FCFS(First Come First Served)
- 선착순
- 먼저 queue에 도착한 프로세스부터 순차적으로 실행
- 도착 순서에 따라서 average waiting time이 큰 차이를 보임: 짧은 프로세스들이 먼저 도착해서 끝나면 waiting time이 작지만, 그 반대라면 waiting time이 길어짐.
- convoy effect: 하나의 긴 burst time을 가지는 프로세스가 먼저 실행되어 다른 프로세스들이 오랫동안 기다리게 되는 것
- 스케줄링 오버헤드가 작다.
SJF(Shortest Job First)
- burst time이 짧은 프로세스 먼저 CPU를 할당
- preemptive 방식: 더 짧은 수행시간을 가진 프로세스가 들어오면 running 중인 프로세스를 중단하고 그 프로세스에게 CPU를 할당(Shortest Remaing Time First: SRTF)
- nonpreemptive 방식: 이미 running 상태에 있으면 정해진 burst time만큼은 보장
- SJF is optimal: minimum average wating time을 보장함(SRTF), SJF도 다른 스케줄링 방식보다 average wating time 작음.
 |  |
|---|
- 문제점: CPU의 burst time을 예측하기 힘들다. 사용자의 입력값, 조건문에 의한 분기 등에 따라서 CPU 수행시간은 달라질 수 있다. Shortest burst time을 어떻게 알 수 있을까?
ㅇ다음 CPU Burst Time의 예측
- 추정(estimate)만이 가능하다.
- 과거의 CPU burst time을 이용해서 추정(exponential averaging)
- n+1번 실행했을 때 프로세스의 예측치 = axn번 째의 실제 burst time + (1-a)xn번째 실행 당시의 예측치
- 알파의 범위에 따라 알파를 적절하게 조정하여 실제 값과 예측치의 가중치를 부여(예측치 0.3이면 실제에는 0.7)
- 위 점화식을 풀어내면 오래된 실제 CPU 사용 값일 수록 더 적게 반영하는 식이 완성됨.


Priority Scheduling
- 우선순위를 부여하여 높은 우선순위를 지닌 Process부터 처리
- 우선순위 조건 값이 작을 수록 우선순위가 높다.
- SJF는 일종의 priority scheduling이다. prioiry 값을 predicted next CPU burst time으로 부여.
- 비선점 / 선점형 방식 존재(우선순위가 높은 프로세스가 들어오면 CPU를 빼앗음)
- starvation 문제가 발생할 수 있다. 즉 우선순위가 낮은 프로세스가 지속해서 그보다 우선순위가 높은 프로세스가 queue에 들어올 때 CPU 할당을 받지 못하는 경우가 발생할 수 있다.
- 이를 방지하기 위해 aging 기법을 사용할 수 있다. 일정 시간이 지나면 우선순위를 높이는 방식.
Round Robin
- 보장된 일정 시간만큼 CPU를 사용하고 반납하는 방식
- 각 프로세스는 동일한 크기의 할당시간(time quantum)을 가짐
- 할당 시간이 지나면 프로세스는 선점(preempted)당하고 ready queue의 제일 뒤에 가서 다시 줄을 선다.
- n개의 프로세스가 ready queue에 있고 할당 시간이 q time unit인 경우 각 프로세스는 최대 q time unit 단위로 CPU 시간의 1/N을 얻는다. ⇒ 어떤 프로세스도 (N-1) time unit 이상 기다리지 않는다.
- Performance
- q가 매우 크면 FCFS 방식과 비슷하게 동작
- q가 매우 작으면 문맥교환이 잦아 오버헤드가 커진다.
