On Disk Structure
- 전원이 꺼질 때에도 HDD 혹은 SSD에 저장
- NTFS, UFS(유닉스) 기본적으로 달라지는 것은 없다
- 하드디스크의 부트로더와 파티션 테이블이 존재하는 부분은 MBR과 GPT.
- BIOS는 MBR에, UEFI 는 GPT에
- 파티션이 여러개 존재 할 수 있는데, 운영체제가 존재하는 것 ACTIVE Partition이다.
- 윈도우즈 ntfs도 비슷하지만 사용하는 의미만 조금씩 다르다.
- 운영체제는 4kb 단위로 디스크 블럭을 나눔.
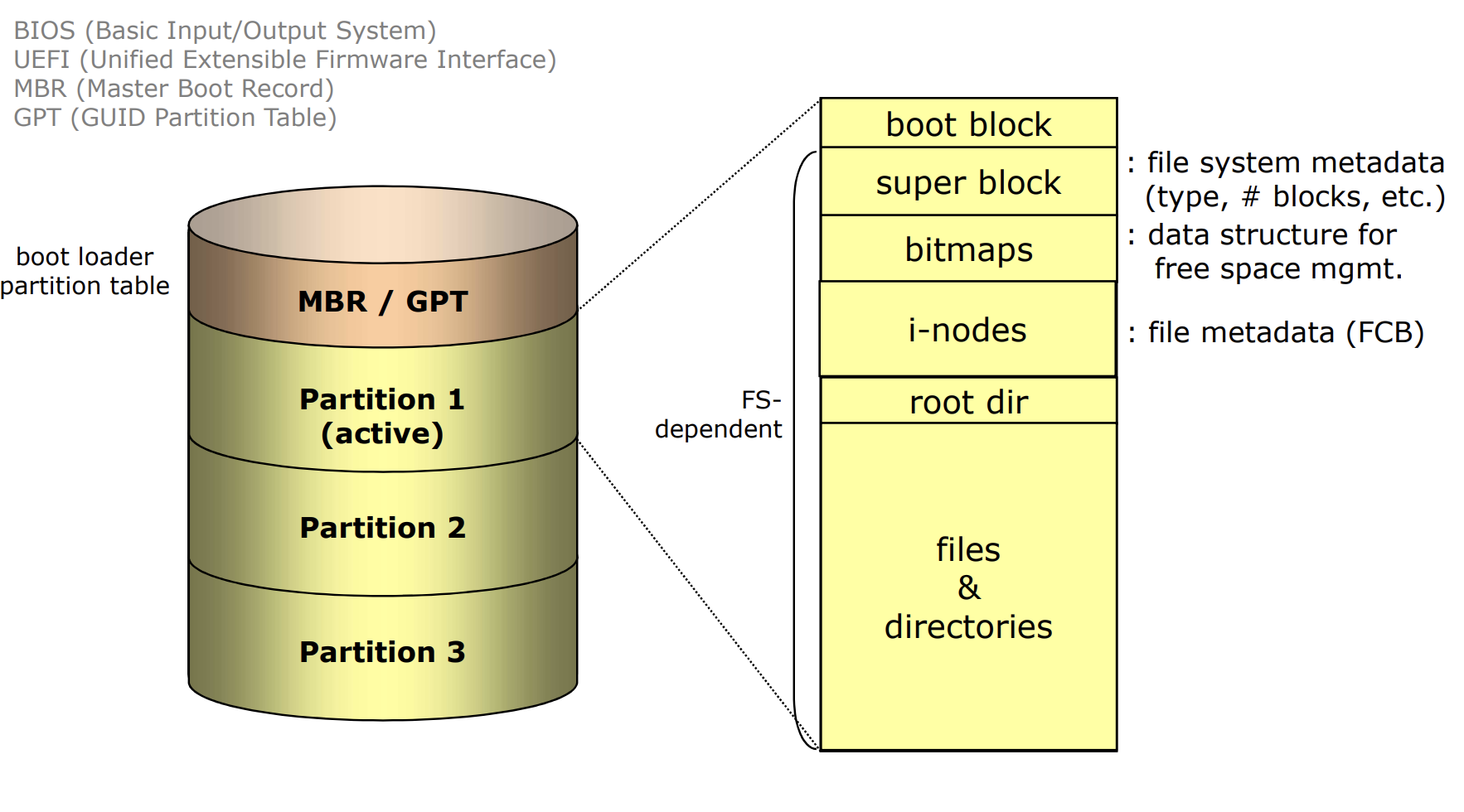
그림은 UFS의 예시임
- boot block
- 윈도우즈, 리눅스 커널 등
- 부팅 관련 정보
- super block : file system 관련 metadata
- type : 내 파일 시스템의 타입?
