 따라 저장되는 위치를 결정한다.

-
Value 값
- 전달하고자 하는 내용물
- 값은 단순한 문자열이 될 수도 있고, JSON이나 특정 객체가 될 수 있다.
- 이렇게 다양한 타입의 값으로 보낼 수 있는 것은 Broker를 통해 메시지가 발행되거나 소비될 때, 메시지전체가 직렬화/역직렬화되기 때문이다.
-
카프카 메시지의 키와 값은 다양한 타입이 될 수 있지만, 특정한 구조인 스키마(Schma)를 가진다.
- 데이터베이스의 테이블 스키마와 유사한 개념이다.
- 스키마는 연관된 테이블을 그룹핑하는 일종의 디렉토리 같은 거다.
- 스키마는 그룹에 속한 테이블들을 설명ㅋ
- 예를 들어, Producer가 JSON형태인 메시지를 발행할때, 해당 메시지를 소비하는 Consumer는 Producer가 생성한 JSON구조를 예상하고, 그에 맞게 메시지를 처리해야한다.
- 이때, Producer와 Consumer가 메시지에 대한 서로 다른 스키마를 가지고 있다면, 정상적인 처리가 불가능 하다.
- 데이터베이스의 테이블 스키마와 유사한 개념이다.
-
이처럼, 스키마는 카프카 개발, 운영에서 굉장히 중요한 역할을 담당한다.
카프카 토픽
- 카프카의 토픽(Topic)은 메시지를 구분하는 논리적인 단위
- 동일한 토픽의 메시지들은 논리적으로 같은 문맥(context)을 가진다.
- 예를 들어, 주문에 관한 내용을 담고 있는 메시지를 발행하고, 소비하기 위해선 우리는 order라는 토픽을 생성하고 이 토픽을 기준으로 메시지를 발행, 소비 할 수 있다.
- 이처럼 토픽은 논리적인 단위이자 메시지 흐름의 단위이다.
카프카 파티션
- 논리적인 단위인 카프카 토픽을 기준으로 발행되는 메시지들은 브로커 내부의 물리적인 단위인 카프카 파티션(Partition)으로 나뉜다.
- 즉, 모든 토픽은 각각 대응하는 하나 이상의 파티션이 브로커에 구성되고, 발행되는 토픽 메시지들은 파티션들에 나뉘어 저장된다.
- 이렇게 하나의 토픽에 대하여 여러 파티션을 구성하는 가장 큰 이유는 분산 처리를 통한 성능 향상에 있다.

