패치 조인의 컬렉션 조회
-
컬렉션 (1대N 관계에서) Fetch Join은 뻥튀기 조회를 함
"select t From Team t join fetch t.members where t.name = "팀A"; -
아래 그림에서 보면 팀A에 속한 멤버들(Collection)을 조회하기 위해 위 구문을 날리면 같은 팀A가 회원수만큼 조회됨.
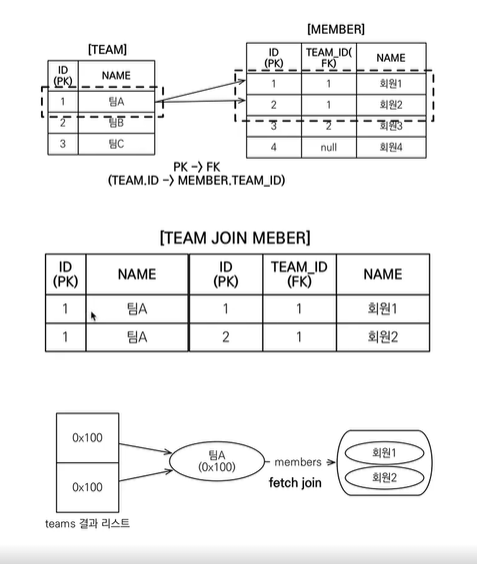
-
JPQL의 distinct 사용하여 팀 A 결과값의 중복을 제거할 수 있음
-
이 방식을 사용하면 SQL에 distinct를 추가하여도 팀A-회원1, 팀A-회원2로 DB에서 조회결과가 만들어져 distinct를 통한 중복 제거가 적용 되지 않기 때문에 어플리케이션에서 중복 제거를 진행함: 같은 식별자를 가진 Team 엔티티 제거
-
N대1 관계에서는 문제 X
페치 조인과 일반 조인의 차이
-
일반조인은 JOIN은 하지만 연관 엔티티를 조회는 하지 않음
-
패치 조인을 사용할 때만 연관된 엔티티도 함께 조회(즉시로딩처럼 동작)
-
패치 조인은 객체 그래프를 SQL 한 방 쿼리로 모두 조회해 오는 개념
-
1대N 관계에서 일반 조인 역시 뻥튀기는 발생
패치 조인의 특징과 한계
- 패치 조인 대상에는 별칭을 줄 수 없다.(가능은 하지만 가급적 사용 X)
- 별칭을 주면 .을 통한 경로 탐색으로 해당 엔티티에 대한 조건을 부여할 수 있다.
- 그런데 패치 조인은 연관된 객체를 다 끌고 온다.
- 여기서 JPA의 설계 사상 자체가 객체 그래프 탐색을 하면 관련된 데이터를 모두 가져오도록 하는 것이다.
- 즉 DB 데이터 자체를 객체에 전부 이관하는 느낌이다.
- 이 의도를 위해 만들어진 패치 조인을 통해 연관 엔티티를 모두 끌고 오는데 조인 대상에 별칭을 주어 조건을 걸어 일부 데이터를 제외하고 끌고 오는 등의 시도를 하게 되면 DB의 데이터를 모두 가지고 있어야 하는 설계 의도와 불일치가 발생한다.
- 예를 들어 1대N 관계에서 아래 쿼리를 실행하면 전체 Team과 연관된 멤버 중 일부만 가져오게 된다. 문제는 조건을 걸지 않고 가져온 Team 객체와 아래 jpql을 통해 가져온 같은 PK의 Team 객체가 있다면 JPA는 뭐가 맞는 데이터인지 확인하지 않는다는 것이다. 데이터의 정합성을 보장하는 매커니즘이 존재하지 않는다. 제거하고 조회한 객체로 인해 Casecade 속성으로 일부 데이터가 삭제될 수도 있고 어떻게 동작할지 모른다. 따라서 사용하지 않는 것이 좋다.
"select t from Team t join fetch t.members m where m.age > 10"
- 둘 이상의 컬렉션을 패치조인 할 수 없다.
-
Team에 Members, Orders 두 컬렉션이 있다고 했을 때 둘 다 조인을 하면 데이터가 카타시안곱처럼 뻥튀기가 엄청나게 일어난 쿼리가 나갈 수 있고, 데이터 정합성도 보장하지 못한다.
- 컬렉션을 패치 조인하면 페이징 API(setFirstResult, setMaxResults)를 사용할 수 없다.
-
일대일, 다대일 같은 단일 값 연관 필드들은 패치 조인해도 페이징 가능
-
하지만 일대다 관계의 연관 필드들은 데이터 뻥튀기가 발생하고 이 과정에서 페이징이 의도와 다르게 동작함.