- 리눅스 : est2/3/4
- 윈도우즈 : ntfs
- 디스크 블럭의 개수
- type : 내 파일 시스템의 타입?
- bit maps
- 디스크 블럭이 사용 중이다 / 아니다
- 디스크 블럭 한 개당 한 비트로 표현 가능
free space management- 디스크 블럭 개수 ⇒ 비트맵 블럭 몇 바이트가 필요한 지 계산 가능.
- i-nodes
- 파일의 metadata
FCB: 유닉스와 리눅스에는 file control block을 i-nodes라 한다.- 파일이 생길 때마다 하나씩 생김.
- root dir : 처음 생성되는 디렉토리
- files & directories
- regular file : file contents
- directory : 파일 여러 개를 하나의 묶음으로
디렉토리
디렉토리 데이터 ? ⇒ 디렉토리 내에 어떤 파일들이 있는지 정보를 저장
디렉토리 내에는,
- file이름과 file control block 다 같이 저장
- file 이름과 i-node가 있는 위치 정보를 저장한다. (유닉스, 리눅스)
- hybrid approach
- 2에서처럼 둘 다 저장하되, 몇 개의 중요한 정보는 별도로 저장한다.
- 윈도우즈
하드디스크에 디스크 블럭을 어떻게 배치할 것인가?
file size 40kb
디스크 블럭 10개 필요
10개가 어디에 어떻게 표현되고 저장되어 있는지 관리 ⇒ file control block
⇒ file control block에 데이터가 어디에 저장 되어 있는지 표시해야 함.
⇒ 결론적으로, 하드디스크에 디스크 블럭을 어떻게 배치할 것인가에 따라 다를 수 있음.
-
Contiguous allocation: 연속적 배치- 장점 : 쉽다. start length에 의해서 판단 가능
- 단점 : file의 크기가 커지면 연속적으로 비어있는 공간이 많은 곳으로 옮겨야 함. 잘 사용 X file의 크기가 커졌다 작아졌다 하는 file에는 적합하지 않다.
- 읽기 전용 file 일 때 사용 . CD-ROM
-
Linked allocation: 불연속적 배치- 시작 위치만 저장. 써 있는 대로 쫓아감
- 장점 : file 작아졌다 커졌다 가능, 표시하기 쉽다
- 단점 : 가장 중요한 단점 . 오류가 나서 하나가 손실이 되면 쫓아갈 수 없게됨. reliability 측면에서 문제. 처음부터 끝까지 다 읽어야 함.
- 보완 =⇒
File-Allocation Table (FAT)- 포인터들을 별도의 테이블 file allocation table으로, 만들자
- 단점 : 아직은 unreliable함. 테이블 날아가면… ⇒ 이중 삼중으로 관리하지만, 신뢰도에는 단점
- 장점 : random access 유리.
-
Indexed Allocation
- 디스크 블럭에, 어디어디에 있다라는 것을 다 저장.
- i node는 index-node임
- index table 운영
- 이 파일이 어디에 있다는 정보.
- 장점 : 신뢰도가 좋아진다. random access 좋음(direct access 가능)
- 단점 : 그럼 mp3의 경우 1000개를 다 저장해야 하는가? ⇒ 어떻게 저장하지?
