Process와 Thread
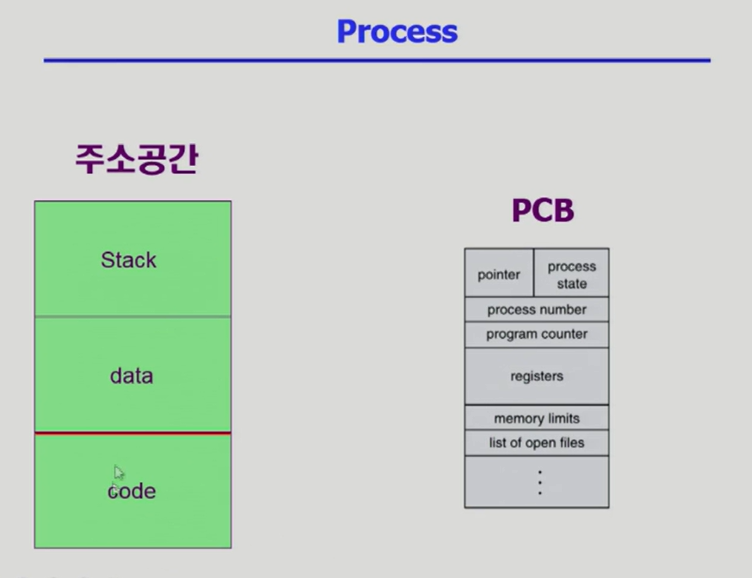
- 좌측의 프로세스 이미지는 메모리의 주소공간과 커널 내의 해당 프로세스에 대한 PCB를 가리킴
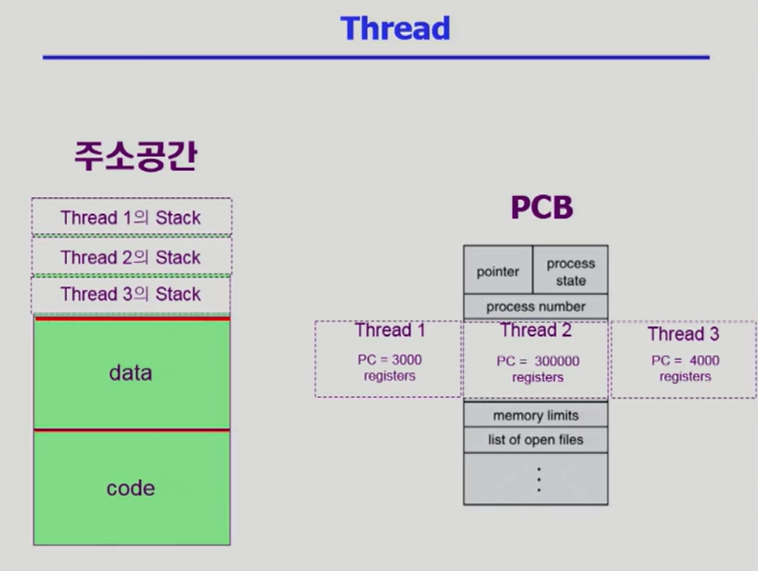
- Thread는 하나의 프로세스 안에서 data와 code 영역을 공유하나 stack영역은 별도로 지님
- 또한 PCB 내에서는 각각의 PC와 register를 가지고 있음
- 즉 한 프로세스 내에서 공유할 수 있는 것들은 공유하고 별개로 가져야 하는 것은 별개로 갖는다.
 |  |
|---|
- 웹브라우저를 여러개 띄울 때 각각의 프로세스로 관리하는 것보다 스레드로 관리하면 효율적, 각 창에 실행하고 있는 것은 달라도 공유하는 코드나 데이터는 같으니까
Q. CODE, DATA, STACK 확실히 구분 해봐, 스레드에서 각각의 영역은 어떻게 동작해 그럼? 참고
Q.스레드가 data 영역을 공유할 때 전역변수나 static변수나 값의 변경이 일어날 수 있는데 그럼 스레드 간 CPU 할당이 바뀌면서 각 스레드의 실행결과에 영향을 줄 수 있지 않아?