- 아래 그림에서 NAME이 팀A인 팀 엔티티를 패치조인하여 가져오면 팀A - 회원1, 팀A - 회원2 두 객체를 가지고 페이징에서 다른 엔티티로 처리함.
-
예를 들어 아래 코드처럼 페이징 처리를 하여 페이지 0번에 1개 데이터를 불러온다면? 팀A 엔티티의 Members 필드에 회원 1만 가지고 있는 엔티티가 조회됨.

-
원래 페이징의 의도는 팀A의 모든 회원이 탐긴 팀1을 가져오는 것임. 만약 모든 팀 데이터를 페이징으로 불러온다고 하면 1pg - 팀A(팀A의 모든 회원), 2pg - 팀B(팀 B의 모든 회원).... 이런식으로 조회해야 함.
-
하지만 이렇게 동작하지 않음. 조인의 결과 테이블에 팀A - 회원1, 팀A 회원-2 두 ROW가 발생하기 때문에 이걸 가지고 페이징 처리해버림.(페이징이라는 건 철저하게 DB 중심이기 때문에, JPA 객체 그래프로 끌고와서 팀 단위로 끊어버리는 게 아니라 그림의 [TEAM JOIN MEMBER] 결과를 가지고 처리해 버리기 때문임!)
-
나아가 더 심각한 문제는 관계형 DB에서의 페이징으로 동작하지 않기 때문에 메모리로 데이터를 전부 조회해와서 페이징 처리를 진행함.
- 즉 팀 테이블에서 팀A, 팀B .. 로 페이지를 자를 수가 없음. 팀에 연관된 멤버들을 다 물고와야 하기 때문에.
- 그래서 우선 팀 데이터 전체를 멤버 테이블과 조인해서 가져온 다음에 메모리에서 앞서 말한 방식대로 페이지를 자름.
- 페이징 처리도 제대로 동작하지 않는데다가, 조인 테이블을 전부 가져온다? 팀 데이터가 100만개면 100만개 데이터를 모두 가져와서 어플리케이션 서버의 메모리에 올린 다음 처리함.
- OOM(Out Of Memory) 발생할 것임.(매우 위험)
-
해결책?
-
1대다의 엔티티를 조회하는 것이 아니라 다대1의 관점으로 뒤집어서 페이징 처리(위 사례에서 팀을 조회하는 것이 아니라 멤버를 조회한다)
-
패치 조인을 제거하고 그냥 조회한 후에 지연로딩으로 연관 엔티티를 조회하기 위해 DB에 다시 접근, But 이는 N+1 문제 발생시킴. 즉 전체 Team 데이터를 조회하고, 각 팀의 멤버 필드를 조회하는 시점에 멤버들을 끌고 오기 위해 각 팀 ID를 가지고 팀 개수인 N번 만큼 DB에 접근해서 조회함.
-
이를 해결하기 위해 Batch Size를 설정하면 최적화가 가능함.
-
연관 필드에 @BatchSize를 설정하거나 글로벌 설정을 통해 fetch의 batch size를 결정하면 지연로딩했던 필드를 조회하는 시점에 쿼리를 날릴 때 in query를 통해 현재 접근한 팀의 멤버 뿐만 아니라 페이징에 필요한 다른 팀의 멤버들도 함께 조회해서 초기화를 해줌.
-
위 예시를 통해 보자면 아래 코드를 수행할 때 0페이지에 팀 2개를 조회해 오고 해당 팀의 멤버 필드에 접근할 때 최대 batch size만큼 멤버들을 모두 한 번에 조회해와서 초기화 해줌
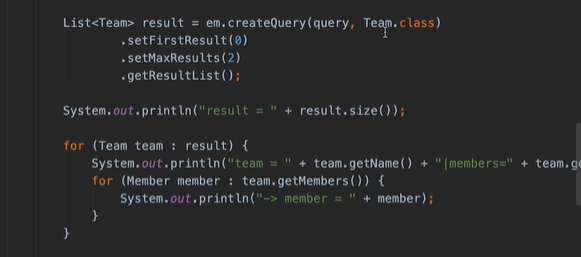
-
반복문에서 첫 팀의 멤버들에 접근할 때 아래의 쿼리가 나가서 다른 팀의 멤버들도 최대 100개 in query에 포함시켜 조회해옴
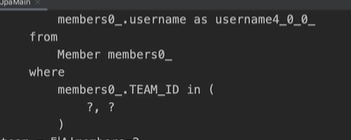
- 따라서 N+1의 N번 DB 접근을 Batch size를 통해 확연히 줄일 수 있음

출처: 자바 ORM 표준 JPA 프로그래밍 - 패치조인 1,2