- direct block(직접 씀)의 개수는 12개까지 …. ⇒ 48KB만큼
- single indirect block
- 1K X 4KB = 4MB
- double indirect block
- 4MB x 1K = 4GB
- triple indirect : 4TB
block size와 data rate, disk space utilization
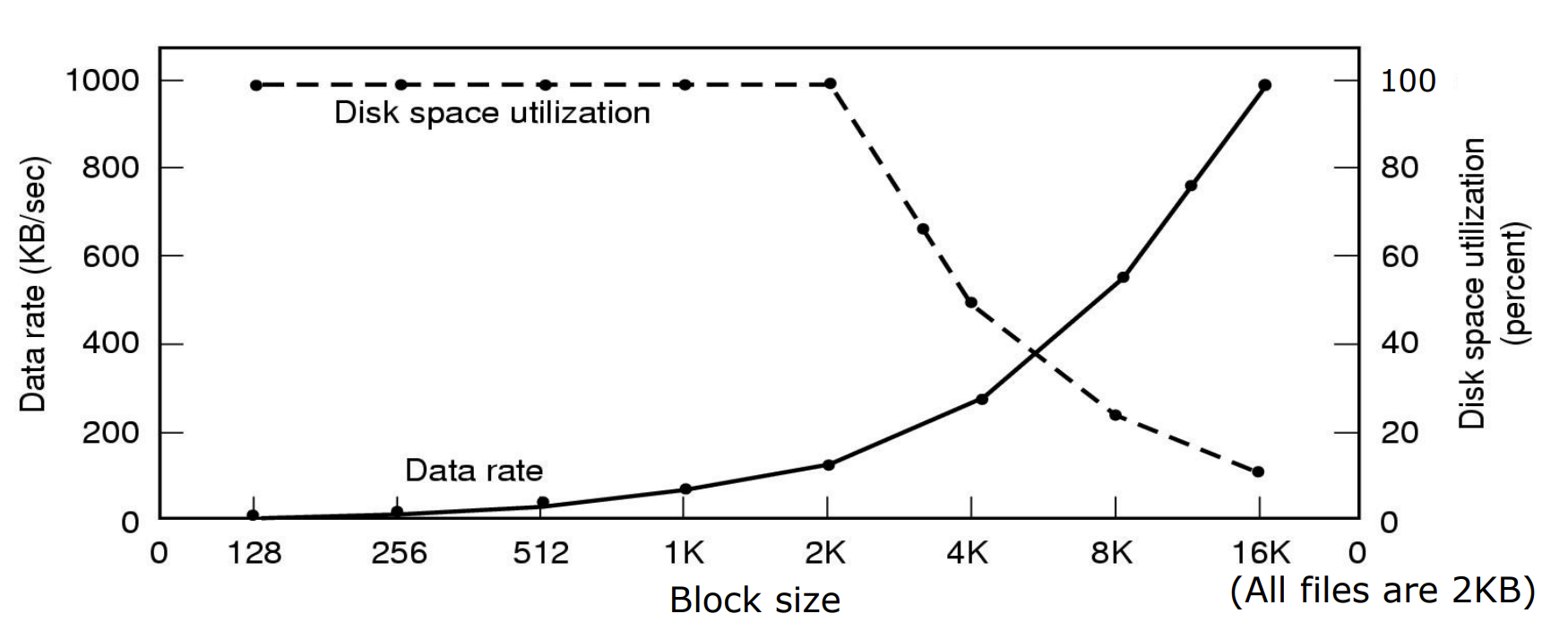
block size가 커지면 디스크가 한 번에 읽을 수 있는 데이터의 양이 많아지므로, data rate 향상.
(디스크는 최대한 많이 안 움직이는 것이 좋다.)
반면, block size가 커지면 internal fragment가 발생해 space utilization 측면에서는 좋지 않다.
Buffer cache
: 하드 디스크에서 가져와, 메인메모리에 cache로 두는 것.
- 성능 향상
- but , 메모리와 하드디스크의 동기화 문제가 발생함.
- Buffer cache : file 데이터를 저장하는 캐시
- directory cache : 디렉토리 데이터를 저장하는 캐시
- write .
- synchronous 문제. buffer cache에 쓰다가, 나중에 한거번에 write back 하는 방식은 속도가 나쁘지 않지만(write-through에 비해), 램은 휘발성이기 때문에
unreliable- 해결 1. 복구 (ex. fsck , scandisk) 데이터를 복구하는 게 아니라 상태를 원래대로 돌림
- 해결 2. log structured file systems. =
journaling- 디스크에 쓰기 전, journal에 썼다가 디스크에 쓰면 clear.
- booting 했을 때, journal에 남아있다면 디스크에 쓰지 못한 것이므로, 이에 따라 파일 시스템을 처리함
- asynchronous ⇒ write through 동시에 씀
- synchronous 문제. buffer cache에 쓰다가, 나중에 한거번에 write back 하는 방식은 속도가 나쁘지 않지만(write-through에 비해), 램은 휘발성이기 때문에
경희대학교 운영체제 조진성 교수님 수업 강의 필기

암냠냠