Q. 왜 스레드를 사용하는 게 더 효율적임?, 문맥교환이 안 일어나서? 문맥교환이 그렇게 오버헤드가 커? 왜?, 스레드 간 CPU 할당이 바뀌는 건 오버헤드가 없어 그럼?
- 프로세스를 만드는 것과 CPU를 switching하는 작업이 스레드를 만드는 것과 스레드 내에서 switching 하는 것에 비해 Solaris의 경우 오버헤드가 각각 30배, 5배라고 함. 이미 메모리에 올려진 프로세스 내 스레드를 만드는 것은 stack과 PCB 내 CPU 관련 정보만 바꾸면 되지만 새로 프로세스를 만들면 모든 것을 다시 만들어야 하고, switching 할 때 확인하고 저장해야 할 정보도 훨씬 많기 때문인듯.

Thread
-
"A thread (or lightweight process) is a basic unit of CPU utilization"
-
Thread의 구성
- program counter
- register set
- stack space
-
Thread가 동료 thread와 공유하는 부분(= task)
- code section
- data section
- OS resources
-
전통적인 개념의 heavyweight process는 하나의 thread를 가지고 있는 task로 볼 수 있다
-
Thread의 효율성 예시: 웹브라우저에서 창을 띄울 때 HTML 코드를 가져왔는데, HTML 코드 안에 IMG URL이 있어서 또 서버로 요청하여 네트워크 응답을 기다리면, 그동안 화면에 아무것도 안 띄워져있을 경우 답답한데, 다른 Thread를 실행시켜서 화면을 띄우게 하면 빨리 처리가 가능하다.
Q.그럼 SPA가 멀티 스레드로 구성된건가..? 한 프로그램 내 여러 스레드가 있을 때 이 스레드는 작업별로 구분이 가능한건가? 아님 아주 작은 기능 단위로도 스레드가 구별가능한건가 뭐지..
- 비동기식 입출력도 사실은 Thread 환경에서 효과적으로 동작 가능,
그럼 프로세스로도 스레드로도 비동기는 구현 가능하지만 스레드가 효율적이다? 근데 실제로는 SPA는 멀티스레드가 아닌데 왜 그런거야?
Thread의 장점
- 다중 스레드로 구성된 태스크 구조에서 하나의 서버 스레드가 blocked 상태인 동안에도 동일한 태스크 내의 다른 스레드가 실행되어 빠른 처리 가능
- 동일한 일을 수행하는 다중 스레드가 협력하여 높은 처리율과 성능 향상을 얻을 수 있음
- 스레드를 사용하면 병렬성을 높일 수 있음
- 병렬 프로그래밍: 행렬 곱셈을 할 때 CPU가 하나 밖에 없으면 한 행 한 열씩 순차적으로 연산해야 함, 여러 CPU나 여러 CORE가 있으면 행렬 곱셈같이 독립적으로 수행 가능한 연산의 경우 동시에 수행하도록 한 후 결과를 합치는 방식으로 빠르게 작업을 마무리할 수 있음

Thread의 구현
-
커널 수준의 스레드: 운영체제가 스레드의 존재를 아는 경우 커널 수준의 스레드 운영이 가능함, 스레드를 프로세스처럼 간주하고 처리, 큐에 넣거나 CPU를 할당하는 등의 관리를 할 때 스레드 단위를 이용
-
사용자 수준의 스레드: 사용자 수준의 스레드는 운영체제는 하나의 프로세스를 실행시키는 것이지 안에 스레드가 나뉘어 있는 것을 모르나 사용자의 코드 상 구현으로 스레드가 운용될 때, 예를 들어 비동기식 입출력과 같이 하나의 스레드가 작업을 진행하다가 I/O를 요청하면 CPU를 넘기는 것이 아니라 다른 스레드를 실행하도록 구현

Q. 사용자 수준의 스레드를 운용할 때 그럼 커널이 갖고 있는 각 스레드의 PC나 register 정보는 어떻게 읽어와? 스레드 간 문맥교환할 때 이 정보가 필요하지 않아? 프로세스 내에 PC나 register 정보를 같이 가지고 있나?