- 일반적으로 SJF보다 average turnaround time이 길지만(수행을 끝내지 못 하고 계속 밀려 날 수 있으므로 최악의 경우 모든 프로세스가 아주 작은 필요 시간이 남을 때 까지 돌아가면서 실행되고 대기되는 것을 반복하면 마지막 순간에 거의 동시에 모든 프로세스가 종료되는 상황이 발생할 수 있음), response time은 더 짧다.(일정 시간 이후 바로 running 상태에 들어가는 것을 보장하므로 첫 응답을 빠를 수 있음)
Multi Level Queue
- Ready Queue를 하나가 아닌 여러 개 두고, 각 queue마다 우선순위를 달리하여 CPU 스케줄링 하는 방법
- foreground: interactive
- background: batch, no human interaction
- 사용자와 상호작용 하는 프로세스는 우선순위를 높게, CPU bound한 것들은 우선순위를 낮게 부여
- 각 큐는 독립적인 스케줄링 알고리즘을 가짐
- foreground: RR
- background: FCFS
- 큐에 대한 스케줄링이 필요할 수 있음
- Fixed priority scheduling
- 앞쪽 큐의 모든 프로세스를 처리해야만 다음 큐의 프로세스를 처리
- starvation 발생 가능성 존재
- Time slice
- 각 큐에 CPU time을 적절한 비율로 할당하여 starvation 방지
- Eg: 80% to foreground in RR, 20% to background in FCFS
- Fixed priority scheduling
Multi Level Feedback Queue
- 프로세스의 우선순위를 고정하지 않고, 일정 시간이 지나면 우선순위를 낮추거나 높이는 방식, 프로세스가 다른 큐로 이동 가능함
- Aging을 이와 같은 방식으로 구현 가능
- Multilevel-feedback-queue scheduler를 정의하는 파라미터들
- Queue의 수
- 각 큐의 scheduling algorithm
- Process를 상위 큐로 보내는 기준
- Process를 하위 큐로 내쫓는 기준
- 프로세스가 CPU 서비스를 받으려 할 때 들어갈 큐를 결정하는 기준
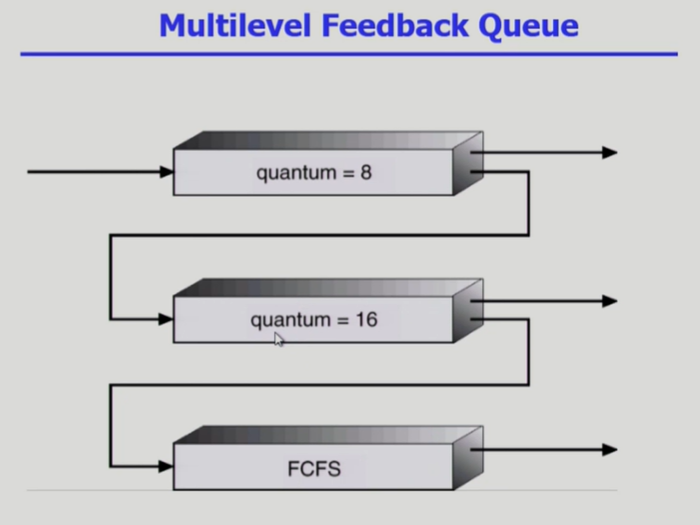
- 위와 같은 경우 우선 어떤 프로세스든 가장 위의 큐로 보내고, burst time이 길 수록 아래로 쫓겨나게 됨.
- 시간이 짧은 프로세스를 우선적으로 처리
- burst time 예측이 필요하지 않음.
특이한 경우의 스케줄링
Multi-Processor Scheduling
-
CPU가 여러 개인 경우
-
Homogenous processor인 경우
- Queue에 한줄로 세워서 각 프로세스가 알아서 꺼내가게 할 수 있음
- 혹은 반드시 특정 프로세스에서 수행되어야 하는 프로세스가 있는 경우에는 문제가 더 복잡해짐
-
Load sharing
- 일부 프로세서에 job이 몰리지 않도록 부하를 적절히 공유하는 메커니즘 필요
- 별개의 큐를 두는 방법 vs 공동 큐를 사용하는 방법
-
Symmetric Multiprocessing(SMP)
- 각 프로세서가 각자 알아서 스케줄링 결정
-
Asymmetric multiprocessing
- 하나의 프로세서가 시스템 데이터의 접근과 공유를 책임지고 나머지 프로세서는 거기에 따름
Real-Time Scheduling
- 데드라인이 보장되어야 하는 프로세스
- Time sharing 처럼 시간을 쪼개서 공유하는 시스템이 아니라, 미리 스케줄링하여 특정 작업이 정해진 시간 내에 끝낼 수 있도록 함
- 12시에 업데이트하는 DB scheduler가 있으면 이건 server에서 꼭 어떤 요청이 들어와도 우선순위를 주어 처리해야 함
Thread Scheduling
- Local Scheduling
- User level thread의 경우 사용자 수준으 ㅣthread library에 의해 어떤 thread를 스케줄할지 결정
- Global Scheduling
- Kernel level thread의 경우 일반 프로세스와 마찬가지로 커널의 단기 스케줄러가 어떤 thread를 스케줄할지 결정
Algorithm Evaluation
- Queueing models
- 이론적인 방법
- 확률 분포로 주어지는 arrival rate와 service rate 등을 통해 각종 performance index 값을 계산
- Implementation(구현) & Measurement(성능 측정)
- Linux 내부 프로세스 스케줄링 코드를 고치는 방법 등을 통해서 실제 시스템에 알고리즘을 구현하여 실제 작업에 대해서 성능을 측정함
- Simulation(모의 실험)
- 실제 알고리즘을 시스템상 구현하고 동작시키는 것은 쉽지 않음, 모의 프로그램을 작성하고 실제 프로그램이 돌아갔던 스케줄인 trace를 뽑아서 프로그램에 돌려보고 비교함

Hello World