- 위 그림은 T0토픽에 파티션 4개, T1토픽 파티션2개로 구성되었다. 이 경우 최소 총 6개의 파티션을 보유하고 있다는 말이다. 마치 서울톨게이트에 서울은 토픽이고, 하이패스 및 현금계산은 파티션이라 비유할 수 있다.
- 카프카는 하나의 파티션만으로도 충분한 성능을 발휘할 수 있지만, 일반적으로 2개 이상의 파티션을 서로 다른 브로커에 병렬 구성하여 요청의 부하를 분산시켜 준다.
- 파티션의 가장 큰 특징은 하나의 파티션은 메시지 순서가 보장된다는 것이다.
- 파티션 내에서는 순서가 보장되지만, 토픽전체에서는 순서가 보장되지않는다.
- 톨게이트를 비유하자면, 하이패스든 현금계산이든 줄지어 계산을 하기때문에 순서가 보장되지만, 톨게이트를 통과하는 전체를 두고 이야기하면 순서가 보장되지 않는다.
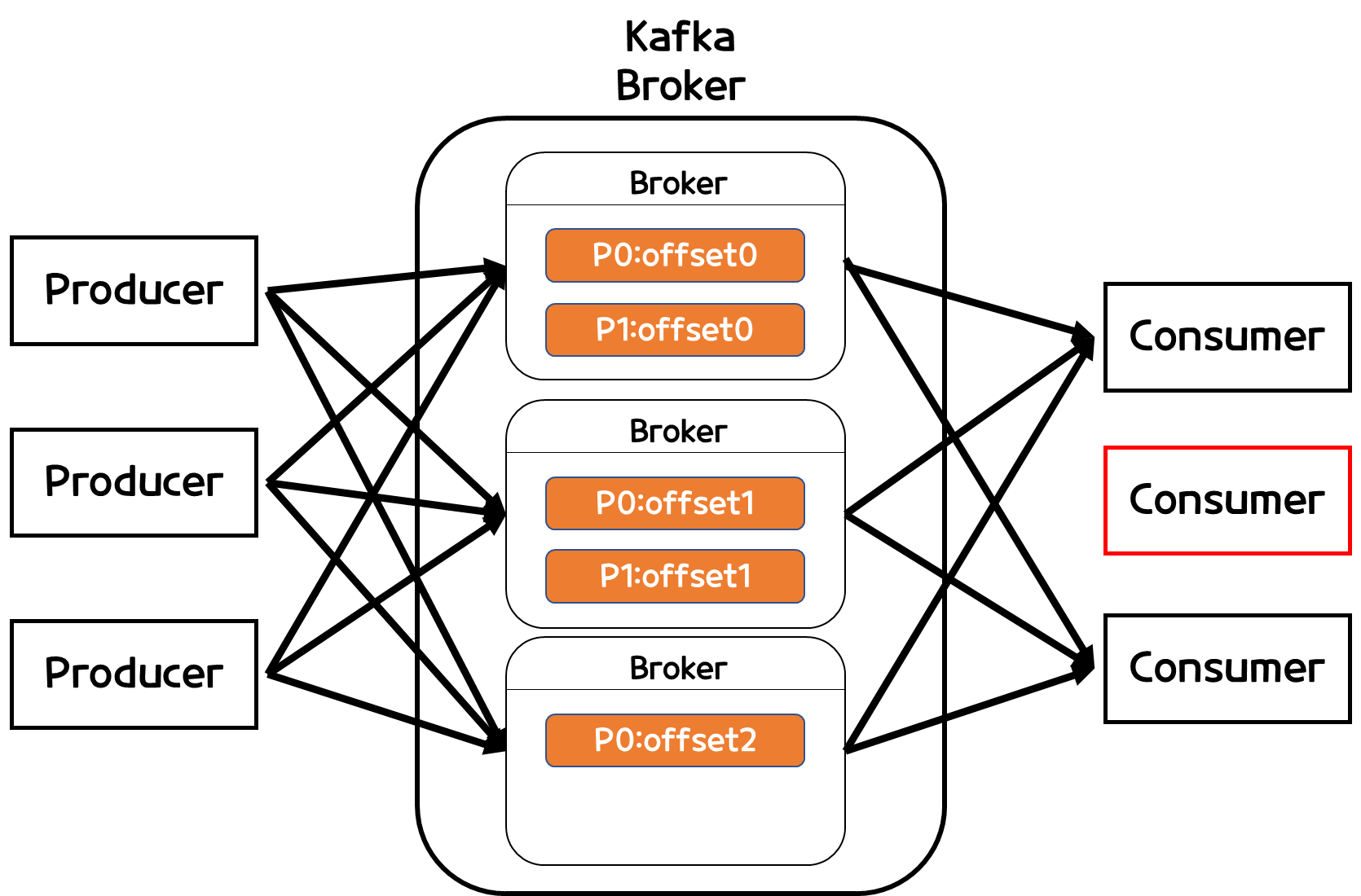
- 또 다른 특징으로는 파티션과 컨슈머의 관계인데, 파티션 개수보다 컨슈머 갯수가 많으면 효율이 좋지않다.
- 위 예시는 파티션2개와 컨슈머3개이다.
- 파티션개수에 따라 컨슈머가 할당받아 작업을 진행하게되는데, 이때 파티션개수 < 컨슈머개수 이면 남은 컨슈머는 할당 받을 때까지 무한정 대기하는 상태가 되어버린다.
파티션 복제
- 카프카는 서비스 안정성과 장애 수용에 관한 요소로 파티션의 복제(Replica) 기능을 제공한다.
- 하나의 파티션은 1개의 리더 레플리카와 그외 0개 이상의 팔로어 레플리카로 구성된다.
- 리더 레플리카
- 파티션의 모든 쓰기, 읽기 작업 담장
- 팔로어 레플리카
- 리더 레플리카로 쓰인 메시지를 그대로 복제
- 리더 레플리카가 장애발생하면, 리더 자리를 승계받을 준비
- 리더 레플리카
- 이렇게 리더 레플리카와 동기화된 레플리카들의 그룹을 ISR(In-Sync Replica)라고 한다.
- 파티션의 레플리카 수는 복제계수(Replication factor)를 통해 결정된다.
- 복제 계수가 1이라면 파티션은 리더 레플리카로만 구성
- 복제 계수가 2라면 파티션은 리더 레플리카 1개, 팔로우 레플리카 1개 로 구성
- 이 경우 모든 레플리카들은 서로 다른 블로커에 구성된다.
- 브로커는 카프카 클러스터 내에서 돌아가는 애플리케이션으로 장애 발생시, 데이터 유실이 발생할 수 있으므로, 다른 애플리케이션에서 구성하여, 언제 발생할 지 모르는 장애에 대비하여 데이터 유실을 방지하고 지속적인 서비스를 제공하기 위해 쓰인다.

한단계씩 올라가는 개발자

설명을 잘 하시네요!
카프카에 대해 두루뭉실하게 알던 개념들이 머릿속에서 정리되었습니다!